python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现。
首先还是上代码:
# -*- coding:utf-8 -*-
import requests
import re
import mysql.connector #changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text) finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址 #getdownurl获取页面的视频地址和信息
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码 pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0] pat2 = re.compile('<!--Content Start-->(.*?)<!--duguPlayList Start-->',re.S)#获取影片信息
reslist2 = re.findall(pat2, req.text)
reslist3 = re.sub('[<p></p>]','',reslist2[0])
fdetail = reslist3.split('◎') return (furl,fdetail) #创建表movies
def createtable(con,cs):
#创建movies表,确定其表结构:
cs.execute('create table if not exists movies (film_addr varchar(1000), cover_pic varchar(1000), name varchar(100) primary key,\
ori_name varchar(100),prod_year varchar(100), prod_country varchar(100), category varchar(100), language varchar(100), \
subtitle varchar(100), release_date varchar(100), score varchar(100), file_format varchar(100), video_size varchar(100), \
file_size varchar(100), film_length varchar(100), director varchar(100), actors varchar(500), profile varchar(2000),capt_pic varchar(1000))')
# 提交事务:
con.commit() #将电影地址和简介插入表中
def inserttable(con,cs,x,y):
try:
cs.execute('insert into movies values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)',\
(x,y[0],y[1],y[2],y[3],y[4],y[5],y[6],y[7],y[8],y[9],y[10],y[11],y[12],y[13],y[14],y[15],y[16],y[17]))
except:
pass
finally:
con.commit() if __name__ == "__main__" :
html = "https://www.dygod.net/html/gndy/jddy/index.html"
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
createtable
p1 = changepage(html,int(pages)) #打开数据库
conn = mysql.connector.connect(user='py', password='Unix_1234', database='py_test')
cursor = conn.cursor()
createtable(conn,cursor)
#插入数据
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3,p4 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
inserttable(conn,cursor,p3,p4)
#关闭数据库
cursor.close()
conn.close()
print('所有页面地址爬取完毕!')
用到的知识点和前面比,最重要是多了数据库的操作,下面简要介绍下python如何连接数据库。
一、python中使用mysql需要驱动,常用的有官方的mysql-connect-python,还有mysqldb(Python 2.x)和pymysql(Python 3.x),这几个模块既是驱动,又是工具,可以用来直接操作mysql数据库,也就是说它们是通过在Python中写sql语句来操作的,例如创建user表:
cursor.execute('create table user (id int, name varchar(20))')
#这里的create table语句就是典型的sql语句。
二、还有很多情况下我们用ORM(object relational mapping)即对象映射关系框架,将编程语言的对象模型和数据库的关系模型(RDBMS关系型数据库)进行映射,这样可以直接使用编程语言的对象模型操作数据库,而不是使用sql语言。同样创建user表:
user=Table('user',metadata,
Column('id',Integer),
Column('name', String(20))
)
metadata.create_all()
#这里可以看到根本没有sql语句的影子,这样我们可以专注在Python代码而不是sql代码上了。(注意ORM并不包含驱动,如要使用同样要安装前面提到的驱动)
如有兴趣可以自行学习,这不是本文的重点。为简单起见,文中用的是mysql-connect-python。
正则匹配部分也很简单,因为源网页比较规则,如下网页图和对应的源代码:
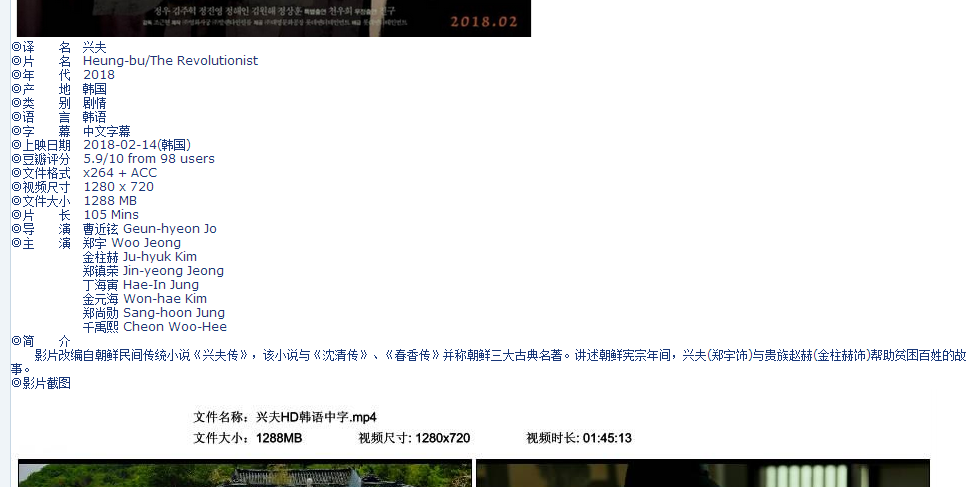
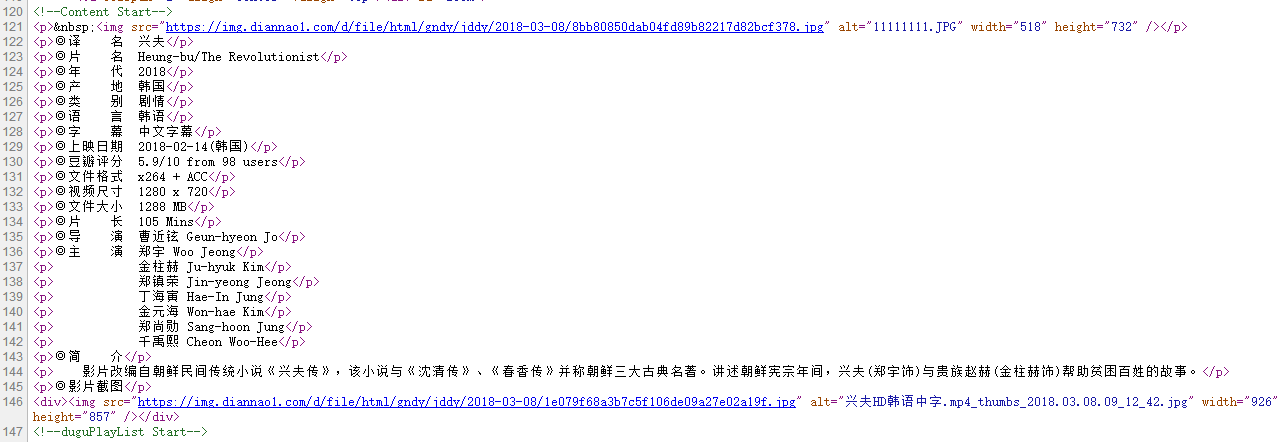
直接用◎匹配即可。
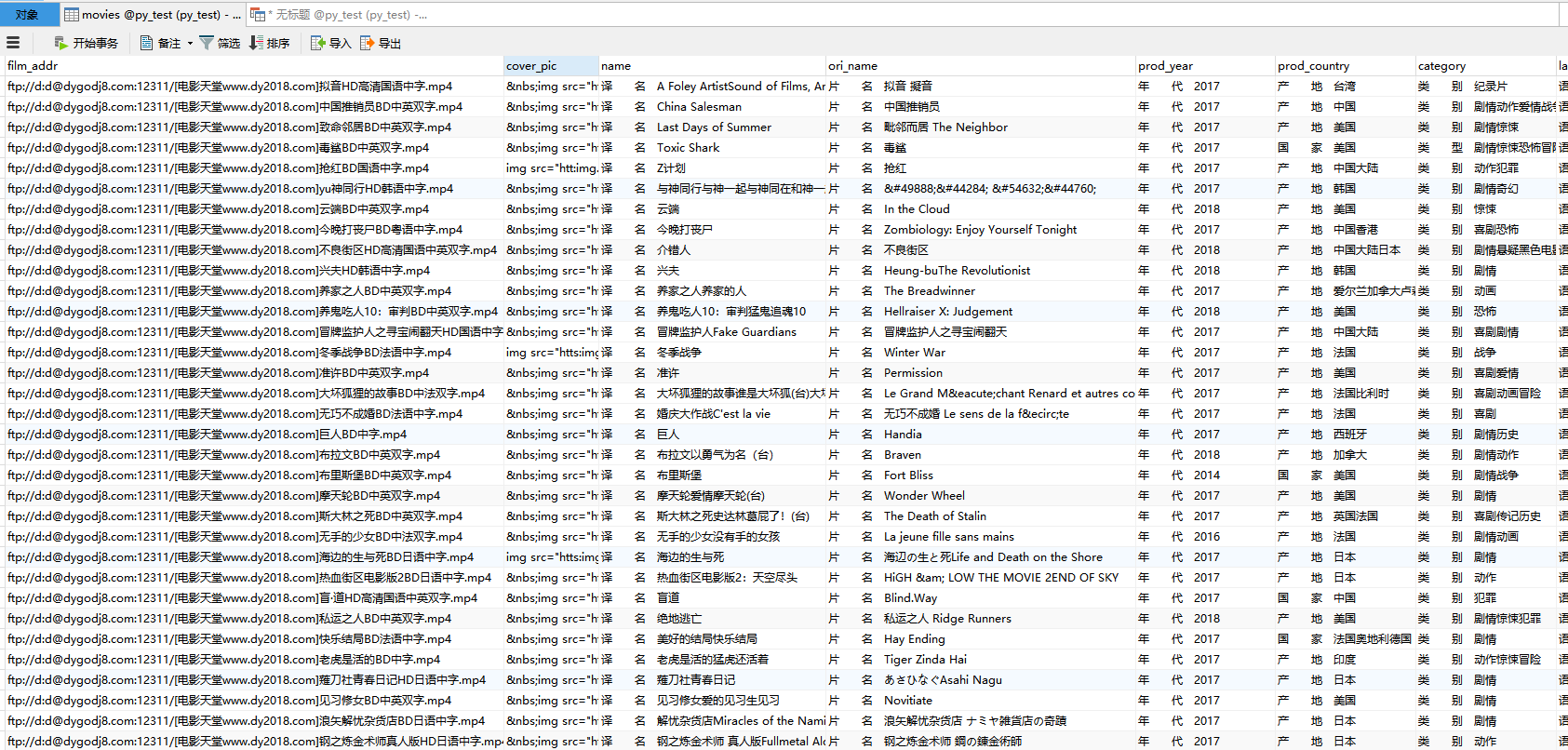
程序运行完后,数据都写入movies表中。
比如我想筛选豆瓣评分>7的,
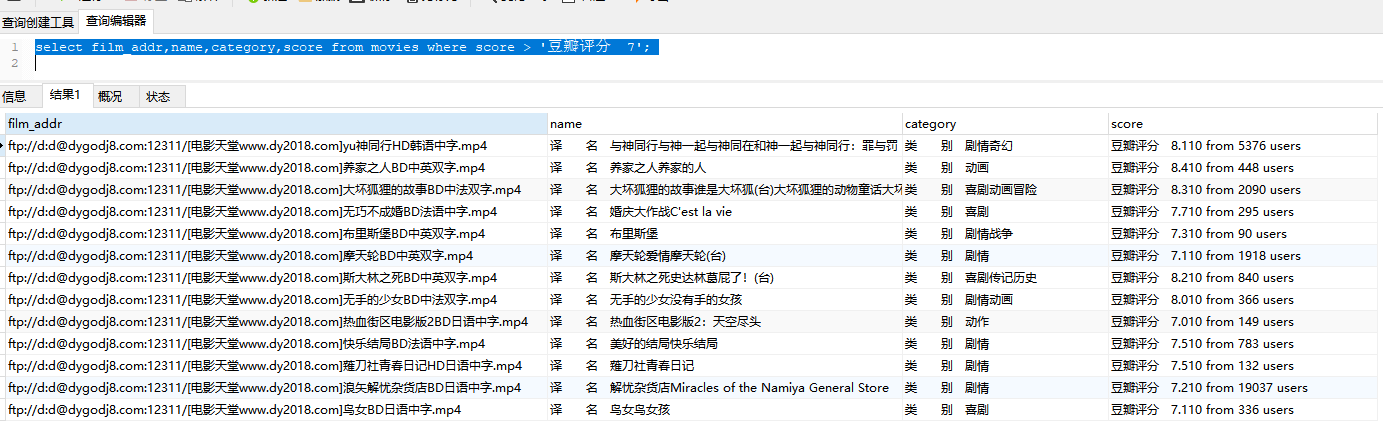
是不是很简单,你GET到了吗?
python爬虫--爬取某网站电影信息并写入mysql数据库的更多相关文章
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫爬取腾讯招聘信息 (静态爬虫)
环境: windows7,python3.4 代码:(亲测可正常执行) import requests from bs4 import BeautifulSoup from math import c ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- Python爬虫爬取一篇韩寒新浪博客
网上看到大神对Python爬虫爬到非常多实用的信息,认为非常厉害.突然对想学Python爬虫,尽管自己没学过Python.但在网上找了一些资料看了一下,看到爬取韩寒新浪博客的视频.共三集,第一节讲爬取 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 洛谷 [P1220] 关路灯
本题是一道区间DP,很容易设计出状态, dp[i][j]代表关掉i到j的路灯所耗的电量,但是对于新到一个路灯来说,可以是原来直接来的,也可以是掉头来的,于是还需要添加一维 0代表在区间的左端,1代表在 ...
- Openwrt上使用dnsmasq和ipset实现域名分流
目标 部署一台自动代理路由器,实现根据域名来自动设定直连或者代理,而我要做的只是设置PC的默认网关为主路由器(192.168.0.1)还是自动代理路由器(192.168.0.254). 创建Openw ...
- 洛谷P1171 售货员的难题【状压DP】
题目描述 某乡有n个村庄(1 输入格式: 村庄数n和各村之间的路程(均是整数). 输出格式: 最短的路程. 输入样例: 3 0 2 1 1 0 2 2 1 0 输出样例 3 说明 输入解释 3 {村庄 ...
- Vijos 1404 遭遇战
Vijos 1404 遭遇战 背景 你知道吗,SQ Class的人都很喜欢打CS.(不知道CS是什么的人不用参加这次比赛). 描述 今天,他们在打一张叫DUSTII的地图,万恶的恐怖分子要炸掉藏在A区 ...
- HashMap原理阅读
前言 还是需要从头阅读下HashMap的源码.目标在于更好的理解HashMap的用法,学习更精炼的编码规范,以及应对面试. 它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而 ...
- Dynamics CRM 2015-Ribbon In Basic Home Tab
前文中有说到关于Form上Ribbon的配置以及控制,而Ribbon Button还可以在其它地方的配置,今天就来说说在Basic Home Tab里面的配置,效果图如下: 具体配置Customiza ...
- appium+Python 启动app(三)登录
我们根据前面的知识点,用uiautomatorviewer工具来获取我们当前的元素 (注:uiautomatorviewer 是 android sdk 自带的) 知识点:appium的webdriv ...
- IE8兼容问题总结---trim()方法
1.IE8不支持,jquery的trim()去空格的方法 错误表现 : 会报错,对象不支持此属性或方法; 解决办法 : 使用正则匹配空格 例如 : /^\s+|\s+$/greplace(/^\s+| ...
- 以kaggle-titanic数据为基础的完整的机器学习
1. 引入所有需要的包 # -*- coding:utf-8 -*- # 忽略警告 import warnings warnings.filterwarnings('ignore') # 引入数据处理 ...
- Redis的两种持久化方式-快照持久化和AOF持久化
Redis为了内部数据的安全考虑,会把本身的数据以文件形式保存到硬盘中一份,在服务器重启之后会自动把硬盘的数据恢复到内存(redis)的里边,数据保存到硬盘的过程就称为"持久化"效 ...