自然语言处理(二)——PTB数据集的预处理
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: word_deal1.py
@time: 2019/2/20 10:42
@desc: 首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
""" import codecs
import collections
from operator import itemgetter # 训练集数据文件
RAW_DATA = "./simple-examples/data/ptb.train.txt"
# 输出的词汇表文件
VOCAB_OUTPUT = "ptb.vocab" # 统计单词出现的频率
counter = collections.Counter()
with codecs.open(RAW_DATA, "r", "utf-8") as f:
for line in f:
for word in line.strip().split():
counter[word] += 1 # 按照词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt] # 稍后我们需要在文本换行处加入句子结束符“<eos>”,这里预先将其加入词汇表。
sorted_words = ["<eos>"] + sorted_words
# 在后面处理机器翻译数据时,出了"<eos>",还需要将"<unk>"和句子起始符"<sos>"加入
# 词汇表,并从词汇表中删除低频词汇。在PTB数据中,因为输入数据已经将低频词汇替换成了
# "<unk>",因此不需要这一步骤。
# sorted_words = ["<unk>", "<sos>", "<eos>"] + sorted_words
# if len(sorted_words) > 10000:
# sorted_words = sorted_words[:10000] with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + "\n")
运行结果:

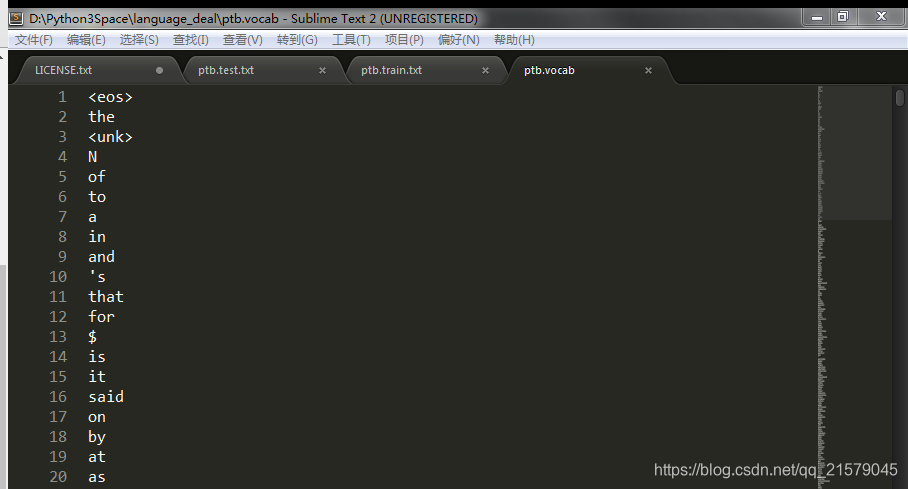
在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: word_deal2.py
@time: 2019/2/20 11:10
@desc: 在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
""" import codecs
import sys # 原始的训练集数据文件
RAW_DATA = "./simple-examples/data/ptb.train.txt"
# 上面生成的词汇表文件
VOCAB = "ptb.vocab"
# 将单词替换成为单词编号后的输出文件
OUTPUT_DATA = "ptb.train" # 读取词汇表,并建立词汇到单词编号的映射。
with codecs.open(VOCAB, "r", "utf-8") as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))} # 如果出现了被删除的低频词,则替换为"<unk>"。
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id["<unk"] fin = codecs.open(RAW_DATA, "r", "utf-8")
fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8')
for line in fin:
# 读取单词并添加<eos>结束符
words = line.strip().split() + ["<eos>"]
# 将每个单词替换为词汇表中的编号
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
运行结果:
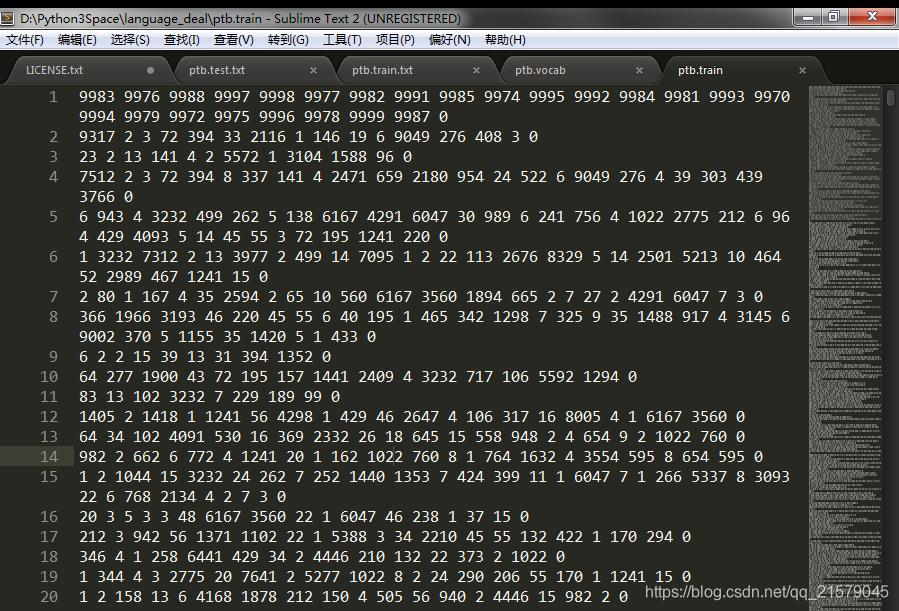
自然语言处理(二)——PTB数据集的预处理的更多相关文章
- c语言学习之基础知识点介绍(二十):预处理指令
一.预处理指令的介绍 预处理命令:在编译之前触发的一系列操作(命令)就叫预处理命令. 特点:以#开头,不要加分号. #include: 文件包含指令 把指定文件的内容复制到相应的位置 #define: ...
- TensorFlow数据集(二)——数据集的高层操作
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 一个使用数据集进行训练和测试的完整例子. #!/usr/bin/env python # -*- coding: ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:PTB 语言模型
import numpy as np import tensorflow as tf # 1.设置参数. TRAIN_DATA = "F:\TensorFlowGoogle\\201806- ...
- R语言实战读书笔记(二)创建数据集
2.2.2 矩阵 matrix(vector,nrow,ncol,byrow,dimnames,char_vector_rownames,char_vector_colnames) 其中: byrow ...
- AI-sklearn 学习笔记(二)数据集
from sklearn import datasets from sklearn.linear_model import LinearRegression loaded_data = dataset ...
- C#中的深度学习(二):预处理识别硬币的数据集
在文章中,我们将对输入到机器学习模型中的数据集进行预处理. 这里我们将对一个硬币数据集进行预处理,以便以后在监督学习模型中进行训练.在机器学习中预处理数据集通常涉及以下任务: 清理数据--通过对周围数 ...
- LUNA16数据集(三)预处理
在(一)和(二)中简单介绍了LUNA16数据集的组成,以及肺结节的可视化,有了对数据集的基本了解后,还要对数据集进行预处理,计算机视觉中原始数据一般不会直接送入神经网络,这里也是如此. 这篇博客想写已 ...
- 自然语言处理(五)——实现机器翻译Seq2Seq完整经过
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 我只能说这本书太烂了,看完这本书中关于自然语言处理的内容,代码全部敲了一遍,感觉学的很绝望,代码也运行不了. 具体 ...
- 用tensorflow实现自然语言处理——基于循环神经网络的神经语言模型
自然语言处理和图像处理不同,作为人类抽象出来的高级表达形式,它和图像.声音不同,图像和声音十分直觉,比如图像的像素的颜色表达可以直接量化成数字输入到神经网络中,当然如果是经过压缩的格式jpeg等必须还 ...
随机推荐
- Transforming Auto-encoders
http://www.cs.toronto.edu/~hinton/absps/transauto6.pdf The artificial neural networks that are used ...
- RNN 的入门程序DEMO
1.视频介绍 https://www.youtube.com/watch?v=cdLUzrjnlr4 2. https://github.com/llSourcell/recurrent_neural ...
- Ace(一)环境搭建
1.下载ACE源码代码 http://www.cs.wustl.edu/~schmidt/ACE.html 2.编译源代码 2.1 进入源码包解压后的ACE_wrappers\ace目录, ...
- valid No such filter: 'drawtext'"
libfreetype is missing. You'll have to rebuild FFmpeg with this library or disable overlays. --enabl ...
- the art of seo(chapter three)
SEO Planning: Customizing Your Strategy ***Developing an SEO Plan Prior to Site Development***Determ ...
- hdu 1029 Ignatius and the Princess IV(排序)
题意:求出现次数>=(N+1)/2的数 思路:排序后,输出第(N+1)/2个数 #include<iostream> #include<stdio.h> #include ...
- IO多路复用模型之select()函数详解
IO复用 我们首先来看看服务器编程的模型,客户端发来的请求服务端会产生一个进程来对其进行服务,每当来一个客户请求就产生一个进程来服务,然而进程不可能无限制的产生,因此为了解决大量客户端访问的问题,引入 ...
- PID736(rqnoj)
题目描述 n个小伙伴(编号从 0 到 n-1)围坐一圈玩游戏.按照顺时针方向给 n个位置编号,从 0 到 n-1.最初,第 0 号小伙伴在第0号位置,第1号小伙伴在第1号位置,依此类推. 游戏规则如下 ...
- C#视频取帧图
由于项目里页面有许多视频资料需要展示给用户查看,因此需要做一个视频列表,原设计是列表显示视频第一帧图,但实际上很多视频第一帧是纯黑底色. 于是想到用js利用canvas截图,最后发现由于浏览器跨域限制 ...
- 使用 StoryBoard 制作一个能够删除cell的TableView
本篇博客方便自己检索使用.资源链接 下面是制作效果图,点击删除按钮,就能将该cell删除: 下面是主要的代码: #define KSUPER_TAG 20000 #define KDEFAU_TAG ...