CNN中千奇百怪的卷积方式大汇总
1.原始版本
最早的卷积方式还没有任何骚套路,那就也没什么好说的了。
见下图,原始的conv操作可以看做一个2D版本的无隐层神经网络。
附上一个卷积详细流程:
【TensorFlow】tf.nn.conv2d是怎样实现卷积的? - CSDN博客

代表模型:
LeNet:最早使用stack单卷积+单池化结构的方式,卷积层来做特征提取,池化来做空间下采样
AlexNet:后来发现单卷积提取到的特征不是很丰富,于是开始stack多卷积+单池化的结构
VGG([1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition):结构没怎么变,只是更深了
2.多隐层非线性版本
这个版本是一个较大的改进,融合了Network In Network的增加隐层提升非线性表达的思想,于是有了这种先用1*1的卷积映射到隐空间,再在隐空间做卷积的结构。同时考虑了多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,再把结果concat起来。
这一结构,被称之为“Inception”

代表模型:
Inception-v1([1409.4842] Going Deeper with Convolutions):stack以上这种Inception结构
Inception-v2(Accelerating Deep Network Training by Reducing Internal Covariate Shift):加了BatchNormalization正则,去除5*5卷积,用两个3*3代替
Inception-v3([1512.00567] Rethinking the Inception Architecture for Computer Vision):7*7卷积又拆成7*1+1*7
Inception-v4([1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning):加入了残差结构
3.空洞卷积
Dilation卷积,通常译作空洞卷积或者卷积核膨胀操作,它是解决pixel-wise输出模型的一种常用的卷积方式。一种普遍的认识是,pooling下采样操作导致的信息丢失是不可逆的,通常的分类识别模型,只需要预测每一类的概率,所以我们不需要考虑pooling会导致损失图像细节信息的问题,但是做像素级的预测时(譬如语义分割),就要考虑到这个问题了。
所以就要有一种卷积代替pooling的作用(成倍的增加感受野),而空洞卷积就是为了做这个的。通过卷积核插“0”的方式,它可以比普通的卷积获得更大的感受野,这个idea的motivation就介绍到这里。具体实现方法和原理可以参考如下链接:
如何理解空洞卷积(dilated convolution)?
膨胀卷积--Multi-scale context aggregation by dilated convolutions
我在博客里面又做了一个空洞卷积小demo方便大家理解
【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积? - CSDN博客
代表模型:
FCN([1411.4038] Fully Convolutional Networks for Semantic Segmentation):Fully convolutional networks,顾名思义,整个网络就只有卷积组成,在语义分割的任务中,因为卷积输出的feature map是有spatial信息的,所以最后的全连接层全部替换成了卷积层。
Wavenet(WaveNet: A Generative Model for Raw Audio):用于语音合成。
4.深度可分离卷积
Depthwise Separable Convolution,目前已被CVPR2017收录,这个工作可以说是Inception的延续,它是Inception结构的极限版本。
为了更好的解释,让我们重新回顾一下Inception结构(简化版本):

上面的简化版本,我们又可以看做,把一整个输入做1*1卷积,然后切成三段,分别3*3卷积后相连,如下图,这两个形式是等价的,即Inception的简化版本又可以用如下形式表达:

OK,现在我们想,如果不是分成三段,而是分成5段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,切到不能再切了,正好是Output channels的数量(极限版本):

于是,就有了深度卷积(depthwise convolution),深度卷积是对输入的每一个channel独立的用对应channel的所有卷积核去卷积,假设卷积核的shape是[filter_height, filter_width, in_channels, channel_multiplier],那么每个in_channel会输出channel_multiplier那么多个通道,最后的feature map就会有in_channels * channel_multiplier个通道了。反观普通的卷积,输出的feature map一般就只有channel_multiplier那么多个通道。
具体的过程可参见我的demo:
【Tensorflow】tf.nn.depthwise_conv2d如何实现深度卷积? - CSDN博客
既然叫深度可分离卷积,光做depthwise convolution肯定是不够的,原文在深度卷积后面又加了pointwise convolution,这个pointwise convolution就是1*1的卷积,可以看做是对那么多分离的通道做了个融合。
这两个过程合起来,就称为Depthwise Separable Convolution了:
【Tensorflow】tf.nn.separable_conv2d如何实现深度可分卷积? - CSDN博客
代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
5.比较
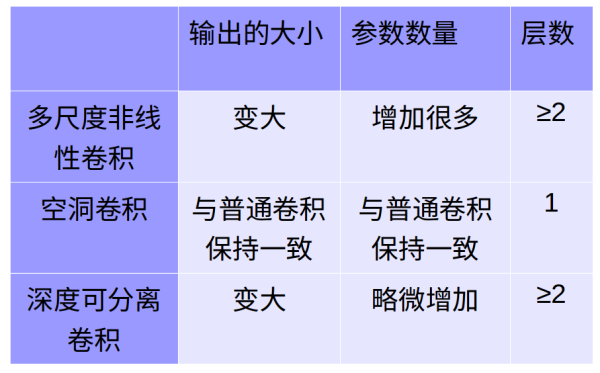
转载:https://zhuanlan.zhihu.com/p/29367273?utm_source=qq&utm_medium=social
CNN中千奇百怪的卷积方式大汇总的更多相关文章
- [转]CNN 中千奇百怪的卷积方式大汇总
https://www.leiphone.com/news/201709/AzBc9Sg44fs57hyY.html 推荐另一篇很好的总结:变形卷积核.可分离卷积?卷积神经网络中十大拍案叫绝的操作. ...
- (原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处: http://www.cnblogs.com/darkknightzh/p/9017854.html 参考网址: https://pytorch.org/docs/stable/nn ...
- 卷积运算的本质,以tensorflow中VALID卷积方式为例。
卷积运算在数学上是做矩阵点积,这样可以调整每个像素上的BGR值或HSV值来形成不同的特征.从代码上看,每次卷积核扫描完一个通道是做了一次四重循环.下面以VALID卷积方式为例进行解释. 下面是pyth ...
- CNN中各类卷积总结:残差、shuffle、空洞卷积、变形卷积核、可分离卷积等
CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量.我下面会对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中 ...
- FPGA知识大梳理(四)FPGA中的复位系统大汇总
本文整合特权(吴厚航)和coyoo(王敏志)两位大神的博文.我也很推崇这两位大神的书籍,特权的书籍要偏基础一下,大家不要一听我这么说就想买coyoo的.我还是那一句话,做技术就要step by ste ...
- CNN中的卷积操作的参数数计算
之前一直以为卷积是二维的操作,而到今天才发现卷积其实是在volume上的卷积.比如输入的数据是channels*height*width(3*10*10),我们定义一个核函数大小为3*3,则输出是8* ...
- CNN中的卷积理解和实例
卷积操作是使用一个二维卷积核在在批处理的图片中进行扫描,具体的操作是在每一张图片上采用合适的窗口大小在图片的每一个通道上进行扫描. 权衡因素:在不同的通道和不同的卷积核之间进行权衡 在tensorfl ...
- html中加入超链接方式的汇总
在CSS样式中,对超链接的样式有以下几种定义(1)设置链接未被访问时的样式,具体写法如下:a:link{font-size:10px;... }(2)设置链接在鼠标经过时的样式,具体写法如下:a:ho ...
- js实现数组去重(方式大汇总)
方法一:循环判断当前元素与其后面所有元素对比是否相等,如果相等删除:(执行速度慢) var arr = [1,23,1,1,1,3,23,5,6,7,9,9,8,5]; function remove ...
随机推荐
- 【bzoj4417】[Shoi2013]超级跳马 矩阵乘法
题目描述 现有一个n行m列的棋盘,一只马欲从棋盘的左上角跳到右下角.每一步它向右跳奇数列,且跳到本行或相邻行.跳越期间,马不能离开棋盘.例如,当n = 3, m = 10时,下图是一种可行的跳法. ...
- BZOJ4832 抵制克苏恩(概率期望+动态规划)
注意到A+B+C很小,容易想到设f[i][A][B][C]为第i次攻击后有A个血量为1.B个血量为2.C个血量为3的期望伤害,倒推暴力转移即可. #include<iostream> #i ...
- Android Service 生命周期
Service概念及用途: Android中的服务,它与Activity不同,它是不能与用户交互的,不能自己启动的,运行在后台的程序,如果我们退出应用时,Service进程并没有结束,它仍然在后台运行 ...
- 【BZOJ5297】【CQOI2018】社交网络(矩阵树定理)
[BZOJ5297][CQOI2018]社交网络(矩阵树定理) 题面 BZOJ 洛谷 Description 当今社会,在社交网络上看朋友的消息已经成为许多人生活的一部分.通常,一个用户在社交网络上发 ...
- BZOJ5290 & 洛谷4438:[HNOI/AHOI2018]道路——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=5290 https://www.luogu.org/problemnew/show/P4438 的确 ...
- BZOJ2820:YY的GCD——题解
http://www.lydsy.com/JudgeOnline/problem.php?id=2820 Description 神犇YY虐完数论后给傻×kAc出了一题给定N, M,求1<=x& ...
- BZOJ3223:文艺平衡树——超详细题解
http://www.lydsy.com/JudgeOnline/problem.php?id=3223 题面复制于洛谷. 题目背景 这是一道经典的Splay模板题——文艺平衡树. 题目描述 您需要写 ...
- BZOJ 1016 Windy 数 | 数位DP
题目: http://www.lydsy.com/JudgeOnline/problem.php?id=1026 题解: f[i][j][1/0]表示枚举到第i位,这位开头是j,当前的数大于(1)或小 ...
- bzoj2083: [Poi2010]Intelligence test(二分+vector)
只是记录一下vector的用法 v.push_back(x)加入x v.pop_back()弹出最后一个元素 v[x]=v.back(),v.pop_back()删除x,但是会打乱vector顺序 v ...
- 【单调队列】【P1714】 切蛋糕
传送门 Description 今天是小Z的生日,同学们为他带来了一块蛋糕.这块蛋糕是一个长方体,被用不同色彩分成了N个相同的小块,每小块都有对应的幸运值. 小Z作为寿星,自然希望吃到的第一块蛋糕的幸 ...