Python爬虫|爬取喜马拉雅音频
"GOOD
Python爬虫|爬取喜马拉雅音频
喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快、规模最大的在线移动音频分享平台。今晚分享突破障碍,探秘喜马拉雅的天籁之音,实现实时抓取,并保存到本地!
知识点:
开发环境:windows pycharm requests json
网络反爬技术
文件的操作
网络请求
数据的转换
数据类型的使用

1. 首先导入requests库
import requests

6. 将上面获得的json数据转换成字典格式(需要导入json模块)
import json

4. header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
这是应对反爬虫机制,伪装成合法浏览器而添加,本来复制过来的是User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36因python不识别User-Agent,所以将User-Agent用引号引起来,同时将冒号后面的内容也用引号引起来即可,这样就有了合法信息;该信息的位置:按F12->Network->headers->RequestHeaders->User-Agent: Mozilla/5.0...详见下图
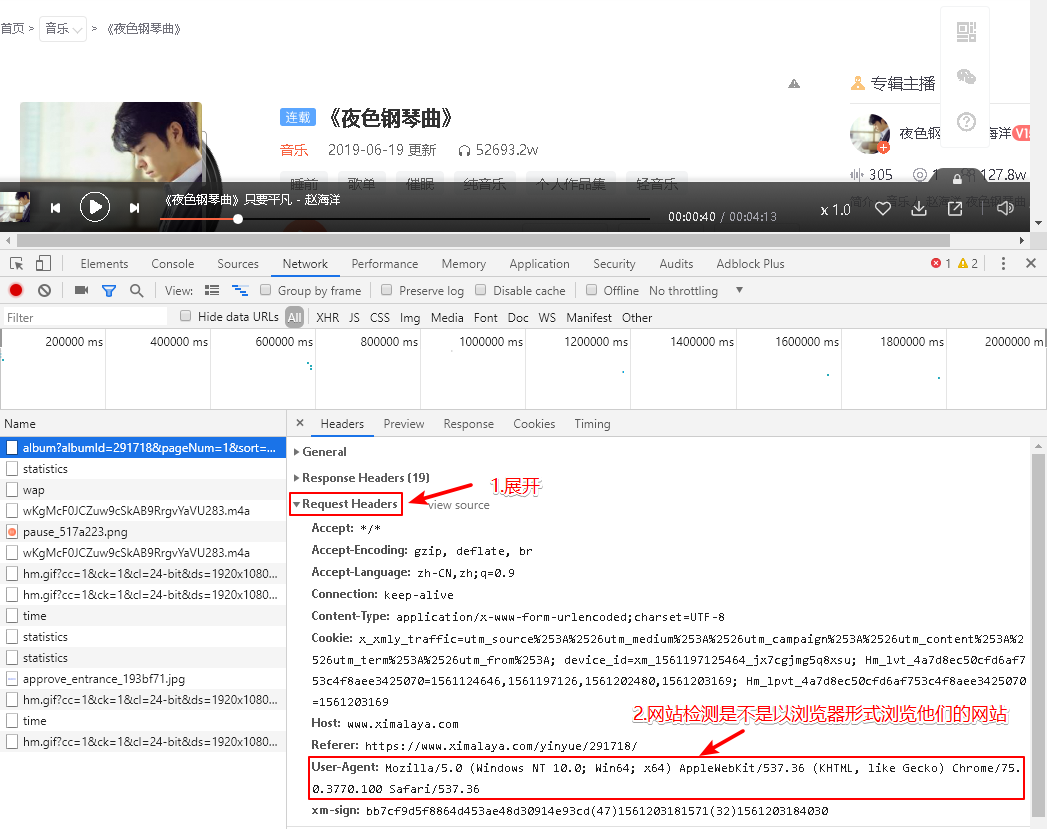
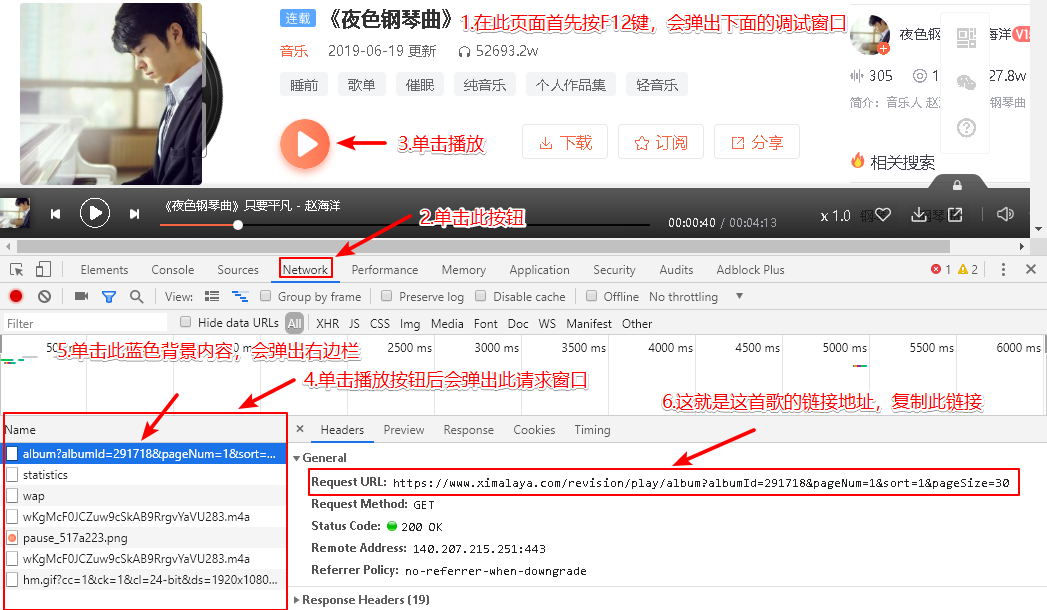
2. 设置url,链接的获取方式:
打开喜马拉雅官网->点击“轻音乐”->点击“夜色钢琴曲”->选择一首歌后会出现播放按钮(先不要点此按钮)->按F12->点击Network->点击播放按钮->此时调试窗口会弹出播放请求->点击name下的第一栏album?....->点击右边栏Headers->展开General->复制Request URL下的网址https://www.ximalaya.com/revision/play/album?albumId...即可
url = "https://www.ximalaya.com/revision/play/album?albumId=291718&pageNum=1&sort=1&pageSize=30"

3 将获取的数据赋值给response,打印response
response = requests.get(url).text
print(response)
结果未获取到数据,因为网站做了反爬虫机制,所以要在上面添加header伪装成合法身份
5. 因为上面添加了header变量,所以应该把第3步替换为:
response = requests.get(url,headers = header).text
print(response)

添加header后,重新运行获得了数据(JSON格式);复制下面的获取的数据,打开网址http://www.bejson.com/,在输入框中粘贴刚才的数据,点击“格式化校验”即可辨别是什么格式的文件;JSON类型为str,字典的类型为dict;它们的区别:d ={'name':'zs','gender':'man'} ===>是字典类型;而 s ='{'name':'zs','gender':'man'}' ===>是字符串类型,是JSON格式的字符串
7. 转换后赋值给audio_data(可在刚才判断类型的工具中查看一层一层的关系)
audio_data = json.loads(response)['data']['tracksAudioPlay']

8. 循环遍历链接及文件名
for audio_info in audio_data:
music_url = audio_info['src']
music_name = music_url.split('/')[-1]

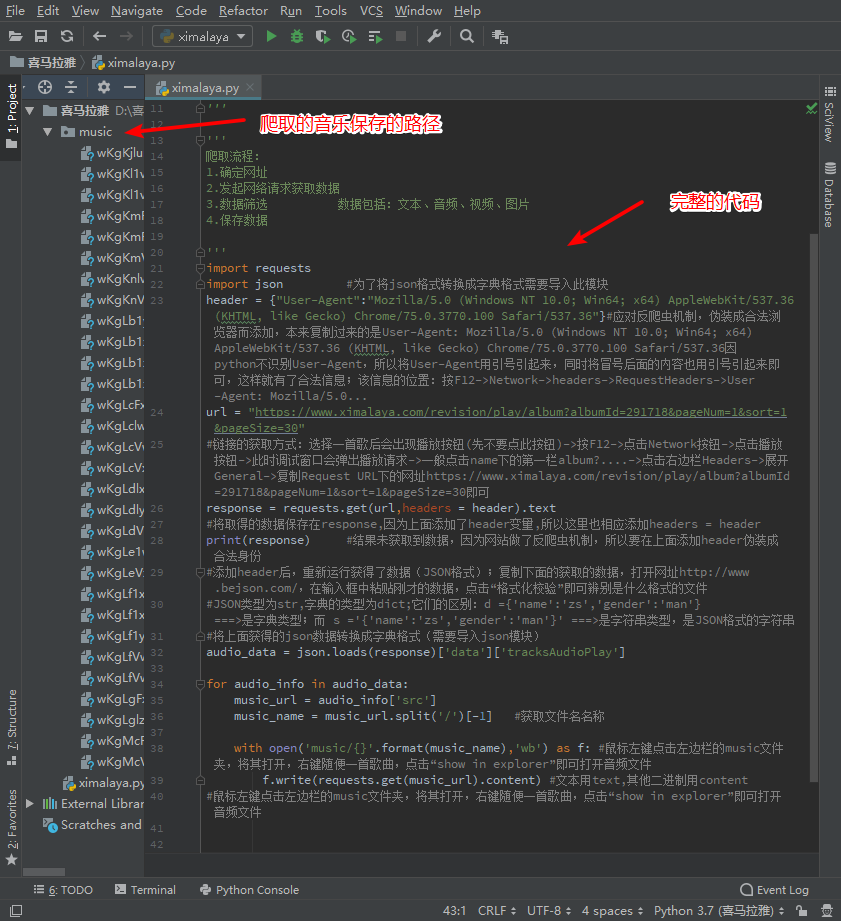
9. 将获得的数据保存在硬盘music中

鼠标左键点击左边栏的music文件夹,将其打开,右键随便一首歌曲,点击“show in explorer”即可打开音频文件。
注意事项
代码操作的顺序是1-9,完整顺序是1,6,4,2,3,5,7,8,9;
这是因为代码存在BUG 的时候要不断的添加删除项
学的到东西的事情是锻炼,学不到的是磨练,所以我一直走在练的路上。
 共享新方式
共享新方式
长按识别二维码,关注我们
Python爬虫|爬取喜马拉雅音频的更多相关文章
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- wepy开发
工欲善其事必先利其器 ide安装.配置] https://tencent.github.io/wepy/document.html VS Code 1. 在 Code 里先安装 Vue 的语法高亮 ...
- mybatis入门(五)
根据用户名称模糊查询用户信息 @Test public void findUserByNameTest() throws IOException { // 通过工厂得到SqlSession SqlSe ...
- Android笔记之强大的buildConfigField
在进行项目开发或维护时,经常会遇到调试和发布所用到的参数值不一致的情况 例如,服务器会分测试和正式,为了能方便地更改(自动更换)服务器地址,buildConfigField就派上用场了 以前都是手动更 ...
- Chain of Responsibility Pattern
1.Chain of Responsibility模式:将可能处理一个请求的对象链接成一个链,并将请求在这个链上传递,直到有对象处理该请求(可能需要提供一个默认处理所有请求的类,例如MFC中的Cwin ...
- 转载的C#学习笔记
转载地址:http://www.cnblogs.com/renyanlei/p/4075065.html 最近在一个培训机构里面教授Net知识.每天都会带领学生学习c#知识.我希望把每天学习的笔记记录 ...
- NYOJ-37 回文字符串 —— LCS变形
题目链接:http://acm.nyist.net/JudgeOnline/problem.php?pid=37 题解: 一开始想从两边向中间添加字符,发现这样不是最优的.因为加入字符之后,这些原本存 ...
- llala js弹出层 颜色渐变
网址:http://bbs.csdn.net/topics/370254842
- eslintrc.js
此插件主要就是规范前端程序员编写JS的规范,让代码看上去很优雅,也便于后期人员的重构和维护. 因为是用vue的cli搭建项目工程,使用了eslintrc.js ,但是在写JS时发现,首字母缩进一直报错 ...
- js的浅克隆和深克隆
谈一谈个人对js浅克隆和深克隆的区别. 之前也看到很多博客在写,当然也有写的非常好的,但是个人觉得既然要分享就不要写的太深奥,尽量以简单易懂为主. 浅克隆其实就是 对象A = 对象B:如果改变了对象B ...
- bzoj2730矿场搭建——点双连通分量
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2730 首先一遍tarjan找出割点,将图缩点,这些大点中如果有只包含一个割点的,那么如果这个 ...