scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例)。
实际上我们在编写爬虫rules规则的时候,做了很多的限定,而且没有对翻页进行处理,所以最终提取的信息数量比较少,经我的测试,总共只有4k多条职位。如果要进行数据分析的话,数量量必须要足够,因此我们先将爬虫规则进行修改。
修改lagou_c.py文件rules
rules = (
Rule(LinkExtractor(allow=r'zhaopin/.*/')), #首页职位列表
Rule(LinkExtractor(allow=r'gongsi/j\d+.html')), #公司职位列表
Rule(LinkExtractor(allow=r'jobs/list_.*',restrict_css='.menu-box')), #校园职位列表
Rule(LinkExtractor(allow=r'jobs/\d+.html'),callback='parse_item',follow=True), #详情页继续跟进,因为详情页包含其他的职位推荐,跟进后也是详情页 )
一、数据存储到MongoDB
如果没有MongoDB请先安装,并进行相应配置,并且启动MongoDB服务(出现connect network is unreachable一般都是没有开启服务造成的)
分析:要想把数据放进MongoDB,跟把大象放进冰箱是一样的道理。先连接数据库,把数据存进去,然后把连接关掉。
- 我们在pipelines.py文件下新建一个类,MongoPipeline,这个类包括三个函数,open_spider(),process_item(),close_spider()
import pymongo #第三方包pymongo,用来连接mongodb数据库并对其操作 class MongoPipeline(object):
def open_spider(self,spider): #开启爬虫的时候连接数据库
passdef process_item(self,item,spider): #运行爬虫的时候把item数据插入到数据库中
passdef close_spider(self,spider): #爬虫关闭的时候把数据库的连接断开
pass
- 为了让代码更易扩展,我们不把mongodb的地址和名称写在这里,改为写在settings.py文件中,通过crawler来进行获取
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri #定义实例变量mongo_uri和mongo_db
self.mongo_db = mongo_db @classmethod
'''
这个类方法就是为了使用crawler来获取全局settings中的MONGO_URI和MONGO_DB的值,并复制给mongo_uri和mongo_db
'''
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri) #与数据库建立连接
self.db = self.client[self.mongo_db] #打开数据库 def process_item(self,item,spider):
self.db[item.collection].insert(dict(item)) #我这里直接获取item.collection字段,而collection我在items.py文件中赋值为’jobs‘,将item数据插入进去
return item #这个item返回才能被其他的中间件获取 def close_spider(self,spider):
self.client.close() #关闭数据库连接
- 修改settings.py文件,增加MONGO_URI和MONGO_DB的定义,并且将MongoPipleline激活
ITEM_PIPELINES = {
#'lagou.pipelines.LagouPipeline': 300,
'lagou.pipelines.MongoPipeline': 333,
}
MONGO_URI = 'localhost'
MONGO_DB = 'lagou'
- 修改items.py文件,增加collection字段
import scrapy class LagouItem(scrapy.Item):
collection = 'jobs'
#其他字段不做修改
这样我们就建立了一个与本地MongoDB的连接,数据库名称是lagou,存入的表collection名称是jobs。我们现在可以运行程序。
一段时间后,使用可视话工具查看,就可以看到数据被存储进了MongoDB数据库。
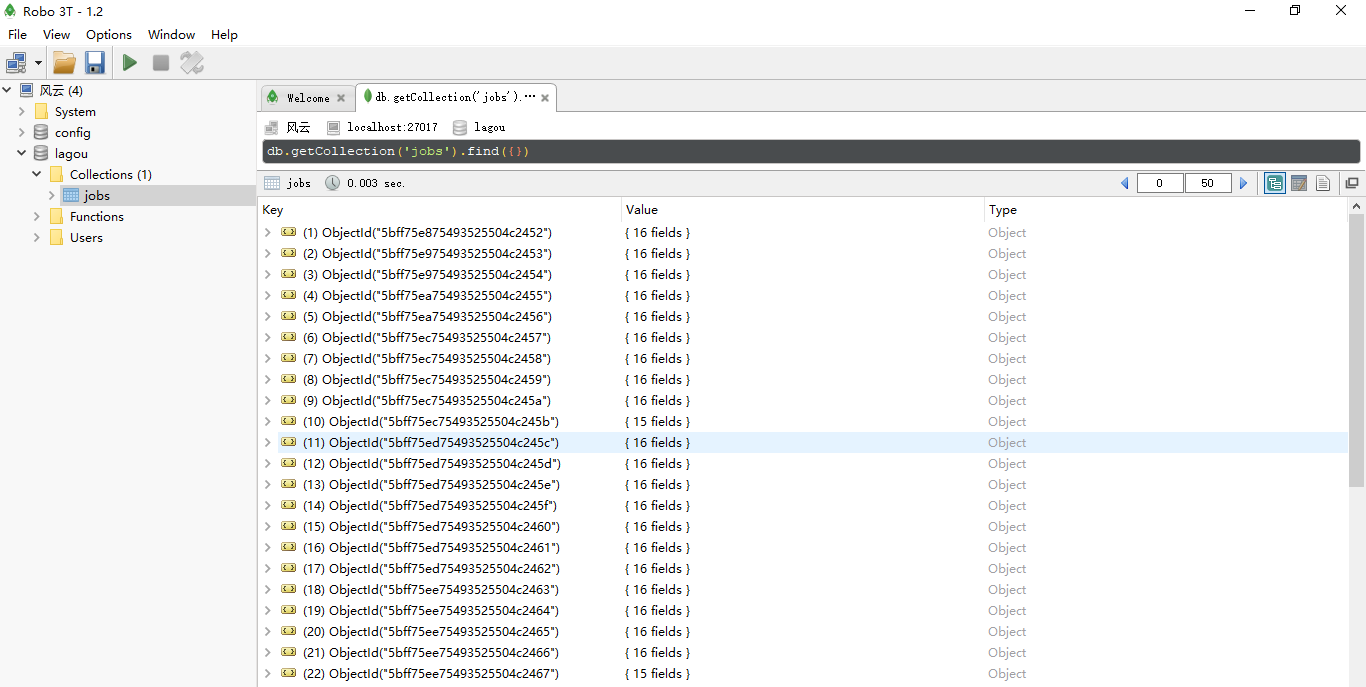
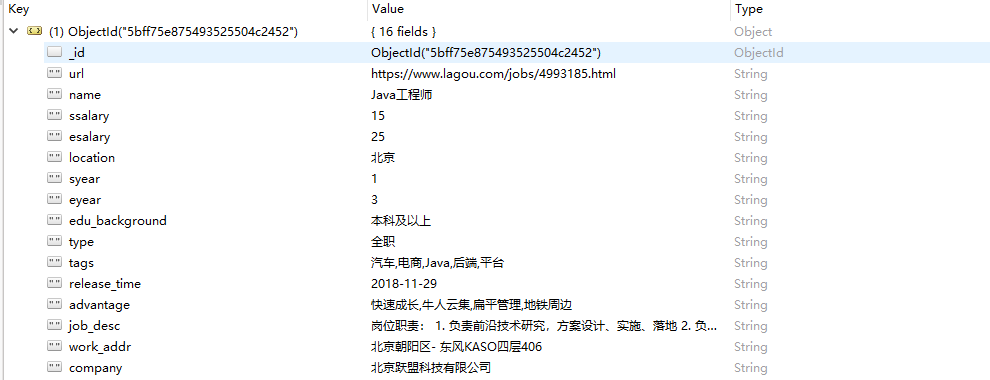
二、数据存储到Mysql
分析:思路与数据存储到MongoDB是一样的,只不过Mysql需要创建表,对各个字段进行定义
- 我们手动创建一个数据库
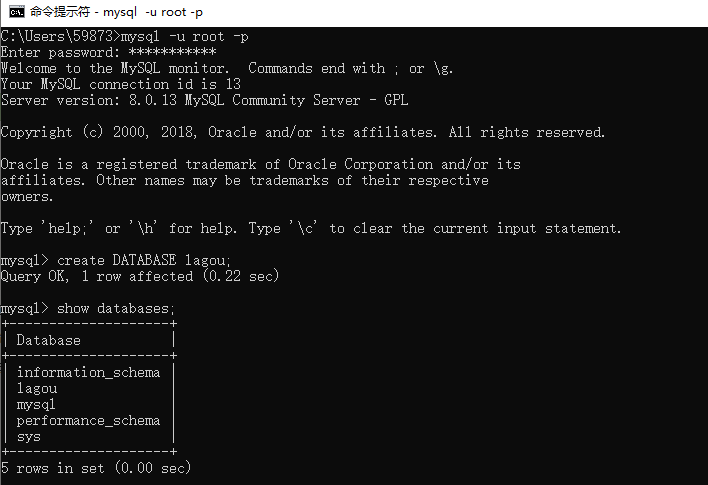
- 进入这个lagou数据库,并且建立一个表
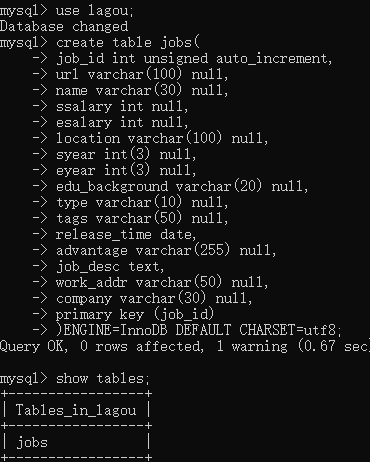
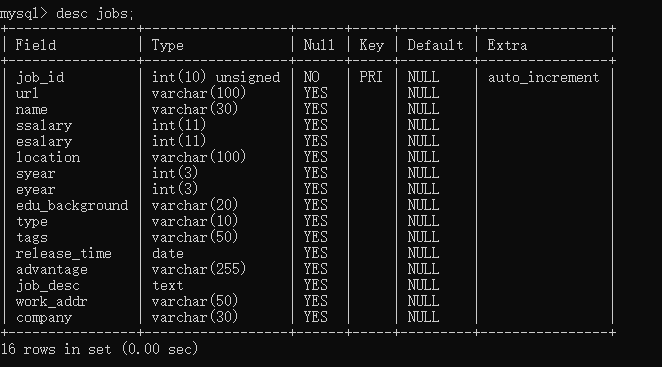
- 使用desc jobs;查看我们建立好的表。
- 开始写爬虫的代码,因为和mongodb的比较类似,我这里直接给出代码
import pymysql class MysqlPipeline(object):
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port @classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
) def open_spider(self, spider):
self.db = pymysql.connect(host=self.host, database=self.database, user=self.user, password=self.password, port=self.port, charset='utf8')
self.cursor = self.db.cursor() def process_item(self, item, spider):
’‘’
这里直接使用值传入也可以,我这里直接把item生成一个字典传入
‘’‘
data = dict(item)
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
#sql = 'insert into jobs (url,name,ssalary,esalary,location,syear,eyear,edu_background,type,tags,release_time,advantage,job_desc,work_addr,company) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
sql = 'insert into jobs (%s) values (%s)' % (keys,values)
try:
#self.cursor.execute(sql, (item['url'],item['name'],item['ssalary'],item['esalary'],item['location'],item['syear'],item['eyear'],item['edu_background'],item['type'],item['tags'],item['release_time'],item['advantage'],item['job_desc'],item['work_addr'],item['company']))
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
return item def close_spider(self, spider):
self.db.close()
- settings.py文件编写,增加mysql地址和端口等相关字段,并且激活MysqlPipeline
ITEM_PIPELINES = {
#'lagou.pipelines.LagouPipeline': 300,
#'lagou.pipelines.MongoPipeline': 300,
'lagou.pipelines.MysqlPipeline': 300,
}
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'lagou'
MYSQL_USER = 'root'
MYSQL_PASSWORD = ''
MYSQL_PORT = 3306
- 运行代码一段时间,用可视化工具打开看一下,发现数据已经存进来了

三、数据存储到本地csv文件
分析:因为已经对数据进行了处理,所以保存文件到本地不需要再到pipeline里面去进行。
使用命令行的方式:
- 运行爬虫时使用 scrapy crawl lagou_c -o lagou_jobs.csv,就可以保存一个名为lagou_jobs.csv文件到本地啦。
修改main.py文件的方式(本质上也是调用了命令行):
from scrapy import cmdline
cmdline.execute('scrapy crawl lagou_c -o lagou_jobs.csv'.split())
这样我们就分别完成了MongoDB,Mysql以及本地的存储。
scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- 怎样把一个DIV放到另一个div右下角
怎样把一个DIV放到另一个div右下角??? 借助CSS定位来实现,你将右下角的那个DIV放在另一个DIV里面,参考代码如下示: <div id="box1"> < ...
- HDU 1812 polya 大数
由于反射的存在,分奇偶讨论其置换的循环节数量,大数用JAVA就好了. import java.math.*; import java.util.*; public class Main{ public ...
- Python学习笔记(九)返回函数
摘抄:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014318352367 ...
- constant value too large
出错现场: .model small .data byte_var dw dup(-, dup()) .stack .code 将byte_var dw 'abc',10h,2 dup(-1,2 du ...
- SSM框架整合遇到的问题
1.Maven中Dubbo集成spring2.5以上版本 项目中dubbo集成spring4.x,配置pom时需要注意排除spring的依赖,我这里用的是tomcat,所以把jboss也排除了: &l ...
- 【BZOJ】3173: [Tjoi2013]最长上升子序列(树状数组)
[题意]给定ai,将1~n从小到大插入到第ai个数字之后,求每次插入后的LIS长度. [算法]树状数组||平衡树 [题解] 这是树状数组的一个用法:O(n log n)寻找前缀和为k的最小位置.(当数 ...
- HDU 1045 Fire Net (深搜)
题目链接 Problem DescriptionSuppose that we have a square city with straight streets. A map of a city is ...
- python笔记之BytesIO
1. 什么是BytesIO BytesIO与StringIO类似,不同的是StringIO只能存放string,BytesIO是用来存放bytes的,它提供了在内存中读写字节的能力. 即在内存中读写字 ...
- 28 - 生成器交互-__slots__-未实现异常
目录 1 生成器交互 2 slots 3 未实现和未实现异常 4 Python的对象模型 1 生成器交互 生成器提供了一个send方法用于动态的和生成器对象进行交互.怎么理解的呢?看下面的例子: de ...
- 64_s3
sugar-toolkit-gtk3-devel-0.110.0-2.fc26.i686.rpm 13-Feb-2017 10:56 22626 sugar-toolkit-gtk3-devel-0. ...