Python——LOL官方商城皮肤信息爬取(一次练手)
# -*- coding utf-8 -*-
import urllib
import urllib.request
import json
import time
import xlsxwriter
from asyncio.tasks import sleep
import re # 根据第一页数据创建信息表头
header = []
url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=1&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol"
data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n",""))
goods_info = data["data"]["goods"][0]["valiDate"][0]
for i in range(len(goods_info)):
header.append(''.join((re.findall("\w",str(str(goods_info).split(",")[i]).split(":")[0]))).strip()) # 创建工作簿,写表头
workbook = xlsxwriter.Workbook("E:/lol_sales.xlsx")
sheet = workbook.add_worksheet("result")
for i in range(len(header)):
sheet.write(0,i,header[i]) # 获取数据
row_index = 1
for page_index in range(1,61):
url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=" + str(page_index) + "&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol"
data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n",""))
for goods_index in range(6):
try:
for col_index in range(len(header)):
if header[col_index] == "award":
pass
else:
sheet.write(row_index,col_index,data["data"]["goods"][goods_index]["valiDate"][0][header[col_index]])
row_index += 1
except:
pass
print("page" + str(page_index))
workbook.close()
print("finish")
获取的数据内容如下:
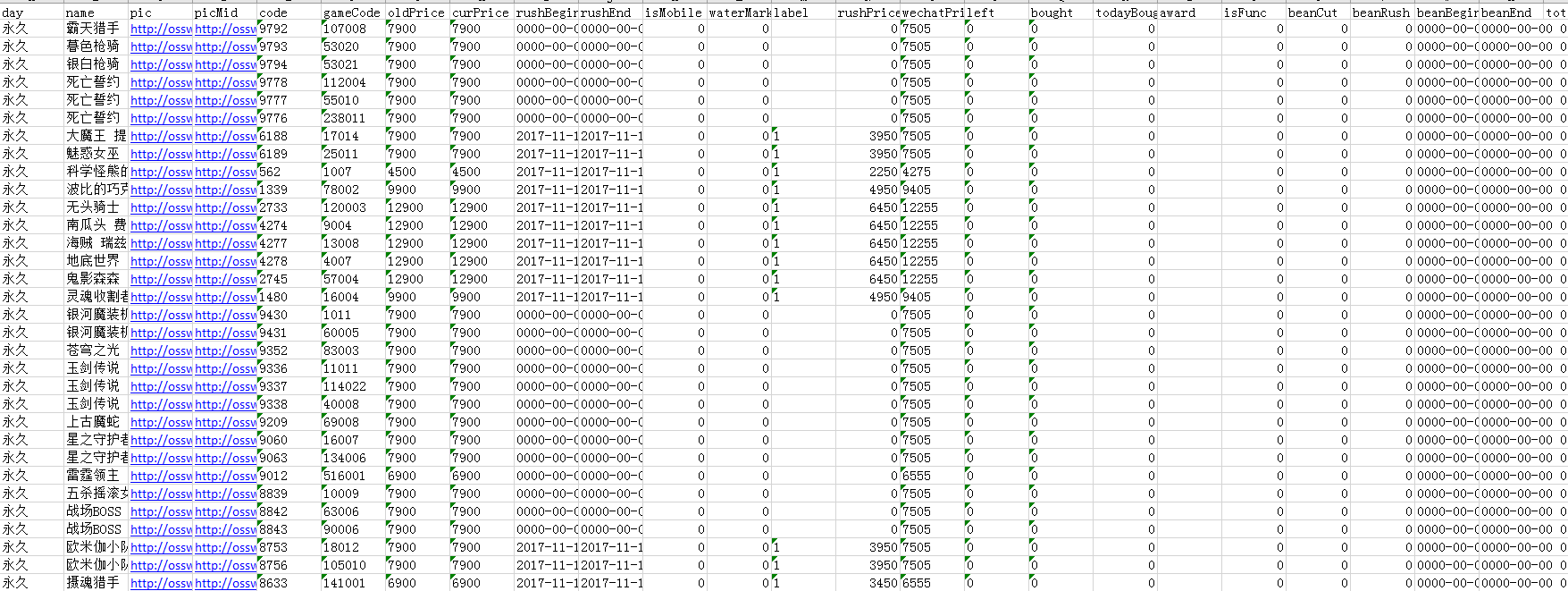
总结:
1.表头的获取方式。
不要再自己编写表头啦,一是太费事,二是不灵活。
通过创建空的列表,读取示范页面(如第一页)的信息表头,使用.append即可创建所需表头。
2.多数网站的数据格式都是json,但是其返回的还附带了json数据的表头,注意删除掉。
如.replace("var ogoods_list_api = ","").replace("\n","")。这样才是符合格式要求的json(可以用这个网站测试json格式是否标准:Be JSON),否则无法用json.loads()读取,因为会被识别成字符串。
3.json.loads(s),中读取的是字符串数据。
4.即使读取出来的数据编码是unicode,但是写入excel的时候就被解码了。(使用了多种方式仍无法对数据解码,故打算提取后单独解码,后发现写入excel的是解码后的数据。意外发现。)
5.关于表头的提取:
- 首先使用两次split,分别是“,”和“:”将json的key提取出来。
- 接下来使用正则表达式提取{'ret'中的ret。在这里使用了这样的方法:用\w提取英文字符,再用''.join()合并起来
Python——LOL官方商城皮肤信息爬取(一次练手)的更多相关文章
- 关于python的中国历年城市天气信息爬取
一.主题式网络爬虫设计方案(15分)1.主题式网络爬虫名称 关于python的中国城市天气网爬取 2.主题式网络爬虫爬取的内容与数据特征分析 爬取中国天气网各个城市每年各个月份的天气数据, 包括最高城 ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- 【Python】博客信息爬取-微信消息自动发送
1.环境安装 python -m pip install --upgrade pip pip install bs4 pip install wxpy pip install lxml 2.博客爬取及 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
随机推荐
- Docker-Docker-compose应用
Docker-compose是用来定义和运行多容器应用的工具,它是独立于docker存在的,需要单独安装.实际应用场景中,我们的应用可能被打包运行在不同的容器里面,例如一个常规的web应用可能会涉及到 ...
- .net问号的作用
??运算符(C# 参考)http://msdn.microsoft.com/zh-cn/library/ms173224.aspx 可以为 null 的类型(C# 编程指南)http://msdn.m ...
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- asyncio 基础用法
asyncio 基础用法 python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? asyncio是Python 3.4版本引入 ...
- 练习 python之数据库增删改查
# 文件存储时可以这样表示 ## id,name,age,phone,dept,enroll_date# 1,Alex Li,22,13651054608,IT,2013-04-01# 2,Jack ...
- 【题解】UVA11362 Phone List
Tags : 排序,字典树 从短到长排序,逐个插入字典树.若与已有的重复,返回错误信息. #include <iostream> #include <stdio.h> ...
- openstack第五章:cinder
第五篇cinder— 存储服务 一.cinder 介绍: 理解 Block Storage 操作系统获得存储空间的方式一般有两种: 通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接 ...
- App Inventor2项目部署到本地
介绍App Inventor App Inventor 原是Google实验室(Google Lab)的一个子计划,该项目是一个完全在线开发的Android编程环境,抛弃复杂的程式代码而使用积木式的堆 ...
- Docker 案例: 在容器中部署静态网站
----------------知识点------------ 容器的端口映射: docker run [-P] [-p] -P,–publish-all=true | false,大写的P表示为 ...
- dict、defaultdict 和 OrderedDict 比较
一.dict.defaultdict 和 OrderedDict 常见的方法比较 dict.defaultdict 和 OrderedDict 常见的方法比较 dict defaultdict O ...