sklearn交叉验证2-【老鱼学sklearn】
过拟合
过拟合相当于一个人只会读书,却不知如何利用知识进行变通。
相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨。
从图形上看,类似下图的最右图:
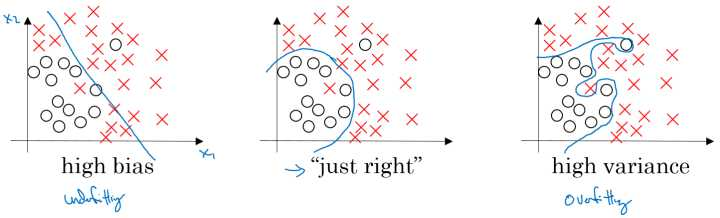
从数学公式上来看,这个曲线应该是阶数太高的函数,因为一般任意的曲线都能由高阶函数来拟合,它拟合得太好了,因此丧失了泛化的能力。
用Learning curve 检视过拟合
首先加载digits数据集,其包含的是手写体的数字,从0到9:
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
然后用SVC(支持向量机)对手写体数字进行分类,当然,这里要介绍的核心函数是learning_curve,先上代码看看:
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
在learning_curve中设置了十一法的数据,同时在打分时使用了neg_mean_squared_error方式,也就是方差值,因此这个最后的得分值是负数;train_sizes指定了5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
最后,我们把根据每轮的训练集大小对于最终得分的影响程度画个图,相当于做题数量的多少跟最终考试成绩的关系图:
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
显示图形为:
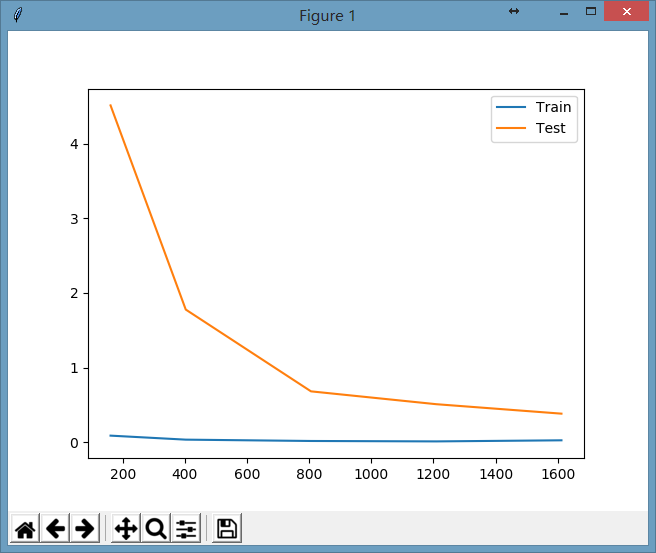
看起来随着做题数量的增加,考试成绩越来越好了(损失函数的值越来越小了),并且考试成绩在慢慢逼近平常的训练成绩。
完整的代码如下:
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
# 加载学习曲线模块
from sklearn.model_selection import learning_curve
import numpy as np
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
如果我们把上面代码中SVC参数的gamma值设置为0.1,显示出的图形为:
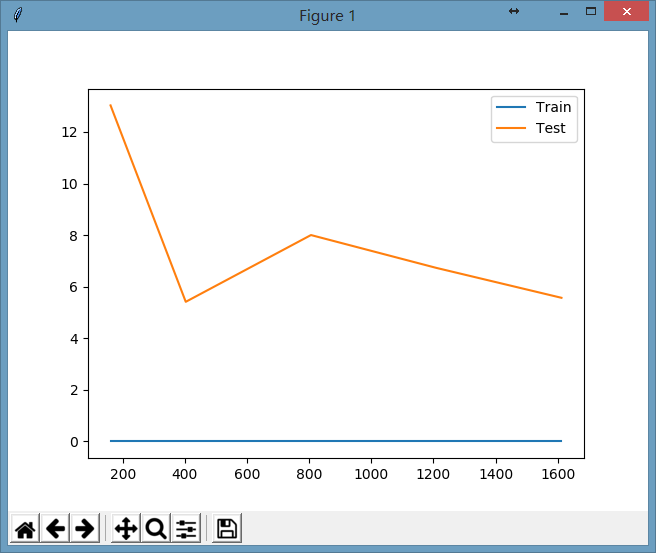
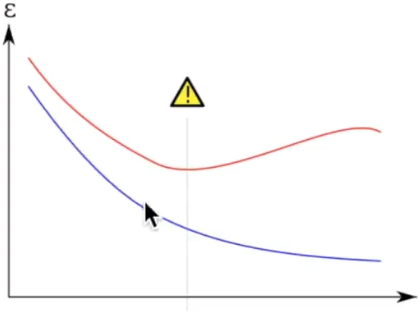
在上面的图形中,我们会发现再增加训练集的数据并没有使测试集的损失值下降,相当于一个人按照他的学习方式做训练题已经够多了,你做更多的训练题都无法提高你的考试成绩了,这时可能需要考虑的是稍微改变一下你的学习方法说不定就能提高考试成绩呢。
这也说明了,在某些情况下题海战术不一定奏效了。
在机器学习中表示为所学到的模型可能太复杂了,产生了过拟合(过拟合表现为训练集的损失函数在下降,但测试集的损失函数不降反升),不具备泛化能力,例如下图中绿色曲线就是一个过拟合的表现:
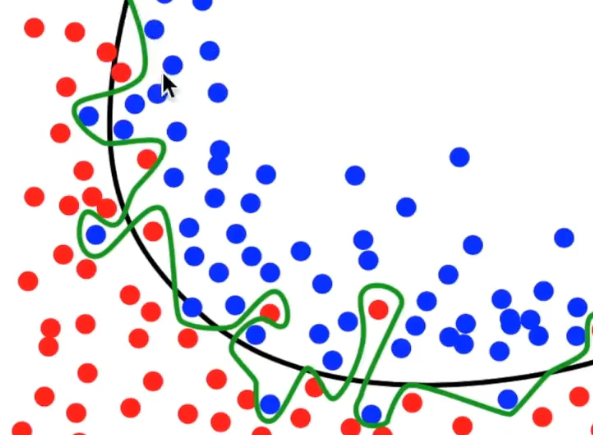
相应的损失函数曲线显示如下所示:
因此如果我们想要查看是否有过拟合,可以通过learning_curve函数来进行并以可视化的方式来查看结果。
sklearn交叉验证2-【老鱼学sklearn】的更多相关文章
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
随机推荐
- vue 拖拽移动(类似于iPhone虚拟home )
vue 移动端 PC 兼容 元素 拖拽移动 效果演示 事件知识点 移动端 PC端 注释 touchstart mousedown 鼠标/手指按下事件 touchmove mousemove 鼠标/手 ...
- Linux下C语言生成可执行文件的过程
在当前目录下创建一个C源文件并打开: touch test.c gedit test.c直接编译: gcc test.c -o test 分步骤编译: 1) 预处理 gcc -E test.c ...
- C++ Under the Hood
The original article is taken from http://msdn.microsoft.com/archive/en-us/dnarvc/html/jangrayhood.a ...
- Mock8 moco框架如何返回一个cookie信息
还是用之前的startupWithCookies.json这个文件,直接往里面添加上面的一个代码: [ { "description":"这是一个会返回cookies信息 ...
- centos7启动网卡报错(Failed to start LSB: Bring up/down networking )
systemctl status network.service systemctl stop NetworkManager systemctl disable NetworkManager syst ...
- saltstack主机管理项目:编写插件基类-获取主机列表-提取yaml配置文件(四)
一.编写插件基类 1.目录结构 1.我是如何获知我有多少种系统? 当客户端第一连接过来的时候,我就已经把这些文件存下来了 ,存在到哪里了?存到数据库了 每次对主机发送命令的动作时,我从库里把数据取出来 ...
- Git Gerrit使用
Git Gerrit 操作都用 git bash操作: 如果想用 cmd 或者 PowerShell,系统环境变量 Path 添加 Git 安装路径,如: C:\Program Files (x86) ...
- 第五节: Quartz.Net五大构件之Trigger的四大触发类
一. WithSimpleSchedule(ISimpleTrigger) 1. 用途:时.分.秒上的轮询(和timer类似),实际开发中,该场景占绝大多数. 2. 轮询的种类:永远轮询和限定次数轮询 ...
- 点评cat系列-服务器开发环境部署
我们有三种部署方式:1. docker 部署2. 采用官方的 war 包部署. 3. 源码部署 很显然 docker 部署是最简单的, 我尝试了多次, 都在 cat docker 容器镜像的编译过程失 ...
- [物理学与PDEs]第1章习题3 常场强下电势的定解问题
在一场强为 ${\bf E}_0$ (${\bf E}_0$ 为常向量) 的电场中, 置入一个半径为 $R$ 的导电球体, 试导出球外电势所满足的方程及相应的定解条件. 解答: 设导电球体为 $B_R ...