第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware随机更换user-agent浏览器用户代理
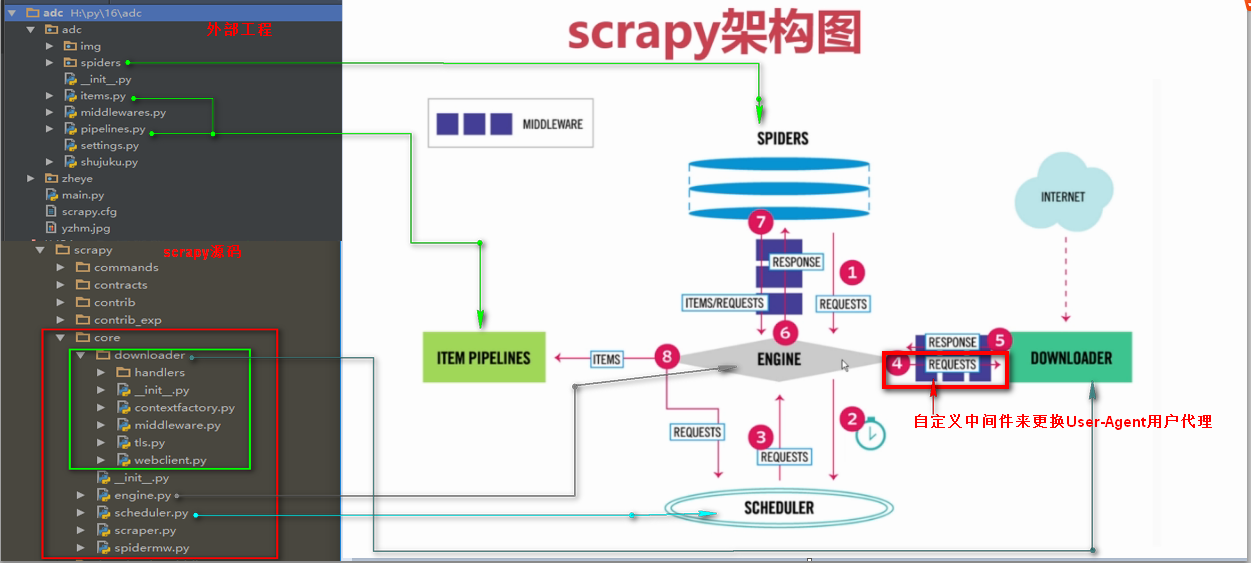
downloadmiddleware介绍
中间件是一个框架,可以连接到请求/响应处理中。这是一种很轻的、低层次的系统,可以改变Scrapy的请求和回应。也就是在Requests请求和Response响应之间的中间件,可以全局的修改Requests请求和Response响应
UserAgentMiddleware()方法,默认中间件
源码里downloadmiddleware里的useragent.py下的UserAgentMiddleware()方法,默认中间件
我们可以从源码看到当Requests请求时默认的User-Agent是Scrapy,这个很容易被网站识别而拦截爬虫

我们可以修改默认中间件UserAgentMiddleware()来随机更换Requests请求头信息的User-Agent浏览器用户代理
第一步、在settings.py配置文件,开启中间件注册DOWNLOADER_MIDDLEWARES={ }
将默认的将默认的UserAgentMiddleware设置为None,或者设置成最大就最后执行,这样我们自定义的中间件修改默认的user_agent就会先执行
settings.py配置文件
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
第二步、安装浏览器用户代理模块fake-useragent 0.1.7
fake-useragent 是一个专门用于爬虫伪装浏览器User-Agent请求头的模块。此模块在线维护了各个浏览器的各种版本库,提供我们使用
在线各种浏览器信息:http://fake-useragent.herokuapp.com/browsers/0.1.7 0.1.7版本,fake-useragent会随机到这里调用浏览器代理
首先安装这个模块
pip install fake-useragent
使用说明:
#!/usr/bin/env python
# -*- coding:utf8 -*- from fake_useragent import UserAgent #导入浏览器代理模块
ua = UserAgent() #实例化浏览器代理类 ua.ie #随机获取IE类型的代理
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie #随机获取msie类型的代理,下面的相同
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua['Internet Explorer']
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua.opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua.chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25 # and the best one, random via real world browser usage statistic
ua.random #随机获取各种浏览器类型的代理,
更多使用 https://pypi.python.org/pypi/fake-useragent/0.1.7
第三步、自定义中间件来全局随机更换Requests请求头信息的User-Agent浏览器用户代理
在middlewares.py文件里,自定义中间件
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from fake_useragent import UserAgent #导入浏览器用户代理模块 class RequestsUserAgentmiddware(object): #自定义浏览器代理中间件
#随机更换Requests请求头信息的User-Agent浏览器用户代理
def __init__(self,crawler):
super(RequestsUserAgentmiddware, self).__init__() #获取上一级父类基类的,__init__方法里的对象封装值
self.ua = UserAgent() #实例化浏览器用户代理模块类
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') #获取settings.py配置文件里的RANDOM_UA_TYPE配置的浏览器类型,如果没有,默认random,随机获取各种浏览器类型 @classmethod #函数上面用上装饰符@classmethod,函数里有一个必写形式参数cls用来接收当前类名称
def from_crawler(cls, crawler): #重载from_crawler方法
return cls(crawler) #将crawler爬虫返回给类 def process_request(self, request, spider): #重载process_request方法
def get_ua(): #自定义函数,返回浏览器代理对象里指定类型的浏览器信息
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua()) #将浏览器代理信息添加到Requests请求
第四步、将我们自定义的中间件注册到settings.py配置文件,的DOWNLOADER_MIDDLEWARES里
注意一点要把默认的UserAgentMiddleware中间件设置为None,使其我们自定义的中间件生效
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'adc.middlewares.RequestsUserAgentmiddware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
我们可以打断点调试一下,看看是否生效
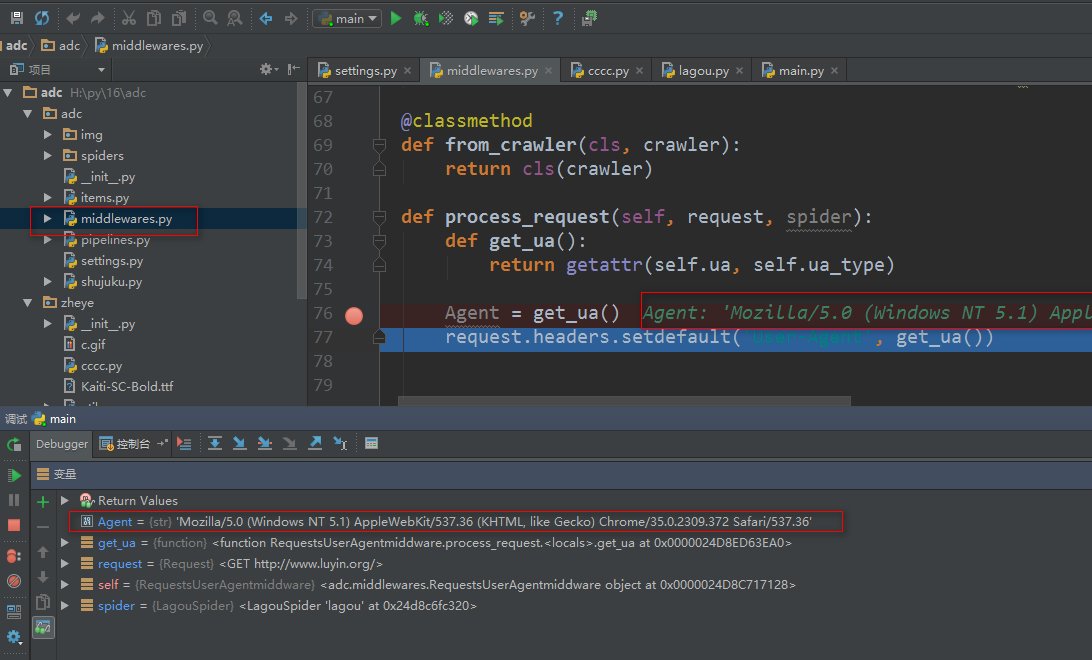
原理说明图
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理的更多相关文章
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 二十七 Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
设置代理ip只需要,自定义一个中间件,重写process_request方法, request.meta['proxy'] = "http://185.82.203.146:1080&quo ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
随机推荐
- 关于在node项目使用ioredis遇到的几个坑
1,在ioredis中使用redis命令的方法的时候,如果有2个以上的参数,必须使用then方法来接收返回的结果,比如: redis.hget('key','field').then(function ...
- (原创)用c++11实现简洁的ScopeGuard
ScopeGuard的作用是确保资源面对异常时总能被成功释放,就算没有正常返回.惯用法让我们在构造函数里获取资源,当因为异常或者正常作用域结束,那么在析构函数里释放资源.总是能释放资源.如果没有异常抛 ...
- mysql++ Query
mysqlpp:: Query类存储了Connection的指针,可以用它进行SQL语句的增删改查. 连上数据库后,使用mysqlpp::Connection::query()获取Query对象 Qu ...
- javascript基础拾遗(二)
1.对象定义 定义属性 var language = { name:'javascript', score:9.0 }; console.log(language.name) console.log( ...
- 使用终端执行.app程序 for mac
背景:打开Eclipse闪退,需要查看错误日志 问题:使用Terminal执行 ./Eclipse.app时,提示“no such file or directory” 解决方案:执行./Applic ...
- 【Delphi】@,^,#,$特殊符号意义
概述 ^: 指针 @: 取址 #: 十进制符 $: 十六进制符 @ :取址运算符 var int :integer; p :^integer; begin new(P); int :=; p := ...
- Win7中的路由转发配置实验
目的 Win7 两张网卡,两个网段的pc互通. 环境搭建 PC1通过交叉网线连接(如果是08年后的电脑,直通线交叉线都可以). PC2为笔记本电脑,一端用网口与pc连接,一端通过wifi与路由连接. ...
- jetty el表达式不支持三元运算
在jetty跑web程序中不支持三元运算 要换一种格式写 这种代码在jsp页面用jetty跑起来是会报错的,然后调换一下顺序就可以了 或者在后面那个加个括号也可以
- Python中斐波那契数列的四种写法
在这些时候,我可以附和着笑,项目经理是决不责备的.而且项目经理见了孔乙己,也每每这样问他,引人发笑.孔乙己自己知道不能和他们谈天,便只好向新人说话.有一回对我说道,“你学过数据结构吗?”我略略点一点头 ...
- mac电脑的系统偏好设置的安全与隐私的任何来源没有了
打开电脑搜索 输入终端 打开终端输入 sudo spctl --master-disable