python爬虫:爬取网站视频
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/python# -*- coding: UTF-8 -*-import urllib,re,requestsimport sysreload(sys)sys.setdefaultencoding('utf-8')url_name = [] #url namedef get(): #获取源码 hd = {"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"} url = 'http://www.budejie.com/video/' html = requests.get(url,headers=hd).text url_content = re.compile(r'(<div class="j-r-list-c">.*?</div>.*?</div>)',re.S) #编译 url_contents = re.findall(url_content,html) #匹配 for i in url_contents: #匹配视频 url_reg = r'data-mp4="(.*?)"' #视频地址 url_items = re.findall(url_reg,i) #print url_items if url_items: #判断视频是否存在 name_reg = re.compile(r'<a href="/detail-.{8}?.html">(.*?)</a>',re.S) name_items = re.findall(name_reg,i) #print name_items[0] for i,k in zip(name_items,url_items): url_name.append([i,k]) print i,k for i in url_name: #i[1]=url i[0]=name urllib.urlretrieve(i[1],'video\\%s.mp4' % (i[0].decode('utf-8')))if __name__ == "__main__": get() |
在 py 文件下新建一个 video 文件夹,执行后结果如下:
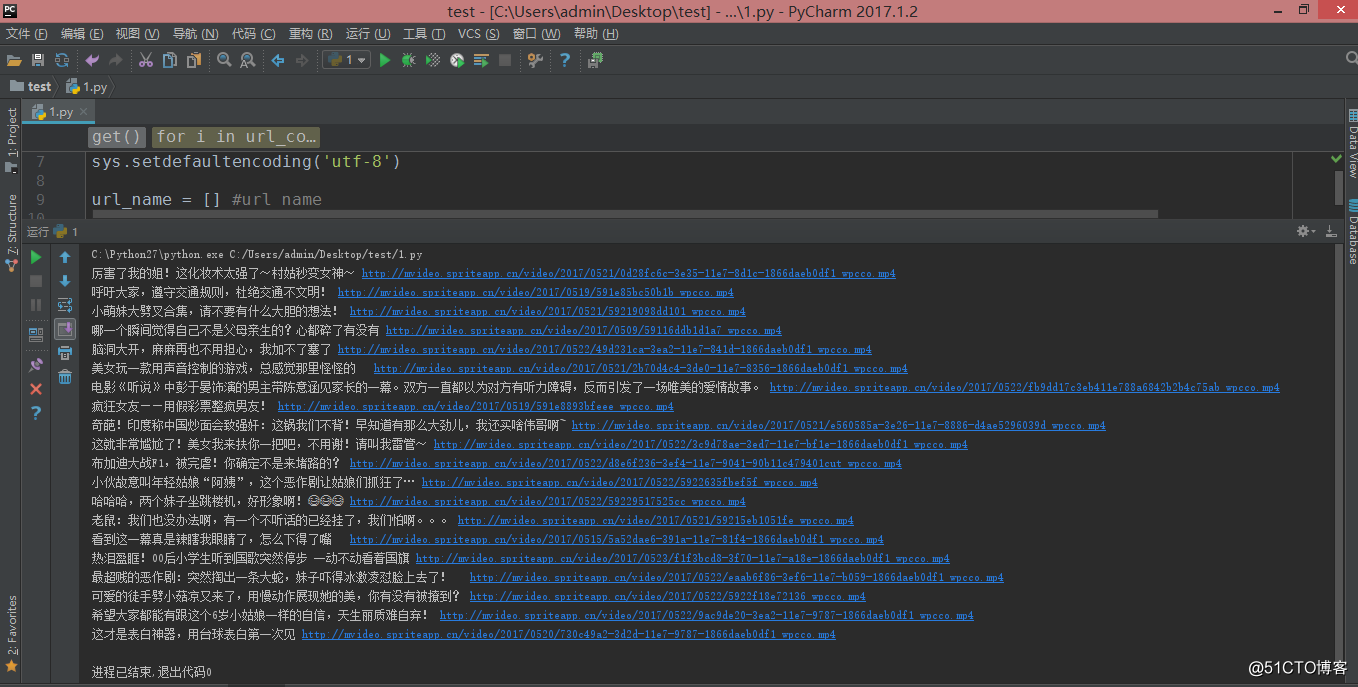
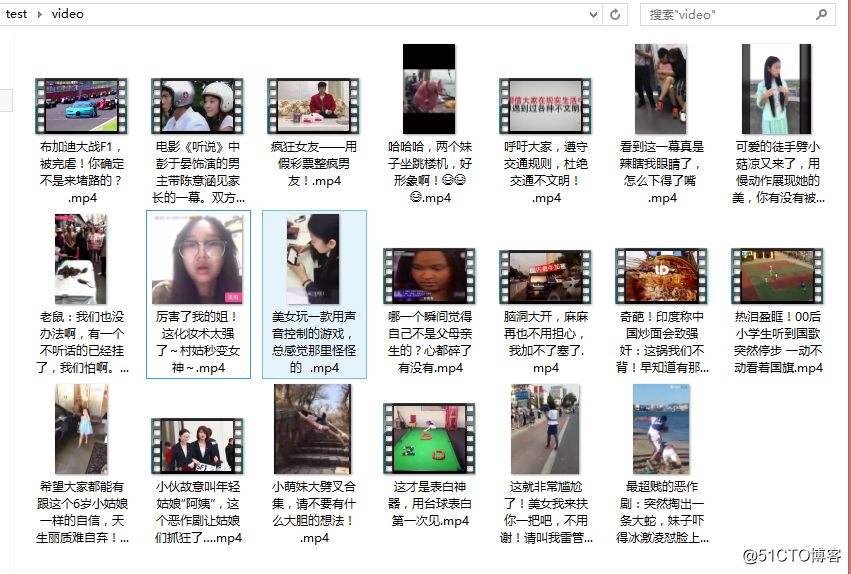
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
转载:http://blog.51cto.com/xiaogongju/2061754
python爬虫:爬取网站视频的更多相关文章
- Python爬虫爬取qq视频等动态网页全代码
环境:py3.4.4 32位 需要插件:selenium BeautifulSoup xlwt # coding = utf-8 from selenium import webdriverfrom ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 通过samba服务将centos7指定文件挂载到window下
做嵌入式开发,windows下编辑代码,虚拟机上编译,为了方便打算在虚拟机下搭一个samba服务器,将文件夹映射到windows下,搜索网上的方法,内容大同小异,试了半天终于成功了.特此记录一下步骤, ...
- app与php后台接口登录认证、验证(seesion和token)
简要:随着电商的不断发展,APP也层次不穷,随着科技的发展主要登录形式(微信.QQ.账号/密码):为此向大家分享一下"app与php后台接口登录认证.验证"想法和做法:希望能够帮助 ...
- ubuntu网卡
查看网卡类型 http://blog.csdn.net/eddy_liu/article/details/6578819 qii@ubuntu:~$ lspci | grep -i net 03:0 ...
- 跨平台编译Go程序(交叉编译)
作用:比如你手头只有Mac系统,而你的用户有Linux和Windows的,他们也想用,你可以通过交叉编译出Linux和Windows上的可执行文件给他们用 (1)首先进入go/src 源码所在目录,执 ...
- 在生产环境中部署asp.net core应用
设备:阿里云ECS云主机 操作系统:centos 7 操作步骤: 1 安装.net core sdk: # 添加dotnet product feed sudo rpm --import https: ...
- WSL跑linux服务程序
前段时间折腾了一次WSL下的Apache,无奈遇到各种奇葩问题,总是解决不了,最终放弃,甚至得出了一个现在看来比较可笑的结论:WSL是不可能跑Linux服务程序的! 当时的思路想歪了,由于Apache ...
- android 学习四 ContentProvider
1.系统自带的许多数据(联系人,本地信息等)保存在sqllite数据库,然后封装成许多ContentProvider来供其他程序访问. 2.对sqllite数据库的操作,可以在命令行通过adb工具登录 ...
- Linux命令应用大词典-第18章 磁盘分区
18.1 fdisk:分区表管理 18.2 parted:分区维护程序 18.3 cfdisk:基于磁盘进行分区操作 18.4 partx:告诉内核关于磁盘上分区的号码 18.5 sfdisk:用于L ...
- 牛客网暑期ACM多校训练营(第五场):F - take
链接:牛客网暑期ACM多校训练营(第五场):F - take 题意: Kanade有n个盒子,第i个盒子有p [i]概率有一个d [i]大小的钻石. 起初,Kanade有一颗0号钻石.她将从第1到第n ...
- hihocoder刷题 扫雷游戏
题目1 : 扫雷游戏 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 给定一个N × N的方格矩阵,其中每个格子或者是'*',表示该位置有一个地雷:或者是'.',表示该位 ...