Pandas——数据处理对象
Pandas中的数据结构
Series: 一维数组,类似于Python中的基本数据结构list,区别是Series只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。就像数据库中的列数据;DataFrame: 二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器;Panel:三维的数组,可以理解为DataFrame的容器。
Series是一个一维的类似的数组对象,包含一个数组的数据(任何NumPy的数据类型)和一个与数组关联的数据标签,被叫做索引 。最简单的Series是由一个数组的数据构成:
from pandas import Series,DataFrame
import pandas as pd
a = Series([1,4,7,9])
print(a)
运行结果:

Series的交互式显示的字符串表示形式是索引在左边,值在右边。因为我们没有给数据指定索引,一个包含整数0到N-1(这里N是数据的长度)的默认索引被创建。你可以分别的通过它的values和index属性来获取 Series的数组表示和索引对象:
from pandas import Series,DataFrame
import pandas as pd
a = Series([1,4,7,9])
#print(a)
print(a.values)
print(a.index)
运行结果:

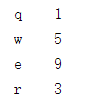
创建一个带有索引来确定每一个数据点的Series。
b = Series([1,5,9,3],index=['q','w','e','r'])
print(b)
运行结果:
字典类型转换成Series,Series中的索引是排列后的字典的键。
data = {'湖北':"武汉","四川":"成都","湖南":"长沙"}
c = Series(data)
print(c)
运行结果:

DataFrame是一个表格型的数据结构,是以一个或多个二维块存放的数据表格(层次化索引),DataFrame既有行索引还有列索引,它有一组有序的列,每列既可以是不同类型(数值、字符串、布尔型)的数据,或者可以看做由Series组成的字典。
DataFrame创建:
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = DataFrame(dictionary)
print(frame)
结果:

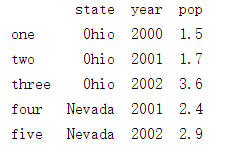
修改行名:
frame = DataFrame(dictionary,index=['one','two','three','four','five'])
结果:
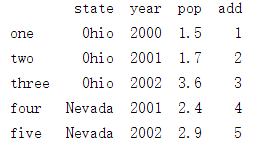
添加修改(等号左边是新加的列索引,右边是值,而且值的个数一定要和原来一样):
frame['add']=[1,2,3,4,5]
结果:
添加Series类型(Series中的索引名要和原来的相同):
frame=DataFrame(dictionary,index=['one','two','three','four','five'])
# value = Series([1,3,1,4,6],index = [0,1,2,3,4])(这种会出错)
# frame['add1'] = value
value = Series([1,3,1,4,6],index=['one','two','three','four','five'])
frame['add1'] = value
print(frame)
结果:

Pandas——数据处理对象的更多相关文章
- pandas.DataFrame对象解析
pandas.DataFrame对象类型解析 df = pd.DataFrame([[1,"2",3,4],[5,"6",7,8]],columns=[&quo ...
- python pandas 数据处理
pandas是基于numpy包扩展而来的,因而numpy的绝大多数方法在pandas中都能适用. pandas中我们要熟悉两个数据结构Series 和DataFrame Series是类似于数组的对象 ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- pandas数据处理
首先,数据加载 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,期中read_csv和read_table这两个使用最多. 1.删除重复元素 使用duplicated()函数 ...
- Pandas数据处理实战:福布斯全球上市企业排行榜数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用. 本文通过实例操作来介绍用pandas进行数据整理. 照例先说下我的运行环境,如下: w ...
- Pandas数据处理 学习
pandas是在numpy的基础上建立的新程序库,提供了一种高效的DataFrame数据结构. DataFrame本质上是一种带行标签和列标签.支持相同数据类型和缺失值的多维数组. 先看版本信息: p ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- pandas数据处理基础——筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 ...
- Python———pandas数据处理
pandas模块 更高级的数据分析工具基于NumPy构建包含Series和DataFrame两种数据结构,以及相应方法 调用方法:from pandas import Series, DataFra ...
随机推荐
- 【Python】摄氏度与华氏度互相转化
Python入门程序,大家可以举一反三,进行各种转换,比如单位转化,货币转化等等,自行发挥即可! 原理: 代码: Tempstr=input("请输入带有符号的温度值:\n")# ...
- 每天进步一点点------Xilinx FPGA开发工具 EDK SDK术语
XPS:Xilinx Platform Studio,平台工作室.用于嵌入式处理器硬件部分的开发. SDK:Software Development Kit,软件开发套件.基于Eclipse平台,支持 ...
- docker启动容器报错:iptables failed
问题描述: 启动Docker容器的时候 Error response / --dport -j DNAT --to-destination ! -i docker0: iptables: No cha ...
- [RedHat]“is not in the sudoers file”解决方法
当在终端执行sudo命令时,系统提示“luckchengis not in the sudoers file”: $ sudo ls Password: luckcheng is not in the ...
- Python代码混淆和加密技术
Python进行商业开发时, 需要有一定的安全意识, 为了不被轻易的逆向. 混淆和加密就有所必要了. 为了增加代码阅读的难度, 源代码的混淆非常必要, 一个在线的Python代码混淆网站. http: ...
- 【网易官方】极客战记(codecombat)攻略-地牢-祸之火焰
关卡连接: https://codecombat.163.com/play/level/banefire 绕着火焰跳舞,否则你的骨头下次就会被烧着 默认代码 # 食人魔看上去又大又慢,这是你的机会. ...
- (matlab)自定义图像(matlab)
clc;clear all;A=[0 230 255 60 30 100];A=uint8(A);imshow(A,'InitialMagnification','fit') 如图: clc;clea ...
- AcWing 851. spfa求最短路 边权可能为负数。 链表 队列
#include <cstring> #include <iostream> #include <algorithm> #include <queue> ...
- Codeforces Round #599 (Div. 2) C. Tile Painting
Ujan has been lazy lately, but now has decided to bring his yard to good shape. First, he decided to ...
- 2019新生赛 %%%xxh
笔记.md ...