Kafka(一)简介
1、Kafka简介
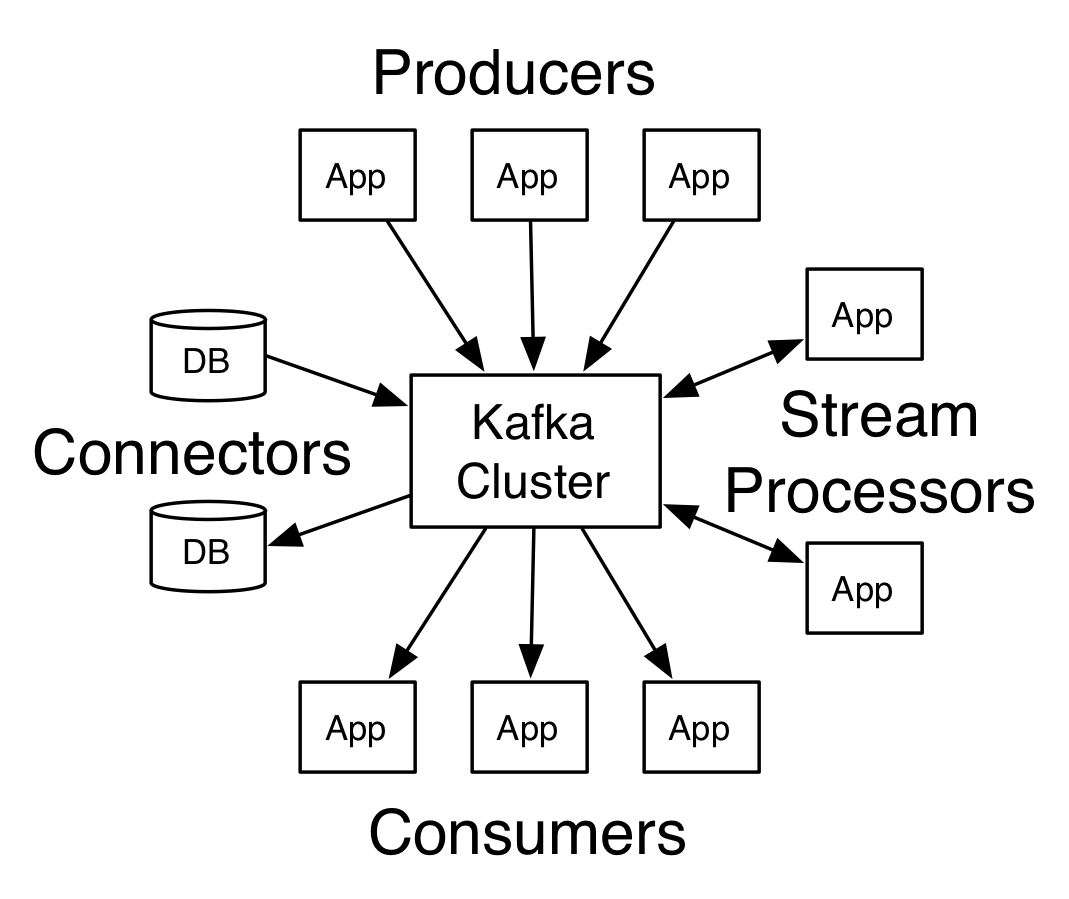
Kafka已经被很多公司广泛应用,一款实时流式消息组件。发送消息端称为Producer,接收端称为Consumer,Kafka集群有多个kafka实例组成,每个实例称为broker。无论是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
2、Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
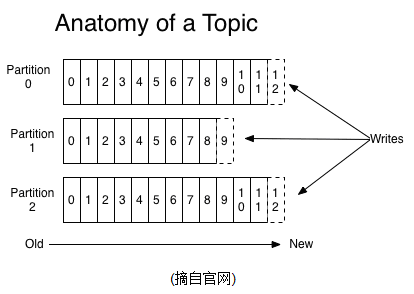
即时消息被消费,消息仍然不会被立即删除。日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留两天,那么两天后,文件会被清除,无论其中的消息是否被消费。
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制,当consumer正常消费消息时,offset将会“线性”的向前驱动,即消息将依次顺序被消费。事实上,consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值。
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端非常轻量级。它们可以随意离开,而不会对集群造成额外的影响。
partitions的设计目的有多个,最根本的原因是kafka基于文件存储。通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限。每个partition都会被当前server(kafka实例)保存;可以将一个topic切分任意多个partitions,来消息保存/消费的效率。此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
3、Distribution
一个Topic的多个partitions,被分布在kafka集群中的多个server上,每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性
基于replicated方案,那么就意味着有多少个“leader”,kafka会将“leader”均衡的分散在每个实例上,来确保整体的性能稳定。
4、Producers
Producers将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition,比如基于“round-robin”方式或者通过其他的一些算法等。
5、Consumers
本质上kafka只支持Topic。每个consumer属于一个consumer group,反过来说,每个group中可以有多个consumer。发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
如果所有的consumer都具有相同的group,这种情况和queue模式很像,消息将会在consumers之间负载均衡。如果所有的consumer都具有不同的group,那这就是“发布-订阅”;消息将会广播所有的消费者
在kafka中,一个partiton中的消息只会被group中的一个consumer消费,每个group中consumer消息消费相互独立;我们可以认为一个group是一个“订阅”者,一个Topic中的每个partitions,只会被一个“订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息,kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的。实时上,从Topic角度来说,消息仍不是有序的。
Kafka的设计原理,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着默写consumer将无法得到消息。
6、Guarantees
- 发送到partitions中的消息将会按照它接受的顺序追加到日志中
- 对于消费者而言,它们消费消息的顺序和日志消息顺序一致
- 如果Topic的"replicationfactor"为N,那么允许N-1个kafka实例失效。
Kafka(一)简介的更多相关文章
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- 替代Flume——Kafka Connect简介
我们知道过去对于Kafka的定义是分布式,分区化的,带备份机制的日志提交服务.也就是一个分布式的消息队列,这也是他最常见的用法.但是Kafka不止于此,打开最新的官网. 我们看到Kafka最新的定义是 ...
- 最简单流处理引擎——Kafka Streaming简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务.而kafka在这之前也没有提供数据处理的顾服务.大家的流处理计算主要是还是依赖于Storm,Spark Stre ...
- Kafka Connect简介
Kafka Connect简介 http://colobu.com/2016/02/24/kafka-connect/#more Kafka 0.9+增加了一个新的特性Kafka Connect,可以 ...
- Kafka学习之路 (一)Kafka的简介
一.简介 1.1 概述 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ng ...
- Kafka(一)Kafka的简介与架构
一.简介 1.1 概述 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ng ...
- Kafka学习笔记(1)----Kafka的简介和Linux下单机安装
1. Kafka简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka学习-简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.S ...
- Kafka基础简介
kafka是一个分布式的,可分区的,可备份的日志提交服务,它使用独特的设计实现了一个消息系统的功能. 由于最近项目升级,需要将spring的事件机制转变为消息机制,针对后期考虑,选择了kafka作为消 ...
随机推荐
- js获取数组中最大值,最小值
遍历方法 var arr =[12,14,34,566,34,98,77] var max = arr[0]; for(var i=0;i<arr.length;i++){ if(max< ...
- robotframework上的字体放大和缩小是ctr++和ctl--
- bzoj2006 [NOI2010]超级钢琴 (及其拓展)
bzoj2006 [NOI2010]超级钢琴 给定一个序列,求长度在 \([L,\ R]\) 之间的区间和的前 \(k\) 大之和 \(n\leq5\times10^5,\ k\leq2\times1 ...
- Reason的介绍和搭建Reason开发环境
Reason介绍 Reason是在Ocaml语言的基础上修改而来,专门提供给前端开发者使用. Reason是函数式编程语言,使用Bucklescript编译器编译成javascript语言. 在我看来 ...
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 11 Django REST Framework 针对基于类的视图添加 @csrf_exempt
01-在类的 dispatch 方法上使用 @csrf_exempt from django.views.decorators.csrf import csrf_exempt class MyView ...
- 我的Qt历程1:第一个Qt程序
1.启动Qt,按照红圈内所标注顺序执行操作. 2.按下Choose键后,在“名称”栏目里给程序起名字(不要是汉字名字). 3.在“创建路径”栏目里指定程序将要使用的路径(不能用汉字路径). 4.在“类 ...
- Spring缓存注解@Cacheable、@CacheEvict、@CachePut使用(转)
原文地址:https://www.cnblogs.com/fashflying/p/6908028.html 从3.1开始,Spring引入了对Cache的支持.其使用方法和原理都类似于Spring对 ...
- selenium webdriver 如何实现将浏览器滚动条移动到某个位置
说明: 在做selenium webdriver 在做UI 自动化时,有些页面时使用懒加载的形式显示页面图片,如果在不向下移动滚动条时,获取到的图片会是网站的默认图片和真实的图片不相符. 所以研究了 ...
- Django Models 查询操作
1.准备数据表: from django.db import models class City(models.Model): name=models.CharField(max_length=32) ...