python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from pyquery import PyQuery as pq
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome('D:/chromedriver.exe',options=options)
url="https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html"
driver.get(url)
html=driver.page_source
page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置
driver.execute_script('arguments[0].scrollIntoView();', page)
结果运行报错:
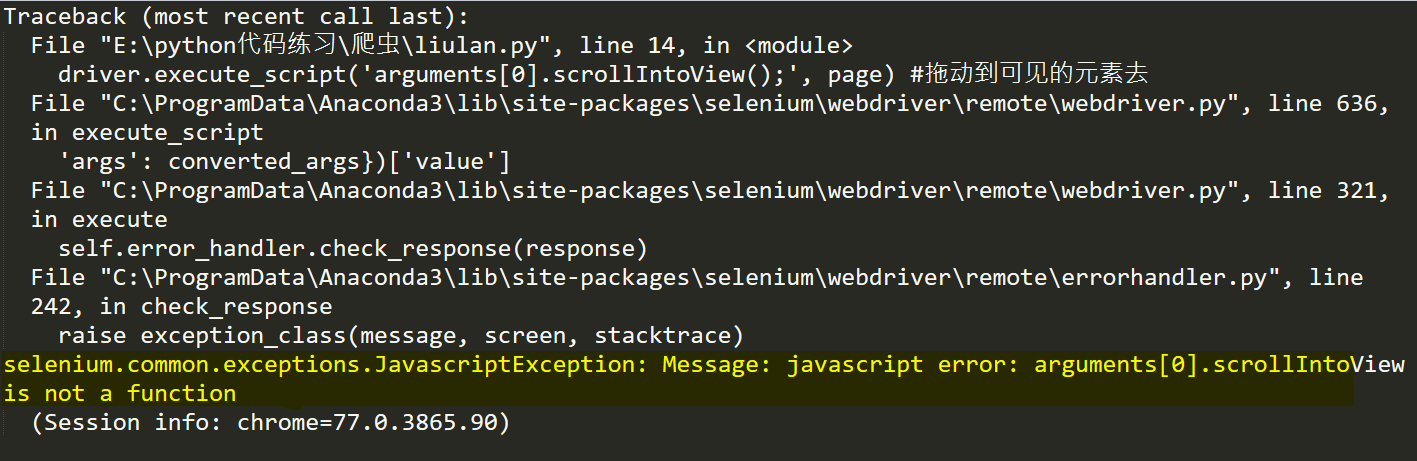
因为在百度文库页面底部需要点击“继续阅读”才可以加载到完整的页面,所以必须使用这两行代码
page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置
driver.execute_script('arguments[0].scrollIntoView();', page)
来将浏览器滚动到“继续阅读”这个位置,然后执行点击按钮。
但是却爆出了黄色部分的错误。找了好久,最后在stackoverflow上找到了答案,不得不说,stackoverflow还是强啊

这哥们说,
scrollIntoView()
这个函数是属于DOM API ,因此你应该使用一个web元素来调用它,而不是一个web元素列表来使用它。
这是我认识到,我可能定位的元素并不是一个,所以我又重新定位了一下元素,更改的代码如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html")
page = driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span/span[2]")
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后就可以自动的加载所有文档内容啦
python 利用selenium爬取百度文库的word文章的更多相关文章
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- 洛谷$P2168\ [NOI2015]$荷马史诗 贪心
正解:贪心 解题报告: 传送门$QwQ$ 昂这个就哈夫曼树板子题鸭$QwQ$,只是从二叉变成多叉了$QwQ$ 考虑用类似合并果子的方法?就从两个变成$k$个了嘛,一样的鸭,然后就做完了$QwQ$ 注意 ...
- $Loj10157$ 皇宫看守 树形$DP$
loj Description 有一些宫殿,它们呈树形结构,相邻的宫殿之间可以互相望见.在一些宫殿设立士兵,使得所有的宫殿都有士兵或是被士兵望见.求最小士兵数. Sol 状态: f[x][0] 表示结 ...
- CAP 3.0 版本发布通告
前言 大家好,我们很高兴宣布 CAP 发布了 3.0 版本正式版. 自从上次 CAP 2.6 版本发布 以来,已经过去了几个月的时间,关注的朋友可能知道,在这几个月的时间里,也发布了几个预览版的 3. ...
- ad域-iis
环境准备: 1. win server 服务器安装完成 2.配置主机名 3.配置静态ip 安装ad域和iis 重启服务器 密码记住!!! 点击安装 把服务器的NDS设置成本机ip 重启完成 注意:ad ...
- SpringCloudAlibaba通过jib插件打包发布到docker仓库
序言 在SpringBoot项目部署的时候,我了解到了Jib插件的强大,这个插件可以快速构建镜像发布到我们的镜像仓库当中去.于是我打算在毕设当中加上这个功能,并且整合到github actions中去 ...
- FTP服务器虚拟用户配置
FTP服务配置问题及解决方案 使用被动模式,设置云主机IP为被动模式数据传输地址:在配置文件内添加 pasv_enable=YES pasv_promiscuous=YES pasv_address= ...
- 删除centos自带的openjdk
[wj@master hadoop]$ rpm -qa | grep javajava-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64python-javapa ...
- socket、http、udp、tcp的整理
1.socket简介 游戏开发中最常用的便是socket,socket本质是api,是对tcp/ip的封装.tcp/ip协议族是一个网络通信模型以及一系列网络传输协议,为互联网的基础通信架构. tcp ...
- BFT-SMaRt:用Java做节点间的可靠信道
目录 一.引子 二.名词统一 1. 节点id 2. 节点 3. 本地节点 4. 配置域 5. TTP 6. 陌生域 三.节点服务类 四.节点通信系统概览 五.节点通信层准备 1. 创建socket服务 ...
- 案例分析丨谷歌设计冲刺 4 天决定 Clips 的功能特性
这次为大家带来Google冲刺日程案例,之前案例分析可以戳对应文字直达:ING集团.音乐流媒体Spotify.美国知名超市Target 作为一款工具类产品,谷歌十分注重产品候选人的技术背景,同时也看重 ...