python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍
爬取英文名:
一. 爬虫模块详细设计
(1)整体思路
对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个csv文件中;再读取csv文件当中的每个英文名链接,采用循环的方法读取每一个英文名链接,根据每个英文名链接爬取每个链接中的数据,保存在新的csv文件当中。
需要写一个爬取英文名链接的函数、将爬取的内容保存在csv文件的函数以及读取csv文件内容的函数、爬取英文名详情页内容的函数。
表5.3.1
|
函数名 |
作用 |
|
def get_nameLink(): |
爬取英文名链接 |
|
def save_to_csv(dict,filename): |
将爬取的内容以字典的形式保存在csv文件 |
|
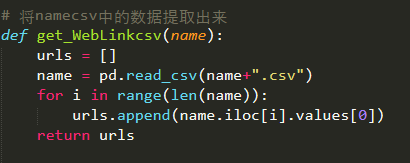
def get_WebLinkcsv(name): |
读取csv文件的内容 |
|
def get_namedata(): |
根据链接爬取每个英文名的具体数据 |
(2)爬取英文名链接
首先观察A-Z英文名的网页的内容,发现每个字母都对应一个网站,刚打开网站只会显示三个模块的英文名,每个模块30个英文名;关于一个字母的更多的英文名是根据鼠标的移动再进行动态的加载才会在网页上显示出来;但每个字母的英文名不同的网页上显示。如图:
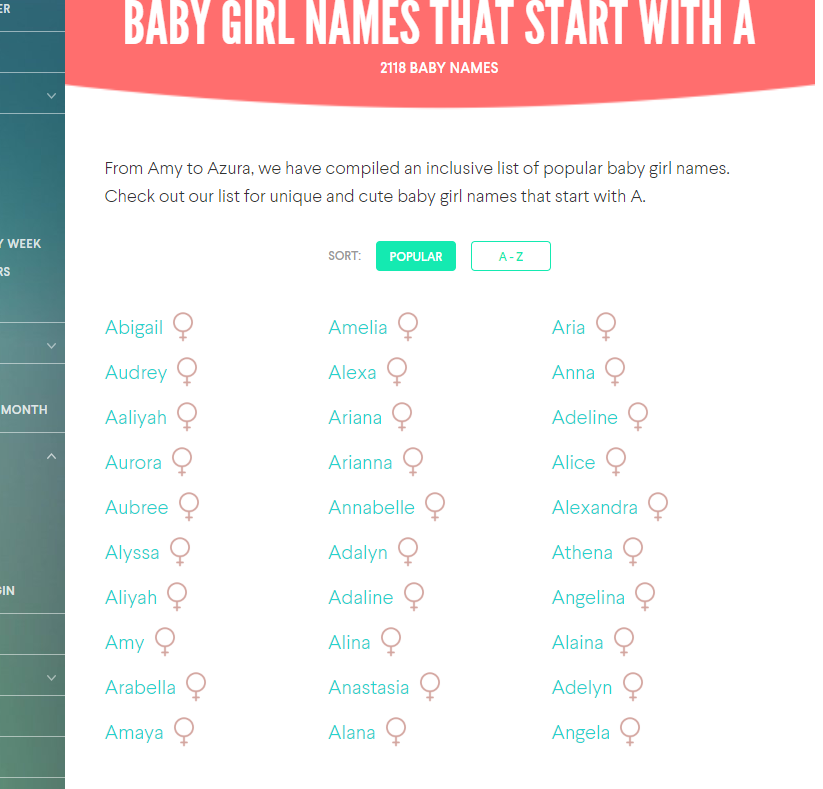
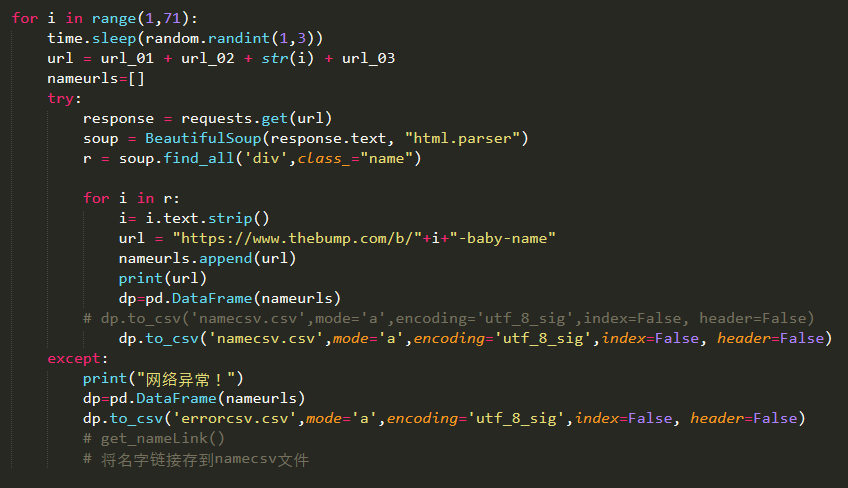
经观察,每个字母的所有英文名都可以根据页数来确定,可以不用动态爬取的方法,根据观察每个字母的英文名页数来确定每个字母英文名的数量进行爬取链接。链接格式为:
https://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajax=true
Letter表示A-Z的字母,number表示页数,page_size表示每个页面所显示的英文名数量为30个。
代码如下:

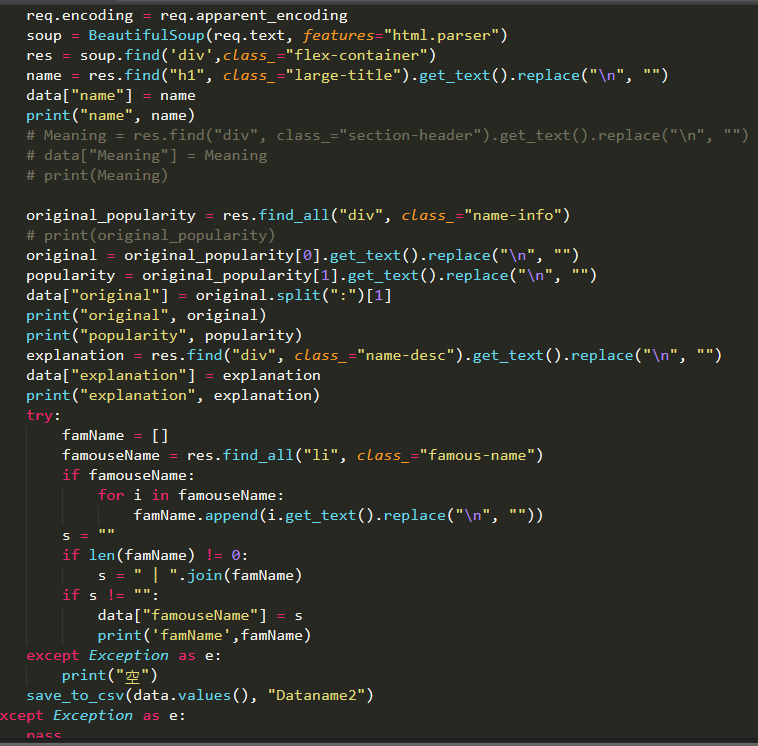
(3) 爬取详情页
打开某个英文名对应的详情页,右键点开查看需要爬取内容的审查元素,观察每个模块内容所对应的标签进行解析。经观察,有的英文名存在Celebrity模块,有的英文名不存在Celebrity模块,就需要进行判断,若存在就解析保存在csv文件中,不存在显示为空跳过,继续解析下一个内容。如图:
Abigail名字中就有Celebrity模块的内容,Annabelle名字中就没有这个Celebrity中的内容,这种情况下,就会存入空的内容。


代码如下:
采用try except进行异常处理。
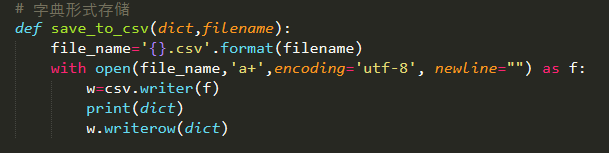
(4)存储内容
采用字典的形式存入内容保存在csv文件当中。字典(dictionary)是Python中另一个非常有用的内置数据类型,列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取;字典是一种映射类型,字典用“{ }”标识,它是一个无序的键(key)、值(value)对集合,键(key)必须使用不可变类型。
def save_to_csv(dict,filename)函数表示存储数据,使用字典形式存储,因为本次实验数据较大,不能一次性爬取,所以在爬取内容的时候都是分开爬的,对于数据的存储也是采用追加的方式进行存取的。
如图:
(5)读取文件
读取文件主要是用来读取名字链接,根据名字链接进行详情页的爬取
二. 调试与测试
(1) 调试过程中遇到的问题
(1)在爬取关于A的英文名链接的时候,只出现了90个链接,剩下的爬不出来,但在网页中剩下的英文名可以根据鼠标的滑动进行加载出现在网页中,经观察可以根据此链接https://www.thebump.com/b/baby-girl-names-that-start-with-{letter}?sort_by=popular&page={number}&page_size=30&gender=&request-by-ajax=true,进行获取每个英文名的爬取以及对每个字母的英文名数量进行确认;用此url形式就相当于是进行翻页操作,每一页只有30个英文名。
(2)在运行的过程中会显示缩紧错误,但在观察过程中,并没有缩进的错误,在网上查询得只是因为在定义一个函数时,函数里面没有内容才会报此错误。
(3)在进行几次爬取过程中,会经常在某一个固定的地方停止爬取,经多次修改,最终发现是请求头的问题。
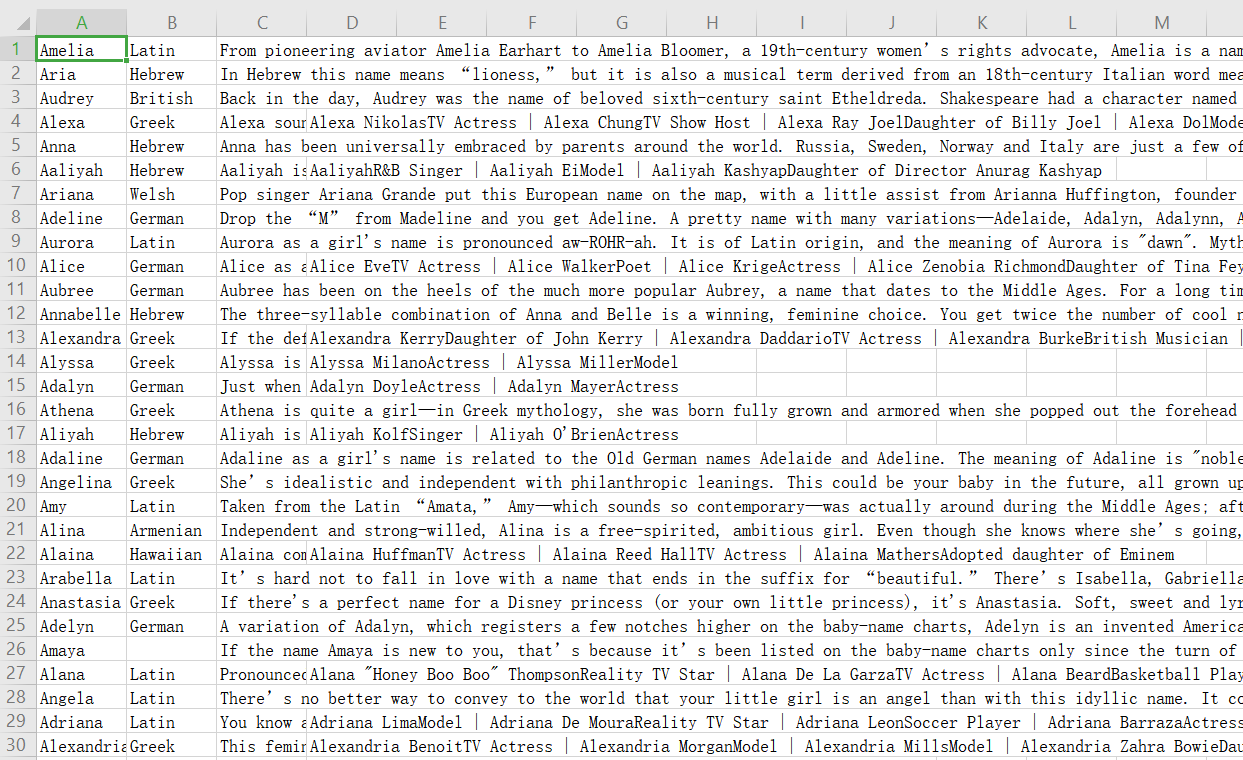
(2)爬取显示
爬取的内容会保存在csv文件当中,如图:
三 课程设计心得与体会
(1) 通过这次课程设计,使我更加扎实的掌握了有关Python方面的知识,在设计过程中,虽然遇到了一些问题,但经过一次又一次的思考,一遍又一遍的检查终于找出了原因所在,也暴露出了前期我在这方面的知识欠缺以及经验不足。实践出真知,通过亲自动手设计,使我们找你哥我的知识不再是纸上谈兵。
(2) 过而能改,善莫大焉。在课程设计过程中,我们不断发现错误,不断改正,不断领悟,不断获取。最终的检测调试环节,本身就是在实践“过而能改,善莫大焉”的知行观。这次的课程设计终于顺利完成了,在设计中遇到了很多问题,最后在同学们的帮助下迎刃而解,这也告诉我们,在今后的社会发展和学习实践过程中,一定要不懈努力,不能遇到问题就想到要退缩,一定要不厌其烦的发现问题所在,然后一一解决,只有这样才能成功的做成想做的事,才能在今后的道路上披荆斩棘,而不是知难而退,那样永远不可能收获成功,收获喜悦,也永远不可能得到社会及他人的认可。
(3) 课程设计诚然是一门专业课,给我很多专业知识以及专业技能上的提升,同时又是一门思辨课,给了我许多道,很多思。是我对抽象理论有了具体的认识。通过这次课程设计,我对正则表达式有了更深一步的理解运用,通过查询资料也了解了Python的爬虫原理。我认为,在这学期的实验中,不仅培养了独立思考、动手操作能力,在各种其他能力上也都有了提高。更重要的是,在课程设计学习中,我学会了很多学习方法,而这是日后最实用的,真的是受益匪浅。要面对社会的挑战,只有不断的学习、实践。在学习、在实践。这对于我们的将来也有很大的帮助。
正则表达式:
一:什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
二:爬虫的四个主要步骤
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (过滤和匹配我们需要的数据,去掉没用的数据)
- 处理数据(按照我们想要的方式存储和使用)
三:正则表达式匹配规则
| 元字符 | 说明 |
|---|---|
| . | 代表任意字符 |
| \ | |
| [ ] | 匹配内部的任一字符或子表达式 |
| [^] | 对字符集和取非 |
| - | 定义一个区间 |
| \ | 对下一字符取非(通常是普通变特殊,特殊变普通) |
| * | 匹配前面的字符或者子表达式0次或多次 |
| *? | 惰性匹配上一个 |
| + | 匹配前一个字符或子表达式一次或多次 |
| +? | 惰性匹配上一个 |
| ? | 匹配前一个字符或子表达式0次或1次重复 |
| {n} | 匹配前一个字符或子表达式 |
| {m,n} | 匹配前一个字符或子表达式至少m次至多n次 |
| {n,} | 匹配前一个字符或者子表达式至少n次 |
| {n,}? | 前一个的惰性匹配 |
| ^ | 匹配字符串的开头 |
| \A | 匹配字符串开头 |
| $ | 匹配字符串结束 |
| [\b] | 退格字符 |
| \c | 匹配一个控制字符 |
| \d | 匹配任意数字 |
| \D | 匹配数字以外的字符 |
| \t | 匹配制表符 |
| \w | 匹配任意数字字母下划线 |
| \W | 不匹配数字字母下划线 |
四.正则表达式例子
学习基础的例子,可以参见博客,个人觉得比较详细:https://blog.csdn.net/weixin_44258187/article/details/85307979
python爬虫—爬取英文名以及正则表达式的介绍的更多相关文章
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
随机推荐
- OPC 集成的五大要素,你都掌握了吗?
相信在处理工业项目集成问题的时候,自动化集成供应商真正需要的不是那些华丽的宣传语,而是提供真正的通信数据集成实力. 任何自动化集成的供应商都希望能够消除中间的层层障碍,从而实现真正的信息集成互通.那么 ...
- Android培训准备资料之五大布局简单介绍
本篇博客主要简单的给大家介绍一下Android五大布局 (1)LinearLayout(线性布局) (2)RelativeLayout(相对布局) (3)FrameLayout(帧布局) (4)Abs ...
- JavaScript中this究竟指向什么?
摘要: 神奇的this! 原文:JS 中 this 在各个场景下的指向 译者:前端小智 Fundebug经授权转载,版权归原作者所有. 1. this 的奥秘 很多时候, JS 中的 this 对于咱 ...
- TEE(Trusted Execution Environment)简介【转】
转自:https://blog.csdn.net/fengbingchun/article/details/78657188 TEE(Trusted Execution Environment),可信 ...
- 网络流之最大流EK --- poj 1459
题目链接 本篇博客延续上篇博客(最大流Dinic算法)的内容,此次使用EK算法解决最大流问题. EK算法思想:在图中搜索一条从源点到汇点的扩展路,需要记录这条路径,将这条路径的最大可行流量 liu 增 ...
- SHELL脚本和常用命令
什么是脚本? 脚本简单地说就是一条条的文字命令(一些指令的堆积),这些文字命令是可以看到的(如可以用记事本打开查看.编辑). 常见的脚本: JavaScript(JS,前端),VBScript, AS ...
- pycharm 有汉字的地方就有阴影
1.pycharm 有汉字的地方就有阴影 编码申明 阴影就会消失 # _*_ coding:UTF-8
- zzPony.ai 的基础架构挑战与实践
本次分享将从以下几个方面介绍: Pony.ai 基础架构做什么 车载系统 仿真平台 数据基础架构 其他基础架构 1. Pony.ai 基础架构 首先给大家介绍一下 Pony.ai 的基础架构团队做什么 ...
- 【java】isEmpty VS isBlank 的区别
- ASP.NET Core MVC 中的 Model 模型
ASP.NET Core MVC 中的 Model 我们希望最终从 Student 数据库表中查询特定的学生详细信息并显示在网页上,如下所示. MVC 中的模型包含一组表示数据的类和管理该数据的逻辑. ...