Hadoop之伪分布式安装
一、Hadoop的安装模式有3种
①单机模式:不能使用HDFS,只能使用MapReduce,所以单击模式主要用于测试MR程序。
②伪分布式模式:用多个线程模拟真实多台服务器,即模拟真实的完全分布式环境。
③完全分布式模式:用多台机器(或启动多个虚拟机)来完成部署集群。
二、安装主要涉及的内容
①JDK
②配置主机名、hosts文件以及免密登录
③修改hadoop的配置文件,主要涉及以下几个配置文件(hadoop-2.7.7/etc/hadoop)
1)hadoop-env.sh:这里主要修改jdk的安装路径等
2)core-site.xml:主要指定namenode的地址和文件存放目录等
3)hdfs-site.xml:指定复本数量
4)mapred-site.xml:执行MR程序运行在yarn上
5)yarn-site.xml:指定NodeManager获取数据的方式和resourceManager的地址
6)slaves文件:伪分布式配置本主机名即可
④配置hadoop的环境变量和格式化namenode
三、搭建hadoop的伪分布式
①获取Hadoop的安装包
http://hadoop.apache.org/releases.html,注意:source为源码包,binary为安装包
我这里以2.7.7版本为例:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
解压Hadoop安装包:tar -xvf hadoop...
目录说明:
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop等命令都在这里
libexec目录:存放的也是hadoop命令,但一般不常用
最常用的就是bin和etc目录
②安装jdk
下载对应linux版本的tar.gz包:https://www.oracle.com/technetwork/java/javase/downloads/index.html
1)解压:tar -xvf jdk-8u131-linux-x64.tar.gz
2)配置环境变量:vim /etc/profile(修改完以后记得source使配置文件生效)
#java env
JAVA_HOME=/home/softwares/jdk1.8.0_131
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
export PATH=$PATH
3)通过:java,javac,java -version来查看jdk是否安装成功。
③关闭防火墙
1)service iptables stop 临时关闭
2)chkconfig iptables off 永久关闭
④配置主机名
vim /etc/sysconfig/network
修改完成以后重启!!!
NETWORKING=yes
HOSTNAME=hadoopalone
//hadoopalone 这是我修改的,表示是伪分布式
⑤配置hosts文件
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.144.133 hadoopalone //配置 ip和主机名映射
⑥配置免密登录
1)ssh-keygen,一路回车即可。
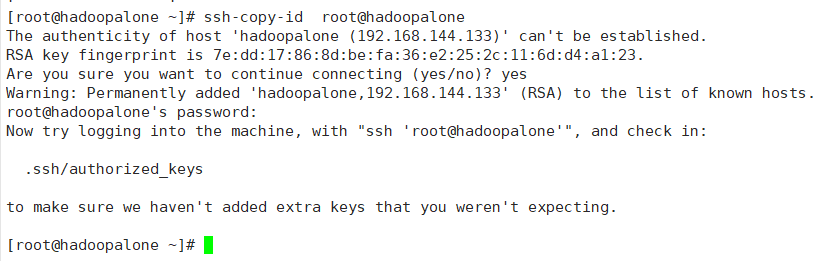
2)ssh-copy-id root@hadoopalone
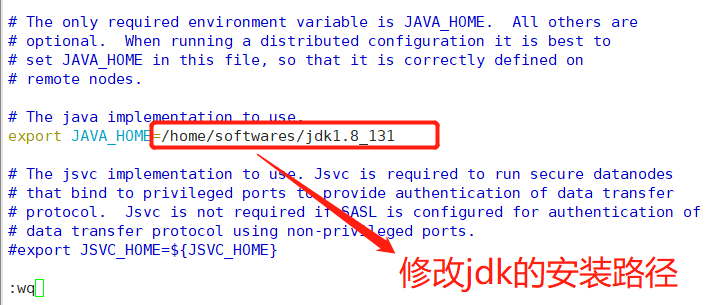
⑦Hadoop的配置--hadoop-env.sh
这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径
切换到 etc/hadoop目录
执行:vim hadoop-env.sh
修改java_home路径,如图所示,保存退出后,切记 source hadoop-env.sh使配置文件生效。
⑧Hadoop配置--core-site.xml

<configuration>
<!--用来指定hdfs的老大,namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopalone:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/softwares/hadoop-2.7.7/tmp</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
⑨Hadoop配置--hdfs-site.xml

<configuration>
<!--指定hdfs保存数据副本的数量,包括自己,默认值是3-->
<!--如果是伪分布模式,此值是1即可-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
⑩Hadoop配置--mapred-site.xml
默认是map-site.xml.template,拷贝并重命名为mapred-site.xml。

<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑪Hadoop配置--yarn-site.xml
,为防止图片失效,配置也粘贴出来。
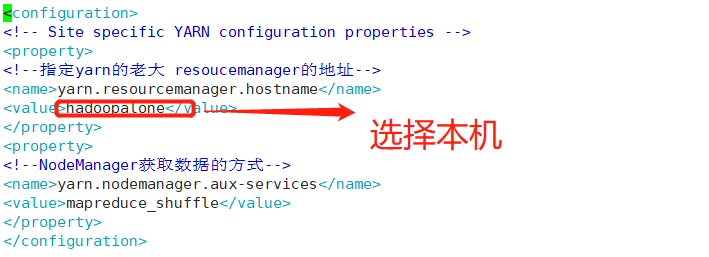
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--指定yarn的老大 resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoopalone</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
⑫配置slaves文件
同样在hadoop-2.7.7/etc/hadoop目录下
vim slaves

⑬配置Hadoop的环境变量
记得source /etc/profile
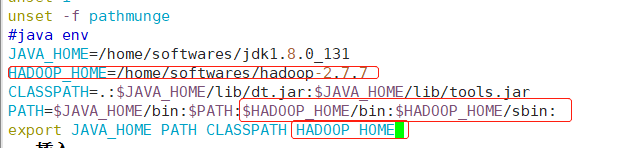
#java env
JAVA_HOME=/home/softwares/jdk1.8.0_131
HADOOP_HOME=/home/softwares/hadoop-2.7.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
export PATH=$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
⑭最后一步
格式化namenode
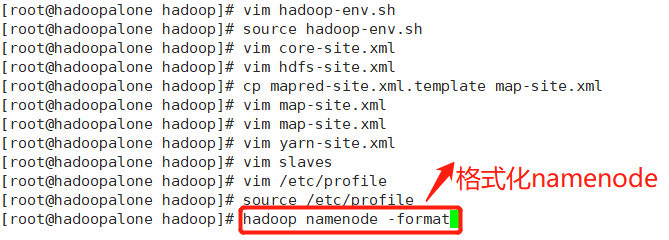
当出现以下中的关键语句表示格式化成功!
通过start-all.sh启动我们刚刚搭建的hadoop伪分布式模式:start-all.sh
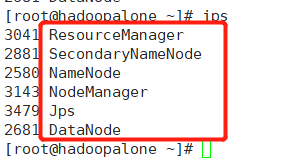
通过:jps命令来查看,出现以下进程说明我们的hadoop伪分布式搭建完成!!!
如果有什么问题,欢迎大家指正~~~~~我们一起讨论解决。
Hadoop之伪分布式安装的更多相关文章
- Hadoop开发第3期---Hadoop的伪分布式安装
一.准备工作 1. 远程连接工具的安装 PieTTY 是在PuTTY 基础上开发的,改进了Putty 的用户界面,提供了多语种支持.Putty 作为远程连接linux 的工具,支持SSH 和telne ...
- 【Hadoop】伪分布式安装
创建hadoop用户 创建用户命令: sudo useradd -m hadoop -s /bin/bash 创建好后需要更改hadoop用户的密码,命令如下: sudo passwd hadoop ...
- Hadoop的伪分布式安装和部署的流程
1.准备工作 下载一些用到的命令 yum install -y vim yum install -y lrzsz yum install net-tools 目录约定 /opt #工作目录 /opt/ ...
- 【hadoop】 hadoop 单机伪分布式安装
准备: 虚拟机(CentOS 6.9) JDK1.8 hadoop2.8.0 一.JDK安装及配置 rpm -ivh jdkxxxx 安装 配置环境变量 vim /etc/profile export ...
- Hadoop的伪分布式安装和部署流程
在opt目录创建install software test other四个目录 /opt/installed #安装包/opt/software #软件包/opt/other #其他/opt/test ...
- 伪分布式安装core-site.xml和hdfs-site.xml配置文件
hadoop的伪分布式安装流程如下所示: 其中core-site.xml和hdfs-site.xml是两个很重要的配置文件. core-site.xml <configuration> & ...
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
随机推荐
- leetcode 925. Long Pressed Name
判定是否长按 var isLongPressedName = function (name, typed) { var i = 1, j = 0, n = name.length, m = typed ...
- laravel路由组中namespace的的用法详解
做公司一个项目的时候发现laravel框架中可以省去action的路径前缀的用法: ps:用简短的话来理解就是说在路由组中定义namespace,可以省去你路由的前缀下面看例子 最终显示如下: 定义的 ...
- jenkins集成robot
一.jenkins集成robot的非gui的运行命令 pybot 配置文件 用例地址 或者robot 配置文件 用例地址 二.展示robot 运行结果图表 1.在系统配置中增加Rob ...
- jsonp实现js跨域请求
sonp是跨域通信的一个协议 具体来说jsonp实现跨域请求其实是使用js文件引用(js文件不一定是.js结尾)可跨域的性质,将请求的结果包裹在客户端需要调用的js方法内部.需要前后端配合使用. 前段 ...
- [C#] 委托与匿名方法
using System; namespace 匿名函数 { class Program { delegate void TestDelegate(string s); static void M(s ...
- 【转载】Java多线程
转自:http://www.jianshu.com/p/40d4c7aebd66 引 如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目 ...
- C语言程序设计100例之(27):回旋方阵
例27 回旋方阵 问题描述 编写程序,生成从内到外是连续的自然数排列的回旋方阵.例如,当n=3和n=4时的回旋方阵如下图1所示. 图1 由内到外回旋方阵 输入格式 一个正整数n(1≤n ...
- spring boot配置druid数据连接池
Druid是阿里巴巴开源项目中一个数据库连接池. Druid是一个jdbc组合,包含三个部分, 1.DruidDriver代理Driver,能够提供基于Filter-Chain模式得插件体系2.Dru ...
- HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER
这个问题可能是我第一个遇到吧,hadoop启动时WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USE ...
- the MTS failed last time时的解决办法
关于6.6.3SP2版本提示The MTS failed last time 1.1 发生前提条件 在重启系统 shutdown -r now后,网页打不开,发现MTS服务无法启动,我自己涉及的 ...