Windows11安装Hadoop3.3.2
Windows11安装Hadoop3.3.2
JDK 安装
Hadoop的Java版本https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
>## Hadoop支持的 Java 版本
>
>- Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)
> - 请使用 Java 8 编译 Hadoop。不支持使用 Java 11 编译 Hadoop: [HADOOP-16795](https://issues.apache.org/jira/browse/HADOOP-16795)-Java 11 编译支持**OPEN** [](https://issues.apache.org/jira/browse/HADOOP-16795)
>- 从 3.0.x 到 3.2.x 的 Apache Hadoop 现在仅支持 Java 8
>- 从 2.7.x 到 2.10.x 的 Apache Hadoop 支持 Java 7 和 8
所以安装jdk8来运行Hadoop
官网下载:https://www.oracle.com/java/technologies/downloads/#jre8-windows
选择Windows下的64位安装程序下载

运行安装程序即可,不需配置环境变量
Hadoop 安装
下载解压
阿里云开源镜像站下载:https://mirrors.aliyun.com/apache/hadoop/core/hadoop-3.3.2/
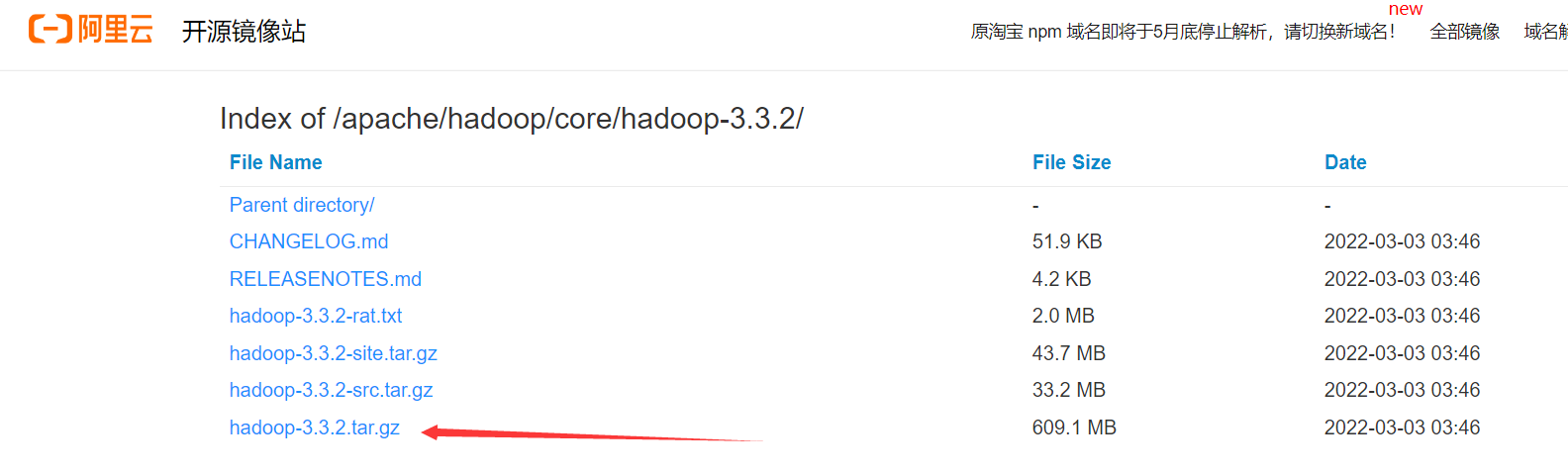
推荐使用下载Bandzip来解压
解压之后的目录
Windows环境变量配置
设置->系统->系统信息
点击高级系统设置,环境变量
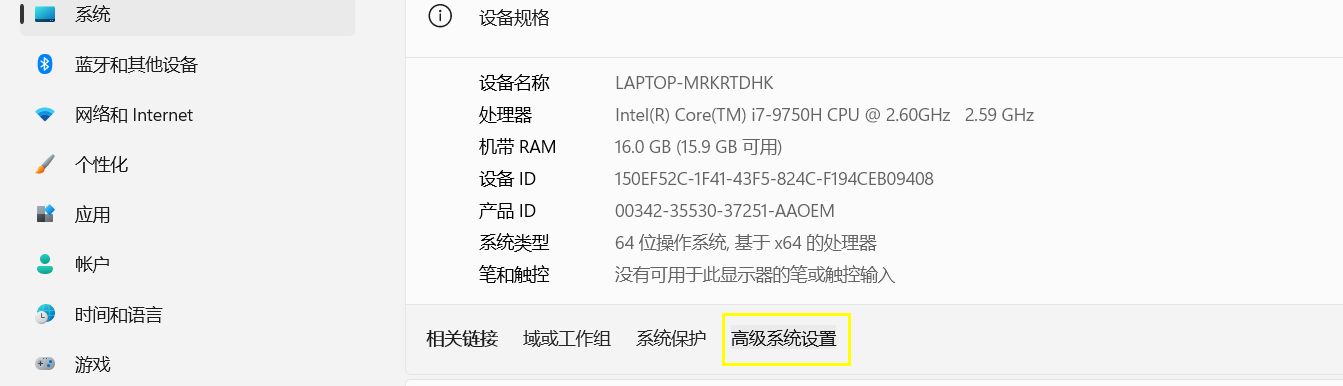
在系统变量处新建
HADOOP_HOME
变量值为hadoop的解压目录
D:\SoftWare\hadoop-3.3.2
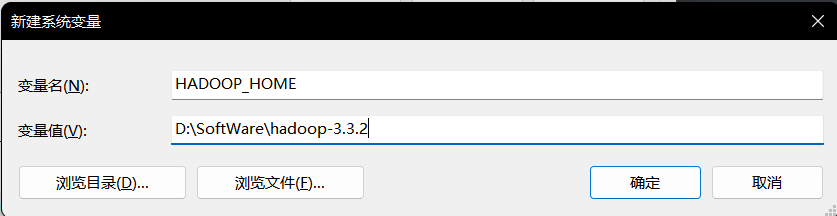
在系统变量的Path下新建两个变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
hadoop文件配置
hadoop-env.cmd
在D:\SoftWare\hadoop-3.3.2\etc\hadoop目录下
右键编辑,Ctrl+F搜索JAVA_HOME找到set JAVA_HOME这一项,将其修改为jdk8的安装路径
set JAVA_HOME=C:\PROGRA~1\Java\jdk-8
使用PROGRA~1来代替Program Files,是其dos文件名模式下的缩写
直接使用Program Files会报错,里面包含一个空格
在命令行查看hadoop版本,没有报错说明配置成功
hadoop -version
输出信息:
PS C:\Users\Ran> hadoop -version Active code page: 65001 java version "1.8.0_333" Java(TM) SE Runtime Environment (build 1.8.0_333-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.333-b02, mixed mode)
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
下载 winutils.exe hadoop.dll
Github:https://github.com/cdarlint/winutils
找到对应的版本,下载winutils.exe hadoop.dll,放到hadoop的bin目录下
<img src="../AppData/Roaming/Typora/typora-user-images/image-20220608174808274.png" alt="image-20220608174808274" style="zoom: 50%;" />
<img src="../AppData/Roaming/Typora/typora-user-images/image-20220608180503994.png" alt="image-20220608180503994" style="zoom: 67%;" />
启动测试
进入命令行窗口,格式化hadoop
hadoop namenode -format
输出信息中提示有==namenode has been successfully formatted==即可
启动hadoop,在管理员权限的命令行中输入
start-all.cmd
然后启动四个进程的cmd,启动和报错信息会在里面显示
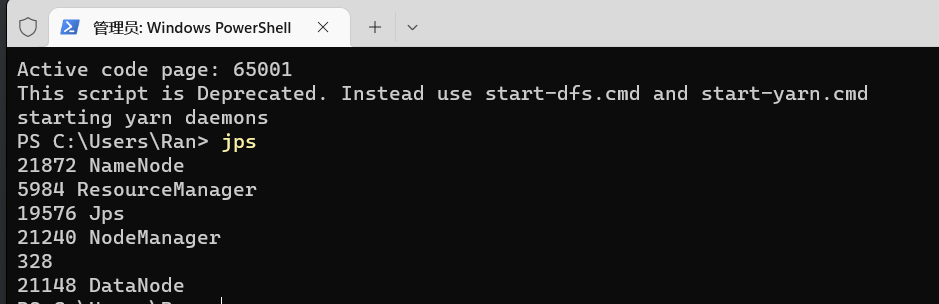
使用jps命令查看,如下即为正常启动
访问Web页面
http://localhost:9870/
Windows11安装Hadoop3.3.2的更多相关文章
- Ubuntn16.04.3安装Hadoop3.0+scale2.12+spark2.2
Ubuntn16.04.3安装Hadoop3.0+scale2.12+spark2.2 对比参照此博文.bovenson 前言:因为安装的Hadoop.Scale是基于JAVA的应用程序,所以必须先安 ...
- 基于zookeeper-3.5.5安装hadoop-3.1.2
目录 目录 1 1. 前言 3 2. 缩略语 3 3. 安装步骤 4 4. 下载安装包 4 5. 机器规划 4 6. 设置批量操作参数 5 7. 环境准备 5 7.1. 修改最大可打开文件数 5 7. ...
- ubuntu 18.04.1安装hadoop3.1.2
前提,虚拟机安装 见https://www.cnblogs.com/cxl-blog/p/11363183.html 一.按照https://blog.csdn.net/MastetHuang/art ...
- Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了 ------------------------- 上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hado ...
- Hadoop3集群搭建之——hive安装
Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hbase安装及简单操作 现在到 ...
- Hadoop3集群搭建之——虚拟机安装
现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化 ...
- 在Hadoop-3.1.2上安装HBase-2.2.1
目录 目录 1 1. 前言 3 2. 缩略语 3 3. 安装规划 3 3.1. 用户规划 3 3.2. 目录规划 4 4. 相关端口 4 5. 下载安装包 4 6. 修改配置文件 5 6.1. 修改策 ...
- 避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述) 安装成功之后 输入 输入:java -version 显示如下说明jdk安装成功(我这里是安装JDK8) 二.安装Hadoop3. ...
- CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式)
@ 目录 前言 预先设置 修改主机名 关闭防火墙 创建hadoop用户 SSH安装免密登陆 单机免密登陆--linux配置ssh免密登录 linux环境配置Java变量 配置Java环境变量 安装Ha ...
- linux18.04+jdk11.0.2+hadoop3.1.2部署伪分布式
1. 下载 安装hadoop3.1.2http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz 注意 ...
随机推荐
- 「postOI」Colouring Game
题意 有 \(n\) 个格子排成一行,一开始每个格子上涂了蓝色或红色. Alice 和 Bob 用这些格子做游戏.Alice 先手,两人轮流操作: Alice 操作时,选择两个相邻的格子,其中至少要有 ...
- 002 jmeter入门级写脚本及参数化
1.jmeter入门脚本 步骤分析:测试计划(项目名称)-线程组(业务流程)-http请求(接口名称)-察看结果树 编写脚本四要素:测试计划.至少有一个线程组.至少有一个取样器.必须要有监听器 测试计 ...
- selenium+python的网站爬虫
爬取网站听起来就是程序员的标配,之前一直没有时间学一下,最近有空学习一下顺便记录一下 爬取网站实际上就是利用计算机模拟人的操作来对网站的前端进行访问,而各大浏览器也给计算机提供了访问的接口,也就是浏览 ...
- JS时间处理,兼容IOS
timeFormatting(val) { let time = val.slice(0, 10) // 兼容IOS time = time.replace(/-/g, '/') let date = ...
- linux 创建 挂载 ntfs分区
格式化为ntf分区 先用fdisk创建分区 格式化 mkfs.ntfs -f /dev/sda2 挂载 zxd@x79:~$ cat /etc/fstab# /etc/fstab: static fi ...
- hbase修改表TTL
创建表时可以指定TTL create 'test_lwt',{NAME=>'d',TTL=>3600} 设置test_lwt表数据TTL为3600秒 修改已存在的表TTL disable ...
- 内容类型框架-ContentType 模型
参考Django官方文档 ContentTypeManager¶ classContentTypeManager¶ ContentType 还有一个自定义管理器, ContentTypeManager ...
- SqlServer 优化的技巧
1.避免使用 select * select * 不会走覆盖索引,会出现大量的回表操作,从而导致SQL的查询性能很低 2.用union all 代替 union 1.使用union后,可以获取排重复后 ...
- openwrt通过gre回源
创建 ip tunnel add GRE网卡名 mode gre local 本地LAN IP remote SERVER LAN IP ttl 255 ip link set GRE网卡名 up ...
- MySQL升级5.7.29
采用卸载后升级的方式 参考:https://blog.csdn.net/liu_dong_mei_mei/article/details/104010567 1.卸载原有的MySQL: 之前是wind ...