python获取某视频网站视频
还是老生常谈的操作
import requests
import os
from bs4 import BeautifulSoup
from urllib.parse import urljoin
html = requests.get('http://www.332dy.com/pu/37192-0-0.html')
soup = BeautifulSoup(html.text,'lxml')
lists = soup.select('.stui-content__playlist.sort-list.column8.clearfix li a')
for list in lists:
print(list['href'])
返回
/pu/37192-0-0.html
/pu/37192-0-1.html
/pu/37192-0-2.html
/pu/37192-0-3.html
/pu/37192-0-4.html
/pu/37192-0-5.html
/pu/37192-1-0.html
/pu/37192-1-1.html
/pu/37192-1-2.html
/pu/37192-1-3.html
/pu/37192-1-4.html
/pu/37192-1-5.html
拼接一下
import requests
import os
from bs4 import BeautifulSoup
from urllib.parse import urljoin
base_url = 'http://www.332dy.com/'
html = requests.get('http://www.332dy.com/pu/37192-0-0.html')
soup = BeautifulSoup(html.text,'lxml')
lists = soup.select('.stui-content__playlist.sort-list.column8.clearfix li a')
for list in lists:
innerurl = urljoin(base_url,list['href'])
print(innerurl)
然后我们就要下载这个视频,来抓下包
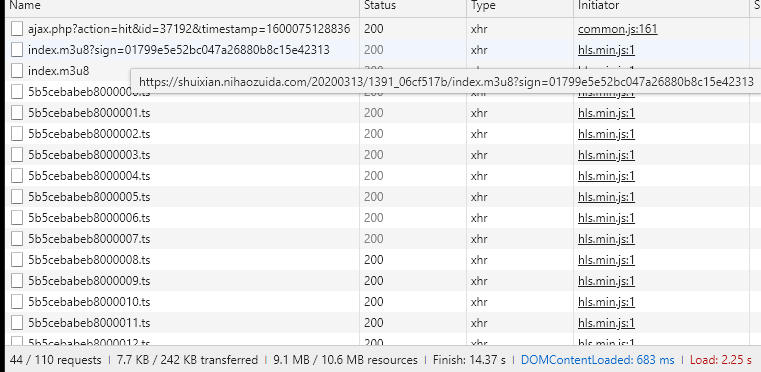
可以看到是个ts流,这个就是分段下载,一般ts流都有个m3u8
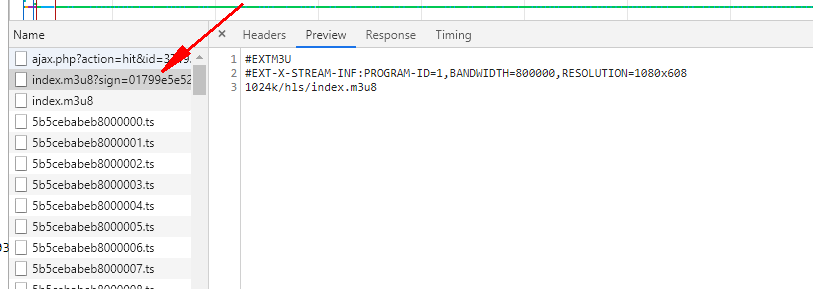
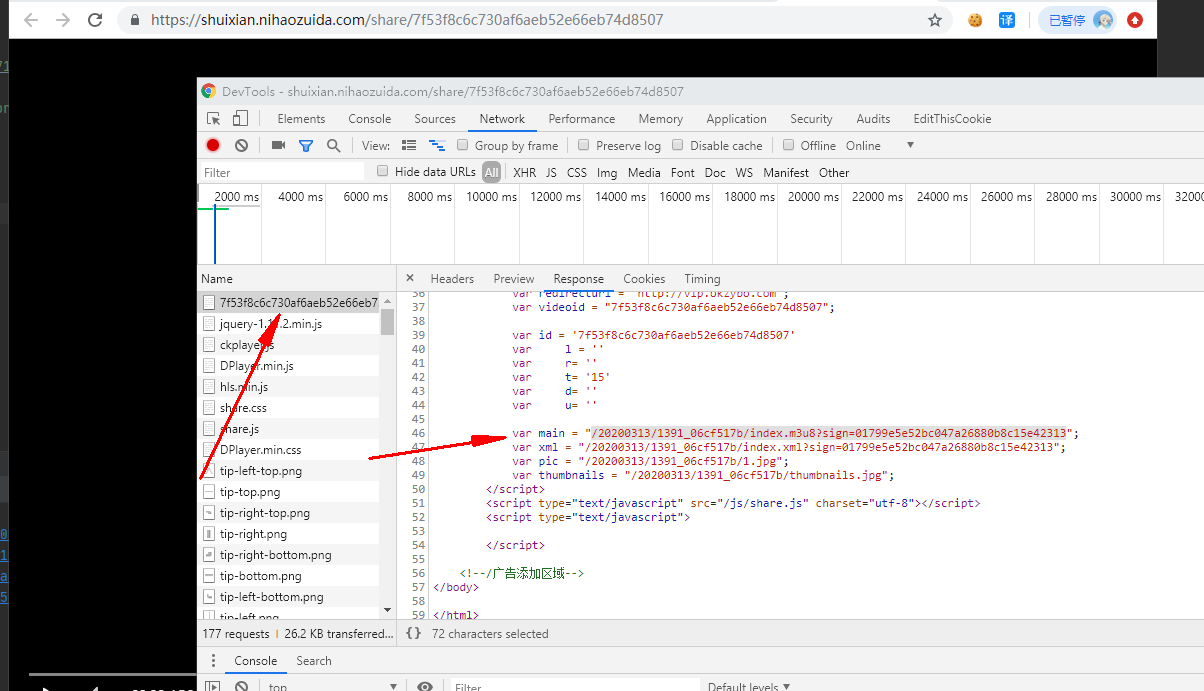
我们看头部可以知道有个sign
Request URL: https://shuixian.nihaozuida.com/20200313/1391_06cf517b/index.m3u8?sign=01799e5e52bc047a26880b8c15e42313
来全局搜索一下sign
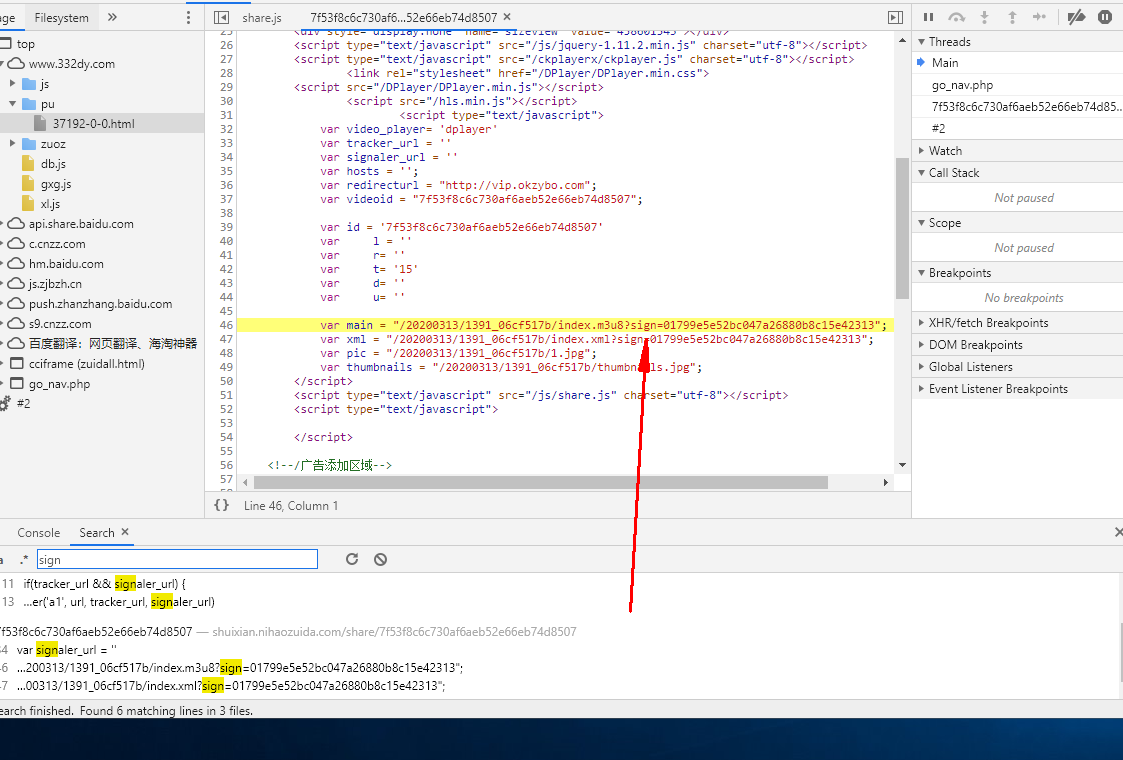
可以看到这个sign是从一个script脚本里面取的,把鼠标移到上面可以看到share我们去源代码全局搜索下share
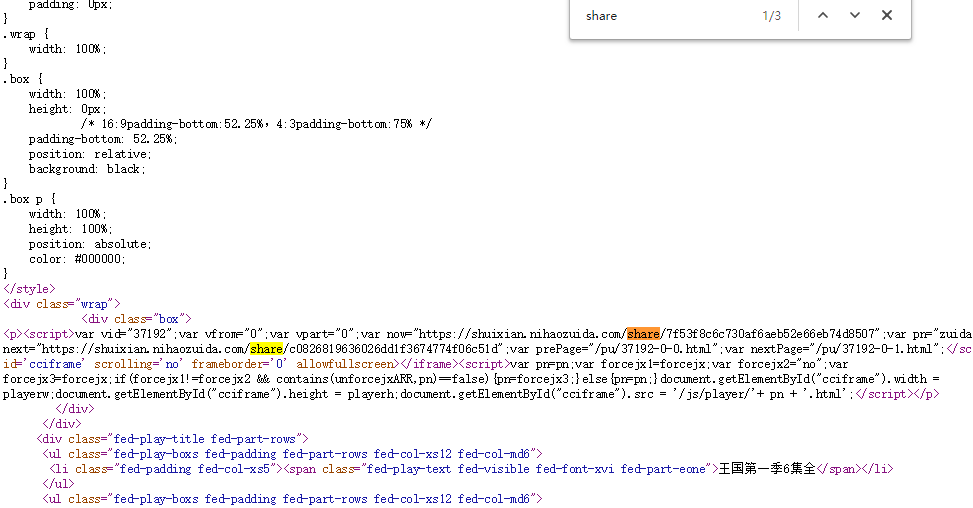
访问https://shuixian.nihaozuida.com/share/7f53f8c6c730af6aeb52e66eb74d8507可以看到是视频这个应该是
3u8文件,我们就取出var now=使用正则表达式因为script一般不在我们语法里面
re_m3u8 = re.compile('now="(.*?)"',re.I|re.S)
html2 = requests.get(innerurl)
m3u8Result = re_m3u8.findall(html2.text)[0]
print(m3u8Result)
成功获取到了,但是返回的为列表是4集我们获取第一个,所以加上[0]
我们访问一下抓包,可以看到访问了这个文件然后main里面我们访问就是下载的m3u8文件
同样正则获取一下里面的值
re_main = re.compile('main = "(.*?)"',re.I|re.S)
html3 = requests.get(m3u8Result)
mainResult = re_main.findall(html3.text)[0]
print(mainResult)
同样取出要拼接
baseurl = 'https://shuixian.nihaozuida.com/'
resultUrl = urljoin(baseurl,mainResult)
print(resultUrl)
然后我们把这个m3u8文件保存一下
if not os.path.exists('影视'):
os.mkdir('影视')
with open('影视/m3u81.txt','w',encoding='utf-8')as f:
f.write(requests.get(resultUrl).text)
print('m3u8存储完毕')
然后再读取出来
with open('影视/m3u81.txt', 'r', encoding='utf-8')as f:
lines = f.readlines()
for line in lines:
if line.startswith('#'):
continue
print(line)
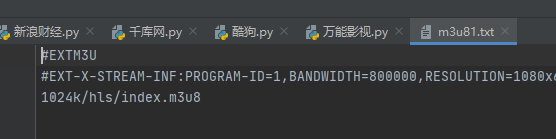
输出
1024k/hls/index.m3u8
再拼接起来
现在获取到的就是里面很多ts流,同样保存起来
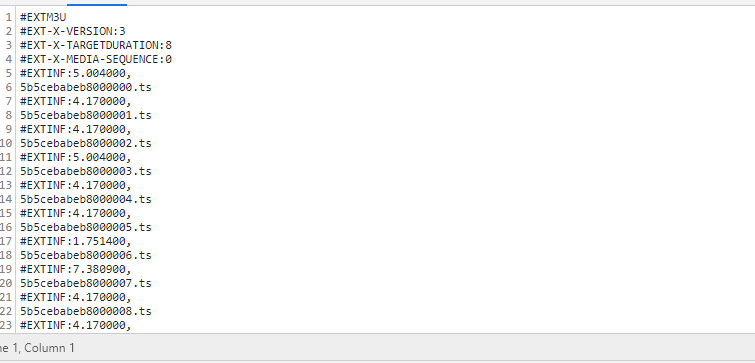
with open('影视/m3u82.txt', 'w', encoding='utf-8')as f:
f.write(requests.get(url).text)
print('m3u8存储完毕')
with open('影视/m3u82.txt', 'r', encoding='utf-8')as f:
lines = f.readlines()
for line in lines:
if line.startswith('#'):
continue
print(line)
输出
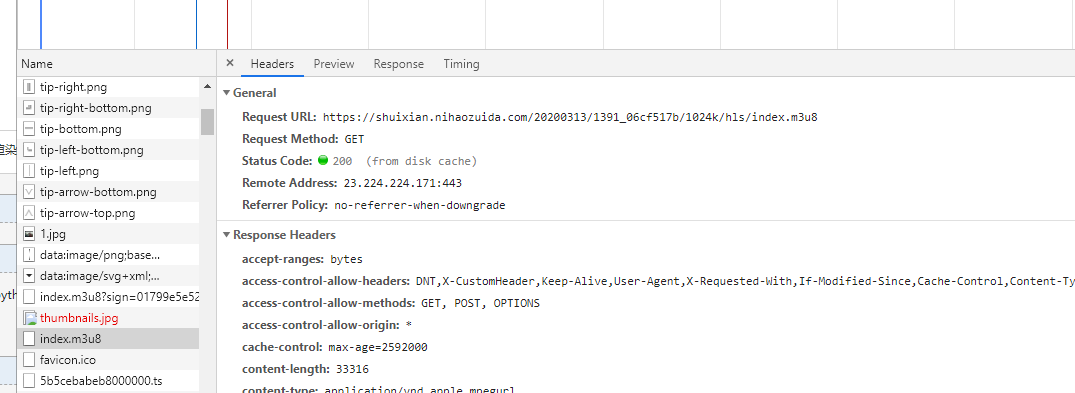
但是现在还不能用这个ts我们看一下他本地怎么发包的
Request URL: https://shuixian.nihaozuida.com/20200313/1391_06cf517b/1024k/hls/5b5cebabeb8000002.ts
base = 'https://shuixian.nihaozuida.com/20200313/1391_06cf517b/1024k/hls/'
url = urljoin(base,line.strip().replace('\n',''))
print(url)
然后就是下载这些ts流,最终代码为
import requests
import os
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
re_m3u8 = re.compile('now="(.*?)"',re.I|re.S)
re_main = re.compile('main = "(.*?)"',re.I|re.S)
html = requests.get('http://www.332dy.com/dili/37192.html')
soup = BeautifulSoup(html.text,'lxml')
lis = soup.select('ul.stui-content__playlist.sort-list.column8.clearfix li a')
base = 'http://www.332dy.com/'
for li in lis:
innerUrl = urljoin(base,li['href'])
# print(innerUrl)
html2 = requests.get(innerUrl)
m3u8Result = re_m3u8.findall(html2.text)
# print(m3u8Result)
if m3u8Result==[]:
base = 'http://www.332dy.com'
innerUrl = urljoin(base, li['href'])
html2 = requests.get(innerUrl)
m3u8Result = re_m3u8.findall(html2.text)
html3 = requests.get(m3u8Result[0])
mainResult = re_main.findall(html3.text)[0]
baseurl = 'https://shuixian.nihaozuida.com/'
resultUrl = urljoin(baseurl,mainResult)
if not os.path.exists('影视'):
os.mkdir('影视')
with open('影视/m3u81.txt','w',encoding='utf-8')as f:
f.write(requests.get(resultUrl).text)
print('m3u8存储完毕')
with open('影视/m3u81.txt', 'r', encoding='utf-8')as f:
lines = f.readlines()
for line in lines:
if line.startswith('#'):
continue
# print(line)
#https://shuixian.nihaozuida.com/20200313/1391_06cf517b/1024k/hls/index.m3u8
#1024k/hls/index.m3u8
basem3u8 = 'https://shuixian.nihaozuida.com/20200313/1391_06cf517b/'
url = urljoin(basem3u8,line)
break
with open('影视/m3u82.txt', 'w', encoding='utf-8')as f:
f.write(requests.get(url).text)
print('m3u8存储完毕')
with open('影视/m3u82.txt', 'r', encoding='utf-8')as f:
lines = f.readlines()
for line in lines:
if line.startswith('#'):
continue
# print(line)
base = 'https://shuixian.nihaozuida.com/20200313/1391_06cf517b/1024k/hls/'
ts_url = urljoin(base,line.strip().replace('\n',''))
# print(url)
with open('影视/1.mp4','ab')as f:
f.write(requests.get(ts_url).content)
效果

python获取某视频网站视频的更多相关文章
- 使用you-get下载视频网站视频或其他
使用you-get下载视频网站视频或其他 文/玄魂 目录 使用you-get下载视频网站视频或其他 前言 1.1 下载.安装 依赖 exe安装 pip安装 Antigen安装 Git 克隆源码 Hom ...
- Python获取Origin官网视频
程序说明:最近学习origin,看到官网有入门视频(http://www.originlab.com/index.aspx?go=SUPPORT/VideoTutorials),看着挺多的,就用pyt ...
- 下载B站、秒拍等视频网站视频
需要一个FVD Downloader(插件) 安装过程很简单,会浏览器安装插件的就不多说了!
- python爬虫:爬取网站视频
python爬取百思不得姐网站视频:http://www.budejie.com/video/ 新建一个py文件,代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 ...
- 转:最简单的视频网站(JavaEE+FFmpeg)
本文记录一个最简单的视频网站系统.此前做过一些基于JavaEE中的 SSH (Strut2 + Spring + Hibernate)的网站系统,但是一直没有做过一个视频网站系统,所以就打算做一个&q ...
- 最简单的视频网站(JavaEE+FFmpeg)
本文记录一个最简单的视频网站系统.此前做过一些基于JavaEE中的SSH (Strut2 + Spring + Hibernate)的网站系统,但是一直没有做过一个视频网站系统,所以就打算做一个&qu ...
- 最简单的基于JavaEE和FFmpeg的视频网站
最简单的视频网站 Simplest Video Website 雷霄骅 Lei Xiaohua leixiaohua1020@126.com 中国传媒大学/数字电视技术 Communication U ...
- Python+Tornado+Tampermonkey 获取某讯等主流视频网站的会员视频解析播放
近期,<哪吒之魔童降世>在各大视频软件可以看了,然而却是一贯的套路,非会员谢绝观看!!!只能从国内那些五花八门的视频网站上找着看了,或者通过之前本人说的 Chrome 的油猴插件,传送门 ...
- python下载各大主流视频网站电影
You-Get 是一个命令行工具, 用来下载各大视频网站的视频, 是我目前知道的命令行下载工具中最好的一个, 之前使用过 youtube-dl, 但是 youtube-dl 吧, 下载好的视频是分段的 ...
随机推荐
- 痞子衡嵌入式:解锁i.MXRTxxx上FlexSPI模块自带的地址重映射(Remap)功能
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT三位数系列隐藏的FlexSPI Remap功能. 前段时间痞子衡写了一篇文章 <利用i.MXRT1060,1010上新 ...
- SparkStreaming简单例子(oldAPI)
SparkStreaming简单例子 ◆ 构建第一个Streaming程序: (wordCount) ◆ Spark Streaming 程序最好以使用Maven或者sbt编译出来的独立应用的形式运行 ...
- 第5篇scrum冲刺(5.25)
一.站立会议 1.照片 2.工作安排 成员 昨天已完成的工作 今天的工作安排 困难 陈芝敏 线下模块(还剩下获取词的数据库) 研究云开发,更新了登录模块,把用户的信息传入数据库了 起初在云函数 ...
- Adversarial Attack Type I: Cheat Classifiers by Significant Changes
出于实现目的,翻译原文(侵删) Published in: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI ...
- Hadoop 2.6.1 集群安装配置教程
集群环境: 192.168.56.10 master 192.168.56.11 slave1 192.168.56.12 slave2 下载安装包/拷贝安装包 # 存放路径: cd /usr/loc ...
- Java方法传参,测试在方法内部改变参数内容是否会影响到原值
我分了三种类型的参数进行测试 一.基本类型 public static void main(String[] args) { System.out.println("验证基本类型int作为参 ...
- CF1349A Orac and LCM 题解
题意分析 给出$n$个数,求这$n$个数两两的最小公倍数的最大公约数 思路分析 通过分析样例可以发现,如果要成为这$n$个数两两的最小公倍数的公约数,至少要是这$n$个数中$n-1$个数的约数,否则就 ...
- [CSP-S2019]括号树 题解
CSP-S2 2019 D1T2 刚开考的时候先大概浏览了一遍题目,闻到一股浓浓的stack气息 调了差不多1h才调完,加上T1用了1.5h+ 然而T3还是没写出来,滚粗 思路分析 很容易想到的常规操 ...
- 【洛谷日报#26】GCC自带位运算系列函数
文章转自 洛谷 谈到GCC的黑科技,大家想到的一定是这句: #pragma GCC optimize (3)//吸氧 抑或是这句: #pragma GCC diagnostic error " ...
- 数据结构与算法系列2 线性表 链表的分类+使用java实现链表+链表源码详解
数据结构与算法系列2.2 线性表 什么是链表? 链表是一种物理存储单元上非连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表的链接次序实现的一系列节点组成,节点可以在运行时动态生成,每个节点包括两个 ...