机器学习:逻辑回归(OvR 与 OvO)
一、基础理解
- 问题:逻辑回归算法是用回归的方式解决分类的问题,而且只可以解决二分类问题;
- 方案:可以通过改造,使得逻辑回归算法可以解决多分类问题;
- 改造方法:
- OvR(One vs Rest),一对剩余的意思,有时候也称它为 OvA(One vs All);一般使用 OvR,更标准;
- OvO(One vs One),一对一的意思;
- 改造方法不是指针对逻辑回归算法,而是在机器学习领域有通用性,所有二分类的机器学习算法都可使用此方法进行改造,解决多分类问题;
二、原理
1)OvR
- 思想:n 种类型的样本进行分类时,分别取一种样本作为一类,将剩余的所有类型的样本看做另一类,这样就形成了 n 个二分类问题,使用逻辑回归算法对 n 个数据集训练出 n 个模型,将待预测的样本传入这 n 个模型中,所得概率最高的那个模型对应的样本类型即认为是该预测样本的类型;
- 时间复杂度:如果处理一个二分类问题用时 T,此方法需要用时 n.T;
2)OvO
- 思想: n 类样本中,每次挑出 2 种类型,两两结合,一共有 Cn2 种二分类情况,使用 Cn2 种模型预测样本类型,有 Cn2 个预测结果,种类最多的那种样本类型,就认为是该样本最终的预测类型;

- 时间复杂度:如果处理一个二分类问题用时 T,此方法需要用时 Cn2 .T = [n.(n - 1) / 2] . T;
3)区别
- OvO 用时较多,但其分类结果更准确,因为每一次二分类时都用真实的类型进行比较,没有混淆其它的类别;
三、scikit-learn 中的逻辑回归
- scikit-learn的LogisticRegression 算法内包含了:正则化、优化损失函数的方法、多分类方法等;
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)# LogisticRegression() 实例对象,包含了很多参数;
不懂的要学会 看文档、看文档、看文档:help(算法、实例对象);
C=1.0:正则化的超参数,默认为 1.0;
- multi_class='ovr':scikit-learn中的逻辑回归默认支持多分类问题,分类方式为 'OvR';
- solver='liblinear'、'lbfgs'、'sag'、'newton-cg':scikit-learn中优化损失函数的方法,不是梯度下降法;
- 多分类中使用 multinomial (OvO)时,只能使用 'lbfgs'、'sag'、'newton-cg' 来优化损失函数;
- 当损失函数使用了 L2 正则项时,优化方法只能使用 'lbfgs'、'sag'、'newton-cg';
- 使用 'liblinear' 优化损失函数时,正则项可以为 L1 和 L2 ;
1)例(3 种样本类型):LogisticRegression() 默认使用 OvR
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets iris = datasets.load_iris()
# [:, :2]:所有行,0、1 列,不包含 2 列;
X = iris.data[:,:2]
y = iris.target from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression()
log_reg.fit(X_train, y_train) log_reg.score(X_test, y_test)
# 准确率:0.6578947368421053- 绘制决策边界
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(log_reg, axis=[4, 8.5, 1.5, 4.5])
# 可视化时只能在同一个二维平面内体现两种特征;
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()
2)使用 OvO 分类
log_reg2 = LogisticRegression(multi_class='multinomial', solver='newton-cg')
# 'multinomial':指 OvO 方法; log_reg2.fit(X_train, y_train)
log_reg2.score(X_test, y_test)
# 准确率:0.7894736842105263 plot_decision_boundary(log_reg2, axis=[4, 8.5, 1.5, 4.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()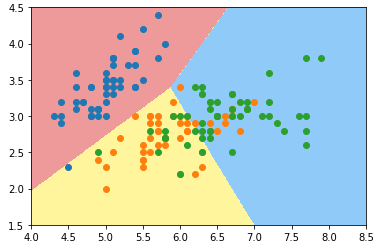
3)使用所有分类数据
- OvR
X = iris.data
y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) log_reg_ovr = LogisticRegression()
log_reg_ovr.fit(X_train, y_train)
log_reg_ovr.score(X_test, y_test)
# 准确率:0.9473684210526315 - OvO
log_reg_ovo = LogisticRegression(multi_class='multinomial', solver='newton-cg')
log_reg_ovo.fit(X_train, y_train)
log_reg_ovo.score(X_test, y_test)
# 准确率:1.0
4)分析
- 通过准确率对比可以看出,使用 OvO 方法改造 LogisticRegression() 算法,得到的模型准确率较高;
四、OvR 和 OvO 的封装
- scikit-learn单独封装了实现 OvO 和 OvR 的类,使得任意二分类算法都可以通过使用这两个类解决多分类问题;
1)OvR 的封装
- 模块
from sklearn.multiclass import OneVsRestClassifier
- 使用方法
- ovr = OneVsRestClassifier(二分类算法的实例对象):得到一个可以解决多分类的实例对象;
- ovr.fit(X_train, y_train):拟合多分类实例对象;
- 例
from sklearn.multiclass import OneVsRestClassifier ovr = OneVsRestClassifier(log_reg)
ovr.fit(X_train, y_train)
ovr.score(X_test, y_test)
# 准确率:0.9473684210526315
2)OvO 的封装
- 模块
from sklearn.multiclass import OneVsOneClassifier
- 使用方法:同理 OvR;
- 例
from sklearn.multiclass import OneVsOneClassifier ovo = OneVsOneClassifier(log_reg)
ovo.fit(X_train, y_train)
ovo.score(X_test, y_test)
# 准确率:1.0
机器学习:逻辑回归(OvR 与 OvO)的更多相关文章
- 机器学习---逻辑回归(二)(Machine Learning Logistic Regression II)
在<机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)>一文中,我们讨论了如何用逻辑回归解决二分类问题以及逻辑回归算法的本质.现在 ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- 机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)
逻辑回归(Logistic Regression)是一种经典的线性分类算法.逻辑回归虽然叫回归,但是其模型是用来分类的. 让我们先从最简单的二分类问题开始.给定特征向量x=([x1,x2,...,xn ...
- 机器学习——逻辑回归(Logistic Regression)
1 前言 虽然该机器学习算法名字里面有"回归",但是它其实是个分类算法.取名逻辑回归主要是因为是从线性回归转变而来的. logistic回归,又叫对数几率回归. 2 回归模型 2. ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- python机器学习-逻辑回归
1.逻辑函数 假设数据集有n个独立的特征,x1到xn为样本的n个特征.常规的回归算法的目标是拟合出一个多项式函数,使得预测值与真实值的误差最小: 而我们希望这样的f(x)能够具有很好的逻辑判断性质,最 ...
- Spark 机器学习------逻辑回归
package Spark_MLlib import javassist.bytecode.SignatureAttribute.ArrayType import org.apache.spark.s ...
- python机器学习——逻辑回归
我们知道感知器算法对于不能完全线性分割的数据是无能为力的,在这一篇将会介绍另一种非常有效的二分类模型--逻辑回归.在分类任务中,它被广泛使用 逻辑回归是一个分类模型,在实现之前我们先介绍几个概念: 几 ...
- 机器学习-逻辑回归与SVM的联系与区别
(搬运工) 逻辑回归(LR)与SVM的联系与区别 LR 和 SVM 都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题,如LR的Softmax回归用在深度学习的多分类 ...
- 逻辑回归模型(Logistic Regression, LR)基础
逻辑回归模型(Logistic Regression, LR)基础 逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函 ...
随机推荐
- INSPIRED启示录 读书笔记 - 第28章 创业型公司的产品管理
产品设计方式 第一步:创业初期只设三个职位,产品经理.交互设计师和原型开发人员(职位可以兼任) 第二步:快速展开产品设计(高保真原型),邀请真实的目标用户验证产品原型,迭代修改 第三步:随着迭代的深入 ...
- QT 布局时使用 addStretch 可伸缩设置
今天在使用addStretch,布局的时候,发现addStretch竟然是可以平均分配的,有意思.比如: QVBoxLayout *buttonLayout = new QVBoxLayout; bu ...
- spring:使用会话和请求作用域
在Web应用中,如果能够实例化在会话和请求范围内共享的bean,那将是非常有价值的事情.例如,在典型的电子商务应用中,可能会有一个bean代表用户的购物车.如果购物车是单例的话,那么将会导致所有的用户 ...
- c#加密,java解密(3DES加密)
c#代码 using System; using System.Security; using System.Security.Cryptography; using System.IO; using ...
- Mac的搜狗输入法和QQ输入法加入⌘⌥⌃⇧自定义短语
搜狗输入法(Mac):http://pinyin.sogou.com/mac/ 创建名为『搜狗输入法自定义短语.ini』的文本文件(建议用Sublime Text),内容如下,然后偏好设置的自定义短语 ...
- hdu 2490 队列优化dp
http://acm.hdu.edu.cn/showproblem.php?pid=2490 Parade Time Limit: 4000/2000 MS (Java/Others) Memo ...
- svg札记
1.人老了,有些事情太容易忘记了,这里做下笔记,供参考,for self for you. 2.源于地图监控,建筑级别各大地图商的api(高德.百度.腾讯等)已经足够使用,唯独室内图这块还差点. 3. ...
- iOS-使用ALAssetsLibrary获取相册图片视频
用ALAssetsLibrary获取相册图片视频 ALAssetsLibrary *library = [[ALAssetsLibrary alloc] init]; [library enumera ...
- Vue在HTML页面中的脚手架
<script src="assets/js/vue.js"></script> <script src="assets/js/vue-re ...
- Rainmeter如何打开控制面板的小程序
控制面板功能都是通过访问cpl文件来关联它们的,假设你的系统盘在C盘,那么它们的本地在C:\Windows\System32\ Rainmeter通过使用这个应用程序C:\Windows\System ...