ElasticSearch(二)核心概念
elasticsearch核心概念
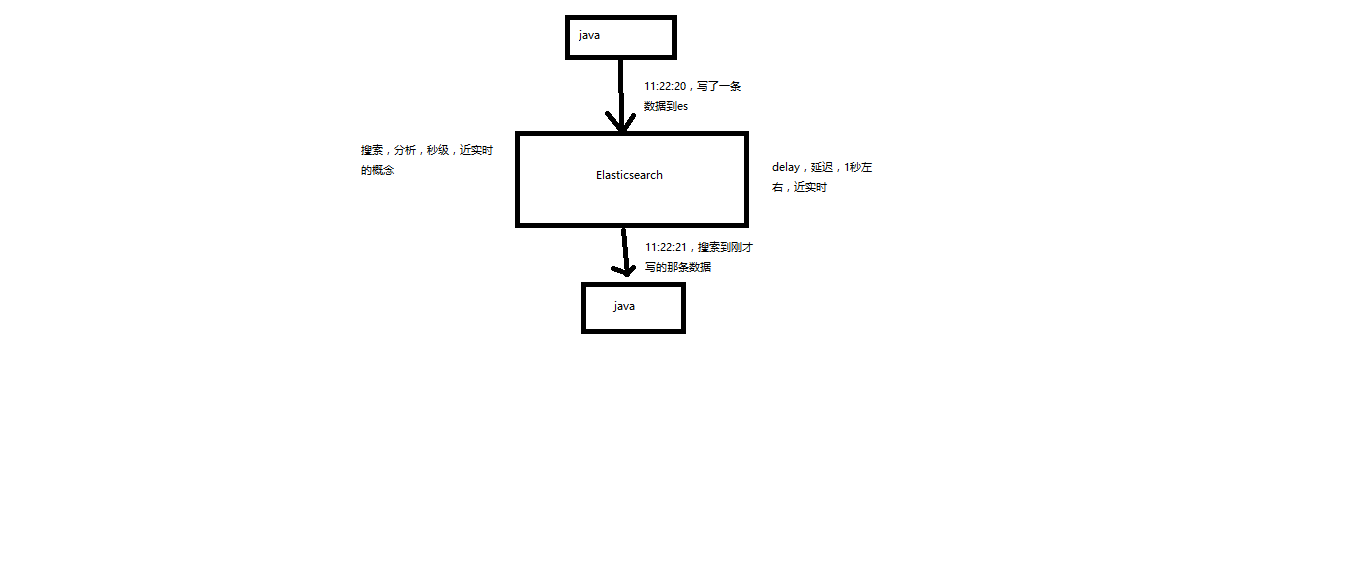
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(6)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
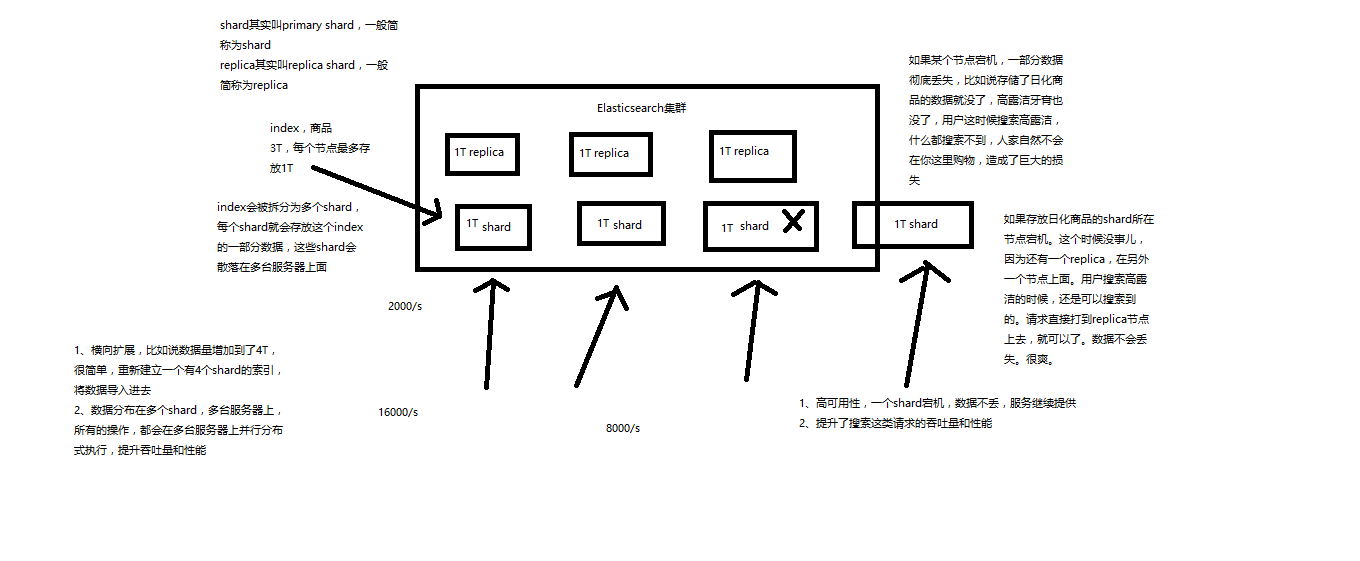
(7)shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。
primary shard(建立索引时一次设置,不能修改,默认5个),副本(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
----------------------------------------------------------------------------------------------------------------------------------------
elasticsearch核心概念 vs. 数据库核心概念
Elasticsearch 数据库
-----------------------------------------
field 字段
Document 行
Type 表
Index 库
shard 和replica:
near realtime(nrt):
shard&replica机制
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载(读请求承担负载)
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1(这边1的意思是,每个primary shard对应有1个replica shard,所以默认是10个shard),默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
(9)设置index有3个primary shard,3个replica shard
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
ElasticSearch(二)核心概念的更多相关文章
- elasticsearch的核心概念
1.elasticsearch的核心概念 (1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒):基于es执行搜索和分析可以达到秒级 (2) ...
- 图解Elasticsearch的核心概念
本文讲解大纲,分8个核心概念讲解说明: NRT Cluster Node Document&Field Index Type Shard Replica Near Realtime(NRT)近 ...
- fusionjs 学习二 核心概念
核心概念 middleware 类似express 的中间件模型(实际上是构建在koa中间件模型上的),但是和koa 的中间件有差异 fusionjs 的中间件同时可以运行在浏览器页面加载的时候 se ...
- 【ShardingSphere】ShardingSphere学习(二)-核心概念-SQL
逻辑表 水平拆分的数据库(表)的相同逻辑和数据结构表的总称. 例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order. 真实表 在分片的数 ...
- 剖析ElasticSearch核心概念,NRT,索引,分片,副本等
ElasticSearch 的核心概念 Near RealTime(NRT) 近实时 近实时有两种意思,一种是从写入数据到可以被搜索到有一个小延迟(大概一秒),还有一种就是基于ElasticSearc ...
- Elasticsearch入门教程(二):Elasticsearch核心概念
原文:Elasticsearch入门教程(二):Elasticsearch核心概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:ht ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch学习笔记(六)核心概念和分片shard机制
一.核心概念 1.近实时(Near Realtime NRT) (1)从写入数据到数据可以被搜索到有一个小延迟(大概1秒): (2)基于es执行搜索和分析可以达到秒级 2.集群(Cluster) 一个 ...
- ElasticSearch 全文检索— ElasticSearch 核心概念
ElasticSearch核心概念-Cluster 1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是去中心化,字 ...
随机推荐
- iOS8下定位问题解决
项目是以前iOS7的,升级iOS8后,无法成功获取用户位置.后来才发现iOS8 使用定位需要在infoplist文件中加2个key,然后manager需要加一个方法,指定定位授权机制 在plist ...
- UICollectionView的cell创建直接从第三个数据开始问题
实现的效果是这样 大概意思就是第一组没有数据就直接将改组的cell高度变成0效果实现了,但是第二组数据创建cell就出问题了--奇葩问题 * 代码问题在这```-(CGSize)collectionV ...
- 牛客网 牛客练习赛11 A.假的线段树
看不懂题意,而且太菜,写了两道就溜了... A.假的线段树 链接:https://www.nowcoder.com/acm/contest/59/A来源:牛客网 时间限制:C/C++ 1秒,其他语言2 ...
- SourceTree免注册并连码云
1 在C:\Users\用户\AppData\Local\Atlassian\SourceTree目录下新建 accounts.json 其中AppData是隐藏文件夹 2 输入 [ { " ...
- Spring Cloud系列文,Feign整合Ribbon和Hysrix
在本博客之前的Spring Cloud系列里,我们讲述了Feign的基本用法,这里我们将讲述下Feign整合Ribbon实现负载均衡以及整合Hystrix实现断路保护效果的方式. 1 准备Eureka ...
- 洛谷——P2701 [USACO5.3]巨大的牛棚Big Barn
P2701 [USACO5.3]巨大的牛棚Big Barn 题目背景 (USACO 5.3.4) 题目描述 农夫约翰想要在他的正方形农场上建造一座正方形大牛棚.他讨厌在他的农场中砍树,想找一个能够让他 ...
- Ural 1774 Barber of the Army of Mages 最大流
题目链接:http://acm.timus.ru/problem.aspx?space=1&num=1774 1774. Barber of the Army of Mages Time li ...
- 在spring中使用数据库
若要在spring中使用数据库,首先需要配置数据源. 1.使用数据源连接池,可以使用DBCP(Data Base Connection Pooling) <bean id="datas ...
- javascript --- 递归的简单理解
递归函数大家都应该比较熟吧?那么,如何在JavaScript中书写一个完美的递归函数呢?且听我娓娓道来. 递归函数 写的时候,查了一下维基百科对递归函数的定义,恕我愚钝,简直太深奥了!所以,我还是简单 ...
- 手动安装windows的磁盘清理工具
All you really need to do is copy some files that are already located on your server into specific s ...