分布式Hadoop安装(二)
二、集群环境安装Zookeeper
1. hadoop0,namenode机器下,配置zookeeper,先解压安装包。
使用命令:tar -zxvf zookeeper-3.4.4.tar.gz
2. Hadoop0,配置zookeeper的环境变量
a) 打开/etc/profile,增加并修改如下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH:$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
3. 进入zookeeper的配置目录,首先把zoo_sample.cfg重命名一下,可以重新复制一遍。
使用命令:cp zoo_sample.cfg zoo.cfg
4. 修改配置zoo.cfg,修改添加如下内容:
dataDir=/usr/local/zookeeper/data
server.=hadoop0::
server.=hadoop1::
dataDir用于存放第5步的myid文件
Hadoop0、hadoop1分别是主机名,节点数量最好是奇数;
2888端口,是从机器(follower)连接到主机器(leader)的端口号;
端口3888,是进行leadership选举的端口号;
注意,如果是在一台机器上搭建,则应避免端口冲突。
5. dataDir所指定的目录下创建一个文件名为myid的文件
文件中的内容只有一行,为本主机对应的id值,也就是第4步中server.id中的id。例如:在hadoop0中的myid的内容应该写入0。
6. 将配置好的zookeeper安装文件及profile远程复制分发
scp –rq /usr/local/zookeeper hadoop1:/usr/local
scp –rq /etc/profile hadoop1:/etc
7. 拷贝完成后修改对应的机器上的myid。例如修改hadoop1中的myid为1
8. 启动ZooKeeper集群,在每一个节点上执行命令zkServer.sh start
9. Jps验证,每个阶段均,输出如下结果:
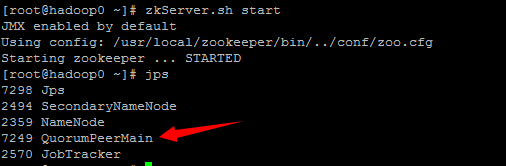
其中,QuorumPeerMain是zookeeper进程,启动正常。
10. 其他常用命令:
a) 查看集群中角色的命令(或是Leader,或是Follower):zkServer.sh status
b) 客户端连接zookeeper:zkCli.sh –server hadoop0:2181,客户端成功后,可通过如下命令操作zk

ls(查看当前节点数据),
ls2(查看当前节点数据并能看到更新次数等数据) ,
create(创建一个节点) ,
get(得到一个节点,包含数据和更新次数等数据),
set(修改节点)
delete(删除一个节点)
c) 停止zookeeper进程:zkServer.sh stop
分布式Hadoop安装(二)的更多相关文章
- 分布式Hadoop安装(一)
本文旨在介绍通过两台物理节点,实现完全分布式hadoop程序的部署 writen by Bob Pan@20140609 环境介绍: 主机名 机器IP 用途 描述 Hadoop0 192.168.80 ...
- VMwareWorkstation 平台 Ubuntu14 下安装配置 伪分布式 hadoop
VMwareWorkstation平台Ubuntu14下安装配置伪分布式hadoop 安装VmwareStation 内含注册机. 链接:https://pan.baidu.com/s/1j-vKgD ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- hadoop完全分布式手动安装(一主多从centos linux各版本均试验成功,文档完整无一遗漏)
hadoop完全分布式手动安装(一主多从centos linux各版本均试验成功,文档完整无一遗漏) 网上的文章99%都是垃圾,我凭良心书写,确保幼儿园同学也能安装成功! 查看系统环境 1.查看 ...
- Hadoop全分布式模式安装
一.准备 1.准备至少三台linux服务器,并安装JDK 关闭防火墙如下 systemctl stop firewalld.service systemctl disable firewalld.se ...
- CentOS7 Hadoop 安装(完全分布式)
一.hadoop集群安装模式 单机模式 直接解压,无需任何配置.主要用于测试代码.没有分布式文件系统. 伪分布式 完全分布式的一种形式,只是所有的进程都配置要一个节点上.有分布式文件系统,只不 ...
- 避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述) 安装成功之后 输入 输入:java -version 显示如下说明jdk安装成功(我这里是安装JDK8) 二.安装Hadoop3. ...
- Hadoop安装教程_分布式
Hadoop的分布式安装 hadoop安装伪分布式以后就可以进行启动和停止操作了. 首先需要格式化HDFS分布式文件系统.hadoop namenode -format 然后就可以启动了.start- ...
随机推荐
- hibernate报错及解决方式
1 java.sql.BatchUpdateException: ORA-01438: 值大于为此列指定的允许精度 原因:pl/sql number(n),插入的位数大于n
- 10个超级有用、必须收藏的PHP代码样例
在PHP的流行普及中,网上总结出了很多实用的PHP代码片段,这些代码片段在当你遇到类似的问题时,粘贴过去就可以使用,非常的高效,非常的省时省力.将这些程序员前辈总结出的优秀代码放到自己的知识库中,是一 ...
- 配置Windows 2008 R2 64位 Odoo 8.0 源码PyCharm开发调试环境
安装过程中,需要互联网连接下载python依赖库: 1.安装: Windows Server 2008 R2 x64标准版 2.安装: Python 2.7.10 amd64 到C:\Python27 ...
- csc一些命令简记
C#在命令行进行编译的一些命令: csc使用详解 @echo off cd / cd C:\Program Files (x86)\MSBuild\12.0\Bin set /p var= 请输入文件 ...
- ubuntu adobe flash player 安装
常规做法 1.先更新sudo apt-get update 2. sudo apt-get install flashplugin-installer 这次却卡在downloading这里 下不去.无 ...
- Asp.Net Web API 2第五课——Web API路由
Asp.Net Web API 导航 Asp.Net Web API第一课——入门 http://www.cnblogs.com/aehyok/p/3432158.html Asp.Net Web ...
- 使用 New Relic 监控接口服务性能
偶然看到贴子在使用[Rails API] 使用这个APM监控,今天试了下.NET IIS环境下,配置一路NEXT即可. 主要指标 服务响应时间 Segment SQL执行时间 安全问题 1.走HTTP ...
- 使用tornado和angularjs搭建网站
从这篇博文开始,将讲述建立一个站点的全过程.一方面自己从未做过这类事情,算是对自己的一个挑战,另一方面也给想要学这个的同胞留点参考,特别是*需要课程设计作业和毕业设计的同志们*. 首先介绍一下网站功能 ...
- We are doomed, and RPC does not help
第一种死法:Big ball of Mud 架构里最常用的反面案例是 big ball of mud.很大程度上可以说打格子,把复杂的系统拆解成小格子是架构师最重要的工作.这个小格子有很多种名字,比如 ...
- Jenkins2 - 下载与启动
文章来自:http://www.ciandcd.com 文中的代码来自可以从github下载: https://github.com/ciandcd 本文将引导jenkins初学者安装和配置jenki ...