Spark分布式集群的搭建和运行
集群共三台CentOS虚拟机,一个Matser,主机名为master;三个Worker,主机名分别为master、slave03、slave04。前提是Hadoop和Zookeeper已经安装并且开始运行。
1. 在master上下载Scala-2.11.0.tgz,复制到/opt/下面,解压,在/etc/profile加上语句:
export SCALA_HOME=/opt/scala-2.11.0
export PATH=$PATH:$SCALA_HOME/bin
然后运行命令:
source /etc/profile
在slave03、slave04上也执行相同的操作。
2. 在master上下载spark-2.1.0-bin-hadoop2.6,复制到/opt/下面。解压,在/etc/profile加上语句:
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
然后运行命令:
source /etc/profile
3. 编辑${SPARK_HOME}/conf/spark-env.sh文件,增加下面的语句:
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_121
# SCALA_HOME
export SCALA_HOME=/opt/scala-2.11.0
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
# Master主机名
export SPARK_MASTER_HOST=master
# Worker的内存大小
export SPARK_WORKER_MEMORY=1g
# Worker的Cores数量
export SPARK_WORKER_CORES=1
# SPARK_PID路径
export SPARK_PID_DIR=$SPARK_HOME/tmp
# Hadoop配置文件路径
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0-cdh5.9.0/etc/hadoop
# Spark的Recovery Mode、Zookeeper URL和路径
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:12181,slave03:12181,slave04:12181 -Dspark.deploy.zookeeper.dir=/spark"
在${SPARK_HOME}/conf/slaves中增加:
matser
slave03
slave04
这样就设置了三个Worker。
修改文件结束以后,将${SPARK_HOME}用scp复制到slave03和slave04。
4. 在master上进入${SPARK_HOME}/sbin路径,运行:
./start-master.sh
这是启动Master。
再运行:
./start-slaves.sh
这是启动Worker。
5. 在master上运行jps,如果有Master和Worker表明启动成功:
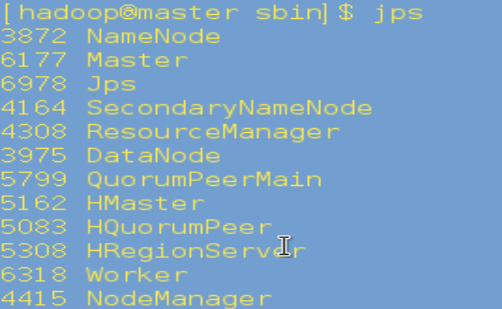
在slave03、slave04上运行jps,有Worker表明启动成功:
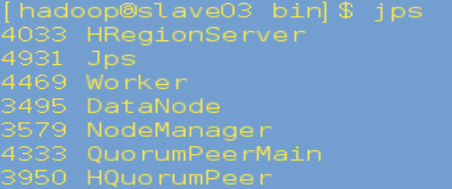
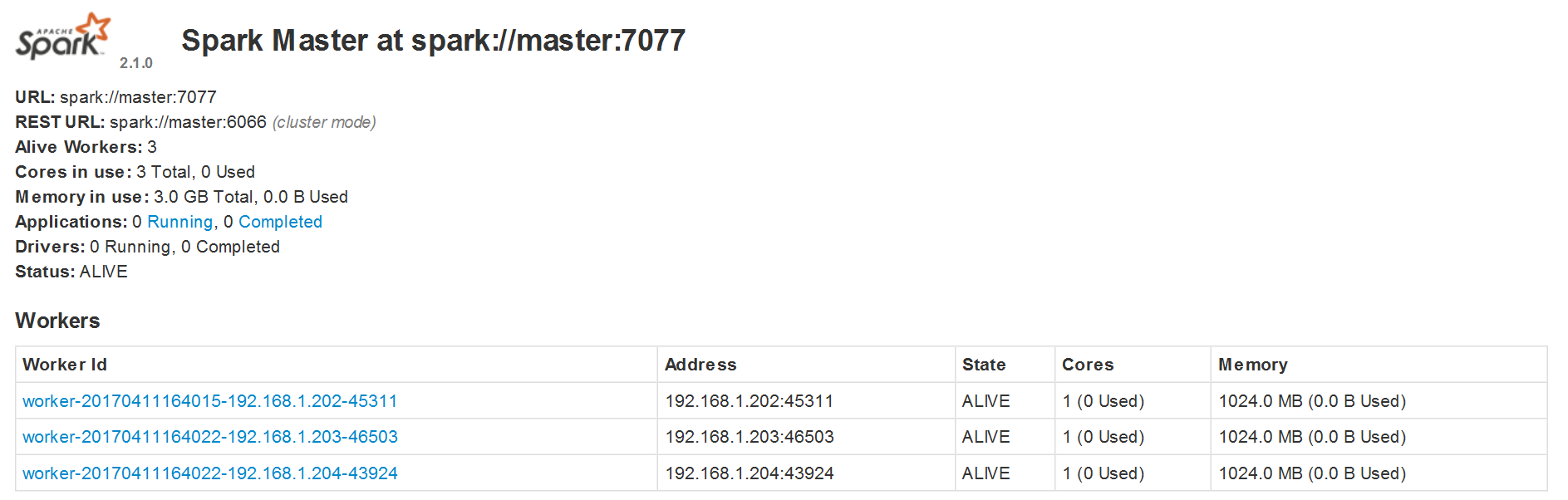
6. 访问http://master:8081,出现下面的页面表明启动成功:
Spark分布式集群的搭建和运行的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
随机推荐
- log4j修改SMTPAppender支持ssl
- 解决html5 audio iphone,ipd,safari不能自动播放问题
html audio 在iPhone,ipd,safari浏览器不能播放是有原因滴 (在safri on ios里面明确指出等待用户的交互动作后才能播放media,也就是说如果你没有得到用户的acti ...
- http和https的区别与联系
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂 ...
- dubbo源码解析-spi(二)
前言 上一篇简单的介绍了spi的基本一些概念,在末尾也提到了,dubbo对jdk的spi进行了一些改进,具体改进了什么,来看看文档的描述 JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩 ...
- B/S架构中常用弹出方法 (转)
<一> 在B/S架构的项目中,为了提高项目的易用性,增强系统与用户的交互功能,一般使用弹出页面来为用户提供操作或数据选择帮助信息,比如,用户输入一个编码中某些字符,在弹出页面中显示所有包含 ...
- [leetcode]ZigZag Conversion @ Python
原题地址:https://oj.leetcode.com/problems/zigzag-conversion/ 题意: The string "PAYPALISHIRING" i ...
- 用Visual C#来清空回收站(2)
四.程序的源代码(recycled.cs).编译方法及运行后的界面: (1).程序的源代码:recycled.cs: using System.IO ; using System.Windows.Fo ...
- C# 二种方法控制系统音量/麦克风大小
场景:在做播放设备的时候需要控制音量的大小,下面几种方法将满足你的要求 方法一: 改变系统音量设置 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ...
- Qt5.3.1 静态编译的configure
今天最终自己静态编译过了QT5.3.1, 成功用在项目上了, 记录下configure指令. configure -confirm-license -opensource -platform win ...
- Packagist 镜像使用方法--composer
镜像用法 有两种方式启用本镜像服务: 系统全局配置: 即将配置信息添加到 Composer 的全局配置文件 config.json 中.见“方法一” 单个项目配置: 将配置信息添加到某个项目的 com ...