机器学习实战基础(三十):决策树(三) DecisionTreeRegressor
DecisionTreeRegressor
class sklearn.tree.DecisionTreeRegressor (criterion=’mse’, splitter=’best’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort=False)
几乎所有参数,属性及接口都和分类树一模一样。需要注意的是,在回归树种,没有标签分布是否均衡的问题,因此没有class_weight这样的参数。
1 重要参数,属性及接口
criterion
回归树衡量分枝质量的指标,支持的标准有三种:
1)输入"mse"使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失
2)输入“friedman_mse”使用费尔德曼均方误差,这种指标使用弗里德曼针对潜在分枝中的问题改进后的均方误差
3)输入"mae"使用绝对平均误差MAE(mean absolute error),这种指标使用叶节点的中值来最小化L1损失
属性中最重要的依然是feature_importances_,接口依然是apply, fit, predict, score最核心。
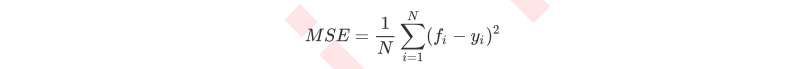
其中N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签。所以MSE的本质,其实是样本真实数据与回归结果的差异。
在回归树中,MSE不只是我们的分枝质量衡量指标,也是我们最常用的衡量回归树回归质量的指标,当我们在使用交叉验证,或者其他方式获取回归树的结果时,我们往往选择均方误差作为我们的评估(在分类树中这个指标是score代表的预测准确率)。在回归中,我们追求的是,MSE越小越好。
然而,回归树的接口score返回的是R平方,并不是MSE。R平方被定义如下:
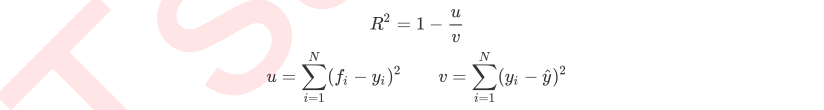
其中u是残差平方和(MSE * N),v是总平方和,N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签。y帽是真实数值标签的平均数。R平方可以为正为负(如果模型的残差平方和远远大于模型的总平方和,模型非常糟糕,R平方就会为负),而均方误差永远为正。
值得一提的是,虽然均方误差永远为正,但是sklearn当中使用均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。
这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss),因此在sklearn当中,都以负数表示。
真正的均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
简单看看回归树是怎样工作的
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10,
scoring = "neg_mean_squared_error") #交叉验证cross_val_score的用法
交叉验证是用来观察模型的稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确性来评估模型的平均准确程度。
训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。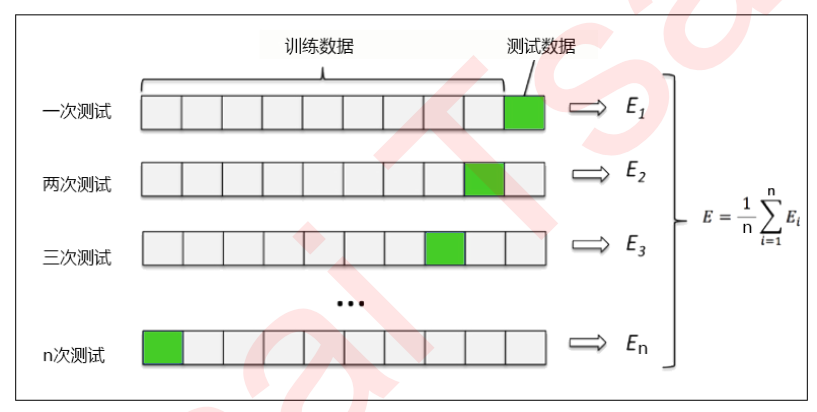
2 实例:一维回归的图像绘制
接下来我们到二维平面上来观察决策树是怎样拟合一条曲线的。我们用回归树来拟合正弦曲线,并添加一些噪声来观察回归树的表现。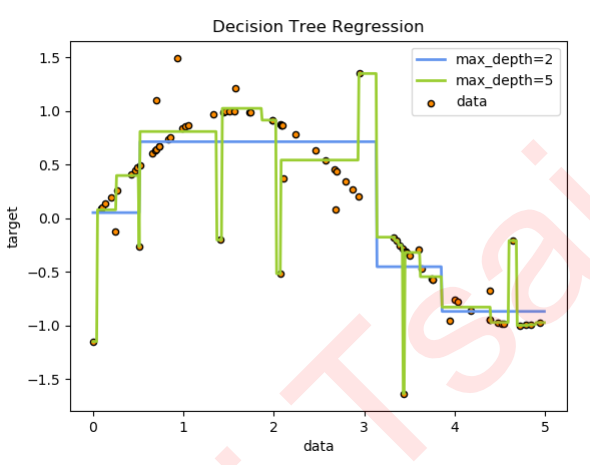
1. 导入需要的库
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
2. 创建一条含有噪声的正弦曲线
在这一步,我们的基本思路是,先创建一组随机的,分布在0~5上的横坐标轴的取值(x),然后将这一组值放到sin函数中去生成纵坐标的值(y),接着再到y上去添加噪声。全程我们会使用numpy库来为我们生成这个正弦曲线。
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80,1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16)) #np.random.rand(数组结构),生成随机数组的函数 #了解降维函数ravel()的用法
np.random.random((2,1))
np.random.random((2,1)).ravel()
np.random.random((2,1)).ravel().shape
3. 实例化&训练模型
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
4. 测试集导入模型,预测结果
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test) #np.arrange(开始点,结束点,步长) 生成有序数组的函数 #了解增维切片np.newaxis的用法
l = np.array([1,2,3,4])
l l.shape l[:,np.newaxis] l[:,np.newaxis].shape l[np.newaxis,:].shape
5. 绘制图像
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
可见,回归树学习了近似正弦曲线的局部线性回归。我们可以看到,如果树的最大深度(由max_depth参数控制)设置得太高,则决策树学习得太精细,它从训练数据中学了很多细节,包括噪声得呈现,从而使模型偏离真实的正弦曲线,形成过拟合。
机器学习实战基础(三十):决策树(三) DecisionTreeRegressor的更多相关文章
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(十六):sklearn中的数据预处理和特征工程(九)特征选择 之 Filter过滤法(三) 总结
过滤法总结 到这里我们学习了常用的基于过滤法的特征选择,包括方差过滤,基于卡方,F检验和互信息的相关性过滤,讲解了各个过滤的原理和面临的问题,以及怎样调这些过滤类的超参数.通常来说,我会建议,先使用方 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十九):sklearn中数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 程序员编程艺术第三十六~三十七章、搜索智能提示suggestion,附近点搜索
第三十六~三十七章.搜索智能提示suggestion,附近地点搜索 作者:July.致谢:caopengcs.胡果果.时间:二零一三年九月七日. 题记 写博的近三年,整理了太多太多的笔试面试题,如微软 ...
- 自学 iOS – 三十天三十个 Swift 项目
自学 iOS – 三十天三十个 Swift 项目 github源码地址:https://github.com/allenwong/30DaysofSwift
- 自学 iOS - 三十天三十个 Swift 项目 第一天
最近公司项目不是很忙,偶然间看到编程语言排行榜,看到swift 已经排到前10了,然OC排名也越来越后了,感觉要上车了,虽然现在项目都是用OC写的,但是swift是一种趋势.在网上看到"自学 ...
随机推荐
- centos7上安装redis以及PHP安装redis扩展(一)
1.关闭防火墙: systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewal ...
- CGAL代码阅读跳坑指南
CGAL代码阅读跳坑指南 整体框架介绍 CGAL中的算法和数据结构由它们使用的对象类型和操作参数化.它们可以处理满足特定语法和语义需求的任何具体模板参数.为了避免长参数列表,参数类型被收集到一个单独的 ...
- CKA考试个人心得分享
考试相关准备: 真题:需要的私密: 网络:必须开启VPN,以便能访问国外网络,强烈建议在香港搭建相应FQ: 证件:考试需要出示含有拉丁文(英文)带照片的有效证件,相关有效证件参考(优先建议护照):ht ...
- Vue中hash模式和history模式的区别
vue-router 中hash模式和history模式. 在vue的路由配置中有mode选项,最直观的区别就是在hash模式下的地址栏里的URL夹杂着‘#’号 ,而history模式下没有.vue默 ...
- Machine Learning Note
[Andrew Ng NIPS2016演讲]<Nuts and Bolts of Applying Deep Learning (Andrew Ng) 中文详解:https://mp.weixi ...
- nuget 包是如何还原包的
nuget 是如何还原包的 Intro 一直以来从来都是用 nuget 包,最近想折腾一个东西,需要自己搞一个 nuget 包的解析,用户指定 nuget 包的名称和版本,然后去解析对应的 nuget ...
- mysqldump: Got error: 1044: Access denied for user 'root'@'%' to database 'hhh' when using LOCK TABLES
错误原因:mysqldump 命令执行时,需要四种权限,分别是:select,show view,trigger,lock table.但是因为没有lock table的权限,导致上述错误发生. 修改 ...
- 底层剖析Python深浅拷贝
底层剖析Python深浅拷贝 拷贝的用途 拷贝就是copy,目的在于复制出一份一模一样的数据.使用相同的算法对于产生的数据有多种截然不同的用途时就可以使用copy技术,将copy出的各种副本去做各种不 ...
- 使用Visual Studio 开发SharePoint项目时的快捷键
组合键:ctrl+c,alt+c,Shift+ctrl+c,可以快速的将文件拷贝到对应的部署目录下.
- Python-数据结构-最全六种排序代码实现
1.冒泡排序 def bubble_sort(alist): """冒泡排序""" n = len(alist) for j in rang ...