python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html
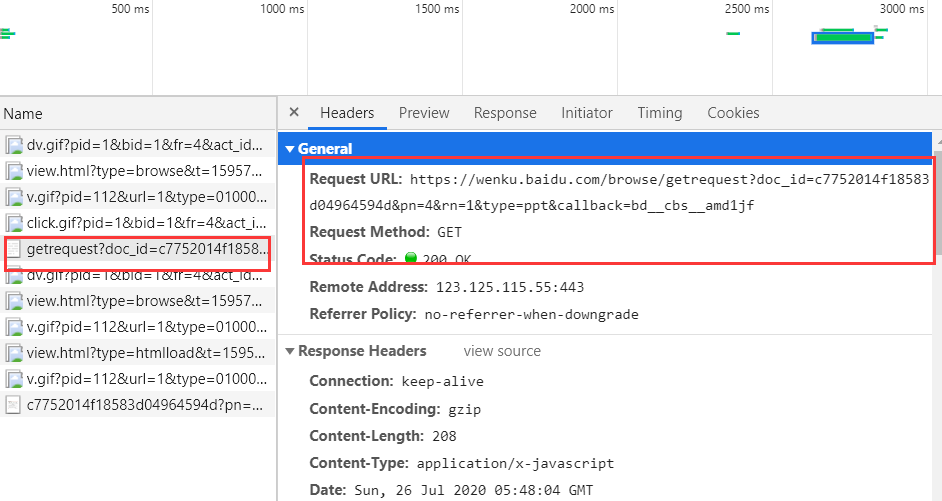
在下面这种类型文件中的请求头的url打开后会得到一个页面
你会得到如下图一样的页面

你将页面上zoom对应的值在一个新的网页打开之后会发现,这个就是ppt中的图片
你可以多打开几个“getrequest?doc_id”类型的请求头看一下它们的Request URL,你会发现我们只需要改变pn对应的数字就能得到文库中对应的PPT图片

知道了这个我们就可以先把图片url弄出来,然后再依次访问这些url,并下载至本地
要注意的是,如下面的url地址
https:\/\/wkretype.bdimg.com\/retype\/zoom\/c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
你如果复制之后粘贴在浏览器的地址框里面,浏览器会把这个地址转化成下面这个类型之后再去访问
https://wkretype.bdimg.com//retype//zoom//c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
所以在我们得到地址之后用一些函数处理一下就可以了
因为代码不太复杂,所以就不再详细叙述了
import requests class Spider:
def __init__(self):
#定义url前缀
self.url_pre = "https://wenku.baidu.com/browse/getrequest?doc_id=c7752014f18583d04964594d&pn="
#定义url后缀
self.url_suf = "&rn=1&type=ppt&callback=bd__cbs__sv0n59"
#请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
} def Create_url(self):
num = input('输入爬取ppt总页数:')
for i in range(1,int(num)+1):
#构建对应页数PPT的url地址
self.url = self.url_pre+str(i)+self.url_suf
#请求后得到页面源码
response = requests.get(self.url,headers=self.headers)
html = response.text
#因为我们需要从页面源码中拿到PPT中图片对应地址,所以可以通过字符串匹配等方式得到,这里我就用数组查找就行
#找出图片地址在源码中起始和终止位置
start = html.find(':"http') + 2
end = html.find('","')
#切割字符串
url_pic = html[start:end]
#将图片url字符串,转化为可访问的url地址
url_pic=url_pic.replace('\\','')
#print(url_pic)
self.request_pic(url_pic,i) def request_pic(self,url_pic,num):
#print(url_pic)
response = requests.get(url_pic, headers=self.headers)
num = str(num)+'.png'
with open(num,'wb') as f:
f.write(response.content) if __name__ == '__main__':
spider = Spider()
spider.Create_url()
python+requests爬取百度文库ppt的更多相关文章
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
随机推荐
- rm: cannot remove `/tmp/localhost-mysql_cacti_stats.txt': Operation not permitted
[root@DBslave tmp]# chown zabbix.zabbix /tmp/localhost-mysql_cacti_stats.txt
- Mybatis 一级缓存和二级缓存的使用
目录 Mybatis缓存 一级缓存 二级缓存 缓存原理 Mybatis缓存 官方文档:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html#cache My ...
- Python输出有颜色的文字
原创链接: https://www.cnblogs.com/easypython/p/9084426.html 我们在使用python运维与开发的过程中,经常需要打印显示各种信息.海量的信息堆砌在 ...
- k8s中教你快速写一条yaml文件
一条yaml中有很多字段,如果去背这些字段,其实也能背过,但是去写一条yaml,也往往浪费很多的时间,也会出错,其实我们可以用一条命令就能快速来写一段自定义的yaml,工作中去修改相应的yaml也得心 ...
- C# 中的动态类型
翻译自 Camilo Reyes 2018年10月15日的文章 <Working with the Dynamic Type in C#> [1] .NET 4 中引入了动态类型.动态对象 ...
- WTM5.0发布,全面支持.net5
WTM5.0是WTM框架开源2年以来最大的一次升级,全面支持.net5,大幅重构了底层代码,针对广大用户提出的封装过度,不够灵活,性能不高等问题进行了彻底的修改. 这次升级使WTM继续保持开箱即用,高 ...
- dubbo快速入门demo
参考文章 https://blog.csdn.net/abcwanglinyong/article/details/81906027 该demo包含三个项目,分别是: 服务提供端项目:provider ...
- 推荐几个学习Python的免费网站
想要学好Python,只靠看Python相关的书籍是远远不够的!今天为大家分享几个实用的Python学习网站. 欢迎各位热爱Python的小伙伴进群交流:610380249群里有大佬哦,而且很热心,群 ...
- jmeter-登录获取cookie后参数化,或手动添加cookie, 再进行并发测试
以下情况其实并不适用于直接登录可以获取cookie情况,直接可以登录成功,直接添加cookie管理,cookie可以直接使用用于以下请求操作. 如果登录一次后,后续许多操作,可以将cookie管理器放 ...
- HA工作机制及namenode向QJM写数据流程
HA工作机制 (配置HA高可用传送门:https://www.cnblogs.com/zhqin/p/11904317.html) HA:高可用(7*24小时不中断服务) 主要的HA是针对集群的mas ...