Spark分布式集群的搭建和运行
集群共三台CentOS虚拟机,一个Matser,主机名为master;三个Worker,主机名分别为master、slave03、slave04。前提是Hadoop和Zookeeper已经安装并且开始运行。
1. 在master上下载Scala-2.11.0.tgz,复制到/opt/下面,解压,在/etc/profile加上语句:
export SCALA_HOME=/opt/scala-2.11.0
export PATH=$PATH:$SCALA_HOME/bin
然后运行命令:
source /etc/profile
在slave03、slave04上也执行相同的操作。
2. 在master上下载spark-2.1.0-bin-hadoop2.6,复制到/opt/下面。解压,在/etc/profile加上语句:
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
然后运行命令:
source /etc/profile
3. 编辑${SPARK_HOME}/conf/spark-env.sh文件,增加下面的语句:
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_121
# SCALA_HOME
export SCALA_HOME=/opt/scala-2.11.0
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
# Master主机名
export SPARK_MASTER_HOST=master
# Worker的内存大小
export SPARK_WORKER_MEMORY=1g
# Worker的Cores数量
export SPARK_WORKER_CORES=1
# SPARK_PID路径
export SPARK_PID_DIR=$SPARK_HOME/tmp
# Hadoop配置文件路径
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0-cdh5.9.0/etc/hadoop
# Spark的Recovery Mode、Zookeeper URL和路径
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:12181,slave03:12181,slave04:12181 -Dspark.deploy.zookeeper.dir=/spark"
在${SPARK_HOME}/conf/slaves中增加:
matser
slave03
slave04
这样就设置了三个Worker。
修改文件结束以后,将${SPARK_HOME}用scp复制到slave03和slave04。
4. 在master上进入${SPARK_HOME}/sbin路径,运行:
./start-master.sh
这是启动Master。
再运行:
./start-slaves.sh
这是启动Worker。
5. 在master上运行jps,如果有Master和Worker表明启动成功:
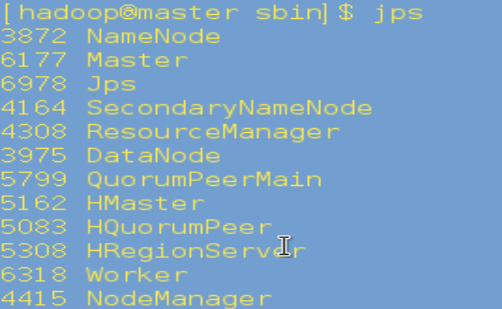
在slave03、slave04上运行jps,有Worker表明启动成功:
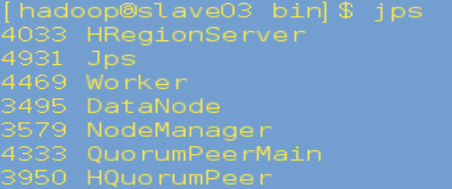
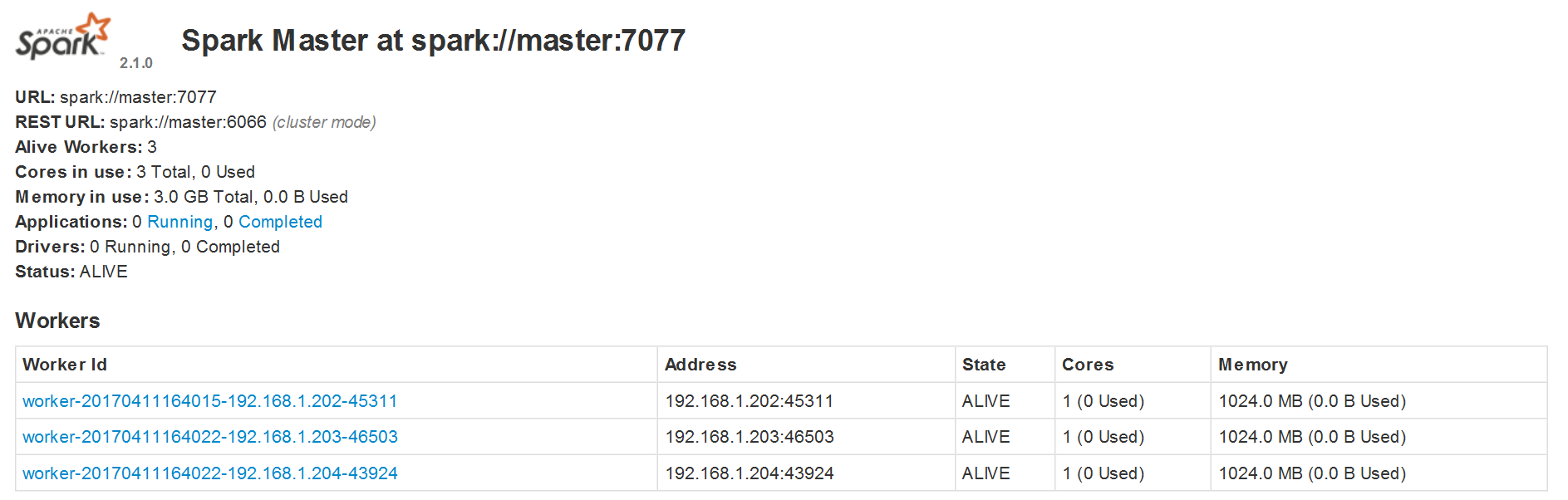
6. 访问http://master:8081,出现下面的页面表明启动成功:
Spark分布式集群的搭建和运行的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
随机推荐
- java获取视频播第一帧
FFMPEG 功能很强大,做视频必备的软件.大家可通过 http://ffmpeg.org/ 了解.Windows版本的软件,可通过 http://ffmpeg.zeranoe.com/builds/ ...
- 每天一个linux命令-curl命令
下载文件 如果我们想要下载文件,而不是查看,那么可以使用如下命令: curl -O http://mif.polimercolor.ru/mifsoft/MDict.zip 以上命令会下载文件并以原名 ...
- 朽木第一至三季/全集Deadwood迅雷下载
英文译名Deadwood,第1-3季(2004-2006)HBO. 本季看点:<朽木>又名<死木>由<纽约重案组>(NYPD Blue)制作人大卫·米奇担纲,讲述美 ...
- Asp.Net Mvc3.0(MEF依赖注入理论)
前言 Managed Extensibility Framework(MEF)是.NET平台下的一个扩展性管理框架,它是一系列特性的集合,包括依赖注入(DI)等.MEF为开发人员提供了一个工具,让我们 ...
- 架构模式逻辑层模式之:表模块(Table Model)
表模块和领域模型比,有两个显著区别: 1:表模块中的类和数据库表基本一一对应,而领域模型则无此要求: 2:表模块中的类的对象处理表中的所有记录,而领域模型的一个对象代表表中的一行记录: 一般情况下,我 ...
- dockerfile介绍
详细说明,阅读这篇文章吧:https://yeasy.gitbooks.io/docker_practice/image/build.html 注意点: 容器是一个进程,不是一个系统 dockerfi ...
- System.Reflection.TargetException:“非静态方法需要一个目标。”
报错:TargetException, 非静态方法需要一个目标,非静态方法 如果实例为null,调用实例方法会报如上错. 解决办法: 检查实例是否为null,考虑什么情况下实例为null,然后排除实例 ...
- Log Shipping搭建
1. 概述 SQL Server 使用日志传送,您可以自动将“主服务器”实例上“主数据库”内的事务日志备份发送到单独“辅助服务器”实例上的一个或多个“辅助数据库”.事务日志备份分别应用于每个辅助 ...
- 测试 Java 类的非公有成员变量和方法
引言 对于软件开发人员来说,单元测试是一项必不可少的工作.它既可以验证程序的有效性,又可以在程序出现 BUG 的时候,帮助开发人员快速的定位问题所在.但是,在写单元测试的过程中,开发人员经常要访问类的 ...
- SGU536 Berland Chess
棋盘上白子只有一个国王 黑子给出 各子遵从国际象棋的走法 黑子不动,白子不能走进黑子的攻击范围以内 问白字能不能吃掉所有的黑子 直接搜索就好了,各子状态用二进制表示 不过每个子被吃之后攻击范围会改变 ...