[luogu P3384] 【模板】树链剖分 [树链剖分]
题目描述
如题,已知一棵包含N个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作:
操作1: 格式: 1 x y z 表示将树从x到y结点最短路径上所有节点的值都加上z
操作2: 格式: 2 x y 表示求树从x到y结点最短路径上所有节点的值之和
操作3: 格式: 3 x z 表示将以x为根节点的子树内所有节点值都加上z
操作4: 格式: 4 x 表示求以x为根节点的子树内所有节点值之和
输入输出格式
输入格式:
第一行包含4个正整数N、M、R、P,分别表示树的结点个数、操作个数、根节点序号和取模数(即所有的输出结果均对此取模)。
接下来一行包含N个非负整数,分别依次表示各个节点上初始的数值。
接下来N-1行每行包含两个整数x、y,表示点x和点y之间连有一条边(保证无环且连通)
接下来M行每行包含若干个正整数,每行表示一个操作,格式如下:
操作1: 1 x y z
操作2: 2 x y
操作3: 3 x z
操作4: 4 x
输出格式:
输出包含若干行,分别依次表示每个操作2或操作4所得的结果(对P取模)
输入输出样例
5 5 2 24
7 3 7 8 0
1 2
1 5
3 1
4 1
3 4 2
3 2 2
4 5
1 5 1 3
2 1 3
2
21
说明
时空限制:1s,128M
数据规模:
对于30%的数据:N<=10,M<=10
对于70%的数据:N<=1000,M<=1000
对于100%的数据:N<=100000,M<=100000
(其实,纯随机生成的树LCA+暴力是能过的,可是,你觉得可能是纯随机的么233)
样例说明:
树的结构如下:
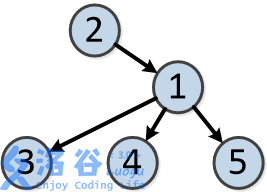
各个操作如下:
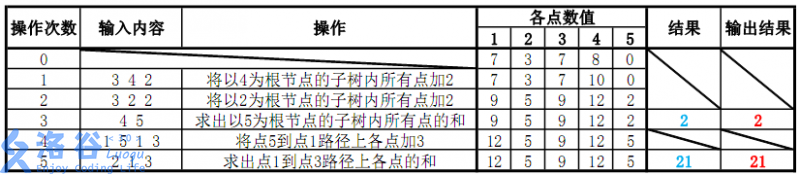
故输出应依次为2、21(重要的事情说三遍:记得取模)
My Solution
哪来的什么solution
因为这题快颓了week了
统计:2/29 AC!!!
为什么我之前要用树状数组嘞
向unsigned大佬低头 orz
#include<cstdio>
#include<iostream>
#include<cstring>
using namespace std; typedef long long ll; inline int read(){
char ch;
int re=;
bool flag=;
while((ch=getchar())!='-'&&(ch<''||ch>''));
ch=='-'?flag=:re=ch-'';
while((ch=getchar())>=''&&ch<='') re=re*+ch-'';
return flag?-re:re;
} inline ll rea(){
char ch;
ll re=;
bool flag=;
while((ch=getchar())!='-'&&(ch<''||ch>''));
ch=='-'?flag=:re=ch-'';
while((ch=getchar())>=''&&ch<='') re=re*+ch-'';
return flag?-re:re;
} struct edge{
int to,next;
edge(int to=,int next=):
to(to),next(next){}
}; struct Segment_Tree{
int l,r;
ll sum,tag;
}; const int maxn=; int cnt,n,m,root;
ll mod;
edge edges[maxn<<];
Segment_Tree tre[maxn<<];
int head[maxn],top[maxn],dep[maxn],fat[maxn],id[maxn],id_[maxn],son[maxn],siz[maxn];
int data[maxn]; inline void add_edge(int from,int to){
edges[++cnt]=edge(to,head[from]); head[from]=cnt;
edges[++cnt]=edge(from,head[to]); head[to]=cnt;
} void init(){
n=read(); m=read(); root=read(); mod=rea();
for(int i=;i<=n;i++)
data[i]=read();
int from,to;
cnt=;
for(int i=;i<n;i++){
from=read(); to=read();
add_edge(from,to);
}
} void dfs_1(int x,int fa){
fat[x]=fa;
siz[x]=;
dep[x]=dep[fa]+;
for(int ee=head[x];ee;ee=edges[ee].next)
if(edges[ee].to!=fa){
dfs_1(edges[ee].to,x);
siz[x]+=siz[edges[ee].to];
if(!son[x]||siz[edges[ee].to]>siz[son[x]])
son[x]=edges[ee].to;
}
} void dfs_2(int x,int fa){
if(!son[x]) return;
top[son[x]]=top[x];
id[son[x]]=++cnt;
id_[cnt]=son[x];
dfs_2(son[x],x);
for(int ee=head[x];ee;ee=edges[ee].next)
if(edges[ee].to!=fa&&edges[ee].to!=son[x]){
top[edges[ee].to]=edges[ee].to;
id[edges[ee].to]=++cnt;
id_[cnt]=edges[ee].to;
dfs_2(edges[ee].to,x);
}
} inline void push_up(int x){
tre[x].sum=tre[x<<].sum+tre[x<<|].sum;
} inline void push_down(int x){
tre[x<<].tag+=tre[x].tag;
tre[x<<].sum+=tre[x].tag*(tre[x<<].r-tre[x<<].l+);
tre[x<<|].tag+=tre[x].tag;
tre[x<<|].sum+=tre[x].tag*(tre[x<<|].r-tre[x<<|].l+);
tre[x].tag=;
return;
} void build(int x,int l,int r){
tre[x].l=l; tre[x].r=r;
if(l==r){
tre[x].sum=data[id_[l]];
return;
}
int mid=(l+r)>>;
build(x<<,l,mid);
build(x<<|,mid+,r);
push_up(x);
} void make(){
dfs_1(root,);
cnt=;
top[root]=root;
id[root]=cnt;
id_[cnt]=root;
dfs_2(root,);
build(,,n);
} void update(int x,int L,int R,ll c){
if(L<=tre[x].l&&tre[x].r<=R){
tre[x].tag+=c;
tre[x].sum+=c*(tre[x].r-tre[x].l+);
return;
}
push_down(x);
int mid=(tre[x].l+tre[x].r)>>;
if(R<=mid) update(x<<,L,R,c);
else if(L>mid) update(x<<|,L,R,c);
else{
update(x<<,L,mid,c);
update(x<<|,mid+,R,c);
}
push_up(x);
} ll query_sum(int x,int L,int R){
if(L<=tre[x].l&&tre[x].r<=R)
return tre[x].sum;
push_down(x);
int mid=(tre[x].l+tre[x].r)>>;
if(R<=mid) return query_sum(x<<,L,R);
else if(L>mid) return query_sum(x<<|,L,R);
else return query_sum(x<<,L,mid)+query_sum(x<<|,mid+,R);
} void change(int u,int v,ll c){
int f1=top[u];
int f2=top[v];
while(f1!=f2){
// this ensure u and v is not at the same heavy chain
if(dep[f1] < dep[f2]){
// ensure that heavy chain 1 is under heavy chain 2
swap(f1,f2);
swap(u,v);
}
update(,id[f1],id[u],c);
u=fat[f1];
f1=top[u];
}
if(dep[u]>dep[v]) swap(u, v);
update(,id[u],id[v],c);
} ll find_sum(int u, int v)
{
ll sum=;
int f1=top[u];
int f2=top[v];
while(f1!=f2)
{
if(dep[f1]<dep[f2])
{
swap(f1,f2);
swap(u,v);
}
sum+=query_sum(,id[f1],id[u]);
sum%=mod;
u=fat[f1];
f1=top[u];
}
if(dep[u]>dep[v]) swap(u, v);
sum+=query_sum(,id[u],id[v]);
return sum%mod;
} void solve(){
int opt,ss,tt;
ll c;
for(int i=;i<m;i++){
opt=read();
if(opt&){
//opt==3
if(opt&){
ss=read(); c=rea();
update(,id[ss],id[ss]+siz[ss]-,c);
}
//opt==1
else{
ss=read(); tt=read(); c=rea();
change(ss,tt,c);
}
}
else{
//opt==4
if(opt&){
ss=read();
printf("%lld\n",query_sum(,id[ss],id[ss]+siz[ss]-)%mod);
}
//opt==2
else{
ss=read(); tt=read();
printf("%lld\n",find_sum(ss,tt));
}
}
}
} int main(){
//freopen("data.in","r",stdin);
init();
make();
solve();
return ;
}
爱你锋利的伤痕 爱你成熟的天真
[luogu P3384] 【模板】树链剖分 [树链剖分]的更多相关文章
- [luogu P3384] [模板]树链剖分
[luogu P3384] [模板]树链剖分 题目描述 如题,已知一棵包含N个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作: 操作1: 格式: 1 x y z 表示将树从x到y结点 ...
- 【模板】树链剖分(Luogu P3384)
题目描述 众所周知 树链剖分是个好东西QWQ 也是一个代码量破百的算法 基本定义 树路径信息维护算法. 将一棵树划分成若干条链,用数据结构去维护每条链,复杂度为O(logN). 其实本质是一些数据结 ...
- 洛谷 P3384 【模板】树链剖分-树链剖分(点权)(路径节点更新、路径求和、子树节点更新、子树求和)模板-备注结合一下以前写的题目,懒得写很详细的注释
P3384 [模板]树链剖分 题目描述 如题,已知一棵包含N个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作: 操作1: 格式: 1 x y z 表示将树从x到y结点最短路径上所有节 ...
- 【Luogu】P3950部落冲突(树链剖分)
题目链接 状态奇差无比,sbt都能错一遍. 不动笔光想没有想到怎么做,画图之后发现一个很明显的性质…… 那就是两个开战的部落,其中一个是另一个的父亲. 所以在儿子那里加个权值.查询的时候树链剖分查询链 ...
- Aragorn's Story 树链剖分+线段树 && 树链剖分+树状数组
Aragorn's Story 来源:http://www.fjutacm.com/Problem.jsp?pid=2710来源:http://acm.hdu.edu.cn/showproblem.p ...
- hdu 3966 Aragorn's Story(树链剖分+树状数组/线段树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3966 题意: 给出一棵树,并给定各个点权的值,然后有3种操作: I C1 C2 K: 把C1与C2的路 ...
- BZOJ_3589_动态树_容斥原理+树链剖分
BZOJ_3589_动态树_容斥原理+树链剖分 题意: 维护一棵树,支持1.子树内点权加上一个数 2.给出k条链,求路径上的点权和(重复的计算一次) (k<=5) 分析: 可以用树剖+线段树解 ...
- dfs序+主席树 或者 树链剖分+主席树(没写) 或者 线段树套线段树 或者 线段树套splay 或者 线段树套树状数组 bzoj 4448
4448: [Scoi2015]情报传递 Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 588 Solved: 308[Submit][Status ...
- dsu+树链剖分+树分治
dsu,对于无修改子树信息查询,并且操作支持undo的问题 暴力dfs,对于每个节点,对所有轻儿子dfs下去,然后再消除轻儿子的影响 dfs重儿子,然后dfs暴力恢复轻儿子们的影响,再把当前节点影响算 ...
- 2016湖南省赛 I Tree Intersection(线段树合并,树链剖分)
2016湖南省赛 I Tree Intersection(线段树合并,树链剖分) 传送门:https://ac.nowcoder.com/acm/contest/1112/I 题意: 给你一个n个结点 ...
随机推荐
- Java 9 揭秘(4. 模块依赖)
文 by / 林本托 Tips 做一个终身学习的人. 在此章节中,主要学习以下内容: 如何声明模块依赖 模块的隐式可读性意味着什么以及如何声明它 限定导出(exports)与非限定导出之间的差异 声明 ...
- 静态代码块详解(原出处:http://versioneye.iteye.com/blog/1129579)
一 般情况下,如果有些代码必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的;需要在项目启动的时候就初始化,在不创建对象的情 况下,其他程序来调用的时候,需要使用静态方法,这种 ...
- 非滤波单目视觉slam笔记1
非滤波单目视觉slam 主要分为以下8部分 数据类型 数据关联 初始化 位姿估计 地图维护 地图生成 失效恢复 回环检测 数据类型 直接法(稠密,半稠密) 基本原理是亮度一致性约束,\(J(x,y) ...
- 原生JS+Canvas实现五子棋游戏
一.功能模块 先看下现在做完的效果: 线上体验:https://wj704.github.io/five_game.html 主要功能模块为: 1.人机对战功能 2.悔棋功能 3.撤销悔棋功能 二.代 ...
- Mybatis中javaType和jdbcType对应和CRUD例子
JDBC Type Java Type CHAR String VARCHAR String LONGVARCHAR String NUMERIC java.math.BigDecimal DECIM ...
- 如何用phpcms将静态网页生成动态网页?
在前两篇随笔中已经简单介绍了phpcms,那么现在让我们来看一下如何用phpcms将静态网页生成动态网页? 1.在templates文件夹下新建模板文件夹ceshi(名字可以自己随笔起) 2.在ces ...
- Java NIO学习笔记 NIO选择器
Java NIO选择器 A Selector是一个Java NIO组件,可以检查一个或多个NIO通道,并确定哪些通道已准备就绪,例如读取或写入.这样一个线程可以管理多个通道,从而管理多个网络连接. 为 ...
- vue组件(Vue+webpack项目实战系列之三)
组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码.特别对于大型应用开发来说,尽量组件化,并且先造好轮子库,不要重复去写组件,这会显著提升项目 ...
- PHPCMS V9 为今天或几天前文章加new
今天内发布: {pc:content action="lists" catid="13" order="listorder DESC" nu ...
- 超链接访问过后hover样式就不出现的问题是什么?如何解决?
被点击访问过的超链接样式不在具有hover和active了,解决方法是改变CSS属性的排列顺序: L-V-H-A(link,visited,hover,active)