Python 爬虫实例(6)—— 爬取蚂蚁免费代理
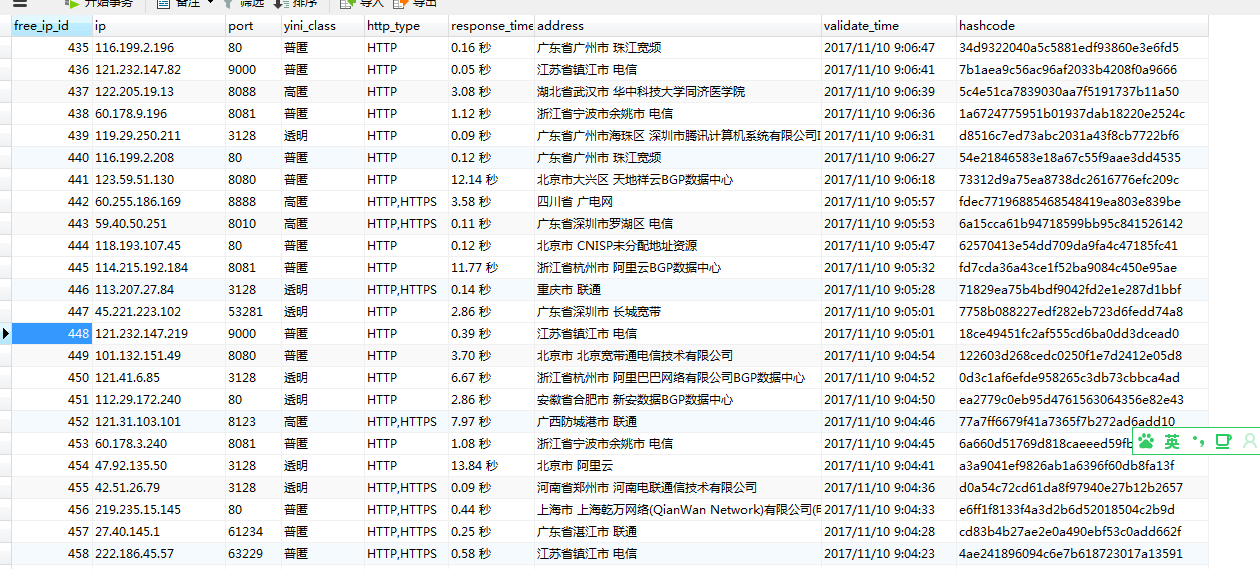
数据库表sql语句:
CREATE TABLE `free_ip` (
`free_ip_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`ip` varchar(255) DEFAULT NULL COMMENT 'ip地址',
`port` varchar(255) DEFAULT NULL COMMENT '端口',
`yini_class` varchar(255) DEFAULT NULL COMMENT '匿名等级',
`http_type` varchar(255) DEFAULT NULL COMMENT '代理类型',
`response_time` varchar(255) DEFAULT NULL COMMENT '响应时间',
`address` varchar(255) DEFAULT NULL COMMENT '地理位置',
`validate_time` varchar(255) DEFAULT NULL COMMENT '最近验证时间',
`hashcode` varchar(255) DEFAULT NULL COMMENT '去重',
PRIMARY KEY (`free_ip_id`),
UNIQUE KEY `hashcode` (`hashcode`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4220 DEFAULT CHARSET=utf8;
源代码:
# coding:utf-8
import random, re
import sqlite3
import json, time
import uuid
from bs4 import BeautifulSoup
import threading
import requests
import MySQLdb
from lxml import etree import urllib3
urllib3.disable_warnings()
import urllib2 import sys
reload(sys)
sys.setdefaultencoding('utf-8') session = requests.session() import logging
import logging.handlers
import platform
sysStr = platform.system()
if sysStr =="Windows":
LOG_FILE_check = 'H:\\log\\log.txt'
else:
LOG_FILE_check = '/log/wlb/crawler/cic.log' handler = logging.handlers.RotatingFileHandler(LOG_FILE_check, maxBytes=128 * 1024 * 1024,backupCount=10) # 实例化handler 200M 最多十个文件
fmt = '\n' + '%(asctime)s - %(filename)s:%(lineno)s - %(message)s'
formatter = logging.Formatter(fmt) # 实例化formatter
handler.setFormatter(formatter) # 为handler添加formatter
logger = logging.getLogger('check') # 获取名为tst的logger
logger.addHandler(handler) # 为logger添加handler
logger.setLevel(logging.DEBUG) def md5(str):
import hashlib
m = hashlib.md5()
m.update(str)
return m.hexdigest() def freeIp(): for i in range(1,1000):
print "正在爬取的位置是:",i url = "http://www.ip181.com/daili/" + str(i)+ ".html"
headers = { "Host":"www.ip181.com",
"Connection":"keep-alive",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer":url,
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.8", }
try: result = session.get(url=url,headers=headers).text
result = result.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(result)[0])
except:
result = session.get(url=url, headers=headers).text
result = result.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(result)[0]) soup = BeautifulSoup(result, 'html.parser') result_soup = soup.find_all("div", attrs={"class": "col-md-12"})[1] result_soup = str(result_soup).replace('\r\n\t','').replace('\r\n','').replace('\n\t','').replace('\n','').replace(' class="warning"','') result_soups = re.findall('最近验证时间</td></tr>(.*?)</tbody></table><div class="page">共',result_soup)[0]
print result_soups
result_list = re.findall('<tr><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td></tr>',result_soups) for item in result_list:
ip = item[0]
port = item[1]
yini_class = item[2]
http_type = item[3]
response_time = item[4]
address = item[5]
validate_time = item[6] proxy = str(ip) + ":" + port hashcode = md5(proxy) try: # 此处是数据库连接,请换成自己的数据库
conn = MySQLdb.connect(host="110.110.110.717", user="lg", passwd="", db="",charset="utf8")
cursor = conn.cursor()
sql = """INSERT INTO free_ip (ip,port,yini_class,http_type,response_time,address,validate_time,hashcode)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s)""" params = (ip,port,yini_class,http_type,response_time,address,validate_time,hashcode)
cursor.execute(sql, params)
conn.commit()
cursor.close()
print " 插入成功 " except Exception as e:
print "********插入失败********"
print e freeIp()
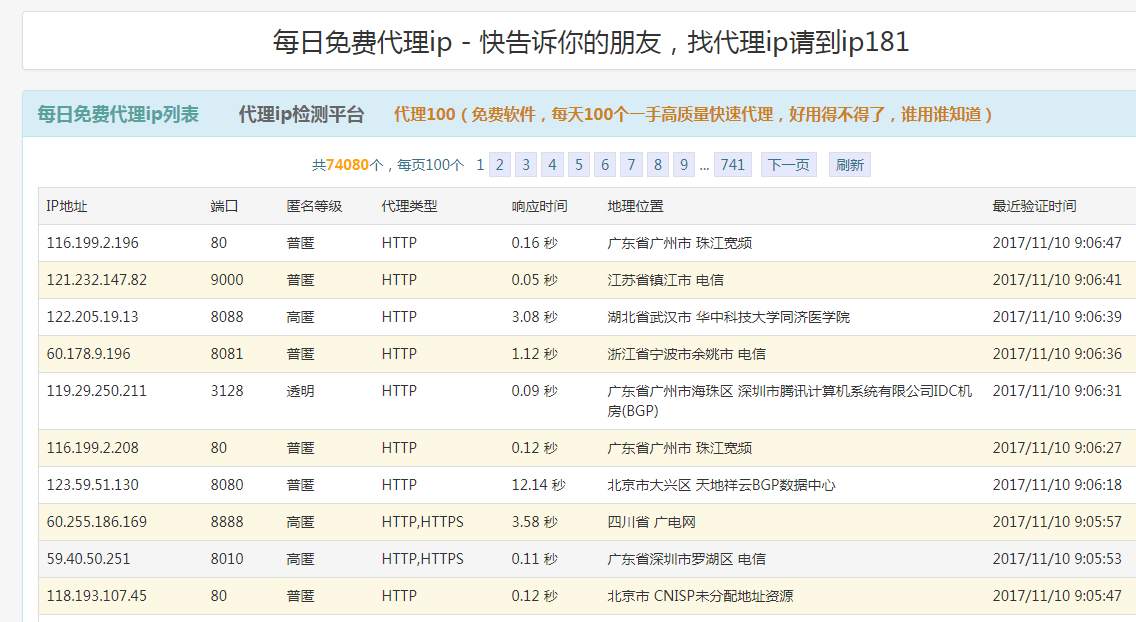
爬取效果:
Python 爬虫实例(6)—— 爬取蚂蚁免费代理的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- Wix使用整理(二)
1) 安装卸载时进行日志记录 Wix 制作的 Installer 的调试很麻烦,没有直接的 Bug 工具,可以通过记录安装日志的方式进行间接调试.命令为 msiexec /i pack ...
- 黑马day16 jquery入门
jquery: 1.jQuery 对象就是通过jQuery包装DOM对象后产生的对象. jQuery对象是jQuery独有的.假设一个对象是jQuery对象,那么它就能够使用jQuery里的方法:$( ...
- Nescafé2 月之谜 题解
月之谜 (mystery.pas/c/cpp) [题目描述] 打败了 Lord lsp 之后,由于 lqr 是一个心地善良的女孩子,她想净化 Lord lsp 黑化的心,使他变回到原来那个天然呆的 l ...
- OpenERP|odoo Web开发
在OpenERP 7 和 Odoo 8下测试均可. 1.相关库/框架 主要:jQuery(使用1.8.3,如果使用新版本,其他jQuery插件也要升级或修改).Underscore.Qweb 其他:都 ...
- ASP.NET中使用TreeView显示文件
在ASP.NET中,TreeView的使用很普遍,把它利用上来 首先加入TreeView控件 <asp:TreeView ID="driverInfoView" runat= ...
- (队列的应用5.3.1)ZOJ 3210 A Stack or A Queue?根据进入结构的序列和离开结构的序列确定是stack还是queue)
/* * ZOJ_3210.cpp * * Created on: 2013年10月30日 * Author: Administrator */ #include <iostream> # ...
- akka模块
模块 Akka的模块化做得非常好,它为不同的功能提供了不同的Jar包. akka-actor-2.0.jar – 标准Actor, 有类型Actor,等等 akka-remote-2.0.jar – ...
- 对SVM的个人理解---浅显易懂
原文:http://blog.csdn.net/arthur503/article/details/19966891 之前以为SVM很强大很神秘,自己了解了之后发现原理并不难,不过,“大师的功力在于将 ...
- android基础知识:SharedPreferences和PreferenceActivity
1.android文件存储 对Android系统了解的都知道,Android系统有四种基本的数据保存方法,一是SharedPreference,二是文件,三是SQLite,四是ContentProvi ...
- angularjs中的数据绑定
这是一个最简单的angularjs的例子,关于数据绑定的,大家可以执行一下,看看效果 <html ng-app> <head> <title>angularjs-i ...