强化学习实战 | 自定义Gym环境之扫雷
开始之前
先考虑几个问题:
- Q1:如何展开无雷区?
- Q2:如何计算格子的提示数?
- Q3:如何表示扫雷游戏的状态?
A1:可以使用递归函数,或是堆栈。
A2:一般的做法是,需要打开某格子时,再去统计周围的雷数。如果有方便的二维卷积函数可以调用,这会是个更简洁的方法:
$$\begin{bmatrix}
1 & 0 & 0 & 1 & 0\\
0 & 1 & 0 & 0 & 1\\
1 & 0 & 1 & 0 & 0\\
0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 1
\end{bmatrix}\bigstar
\begin{bmatrix}
1 & 1 & 1\\
1 & 0 & 1\\
1 & 1 & 1
\end{bmatrix}=
\begin{bmatrix}
1 & 2 & 2 & 1 & 2\\
3 & 3 & 3 & 3 & 1\\
1 & 3 & 1 & 2 & 1\\
2 & 3 & 2 & 2 & 1\\
1 & 0 & 1 & 1 & 0
\end{bmatrix}$$
不妨用 $\bigstar$ 表示二维卷积运算。等号左边的5×5矩阵表示了雷的分布情况,值1表示有雷,值0表示无雷;等号左边的3×3矩阵是求解周围雷数的卷积核(或称滤波器,特征提取器);等号右边的矩阵即是所有格子的周围雷数。
代码实现起来也非常简单:
from scipy import signal
import numpy as np
state_mine = np.array([[1,0,0,1,0],[0,1,0,0,1],[1,0,1,0,0],[0,0,0,0,0],[0,1,0,0,1]])
KERNAL = np.array([[1,1,1],[1,0,1],[1,1,1]])
state_num = signal.convolve2d(state_mine, KERNAL, 'same')
A3:对于玩家来说,游戏状态是不完全观测的,也即需要区分观测状态和环境状态。环境状态包括雷分布矩阵,和提示数矩阵(也即上式提到的);观测状态是玩家部分可见的环境状态,需要根据格子的打开状态对雷分布矩阵进行部分屏蔽。观测状态不包括雷分布矩阵,因为一旦触雷即游戏结束,所以游戏中所有非终止状态都是无雷的。
那么对于一个大小为$M \times N$的扫雷游戏,环境状态可以表示为 $M \times N \times 2$ 的张量:频道1是雷分布矩阵,频道2是提示数矩阵;观测状态可以表示为 $M \times N \times 2$ 的张量:频道1是表示格子打开状态的矩阵(值1为打开,值0为未打开),并以此矩阵对 提示数矩阵 进行元素乘,完成对环境状态的部分屏蔽,作为第二个频道。对于numpy.array而言,元素乘是容易的:
observe_num = state_num * state_open
以下图的游戏状态为例说明:
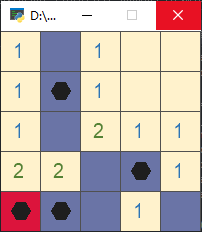
环境状态为:
$$\begin{bmatrix}
& & & & \\
& 1 & & & \\
& & & & \\
& & & 1 & \\
1 & 1 & & &
\end{bmatrix}\times
\begin{bmatrix}
1 & 1 & 1 & 0 & 0\\
1 & 0 & 1 & 0 & 0\\
1 & 1 & 2 & 1 & 1\\
2 & 2 & 2 & 0 & 1\\
1 & 1 & 2 & 1 & 1
\end{bmatrix}$$
观测状态为:
$$\begin{bmatrix}
1 & 0 & 1 & 0 & 0\\
1 & 0 & 1 & 0 & 0\\
1 & 0 & 2 & 1 & 1\\
2 & 2 & 0 & 0 & 1\\
1 & 0 & 0 & 1 & 0
\end{bmatrix}\times
\begin{bmatrix}
1 & & 1 & 1 & 1\\
1 & & 1 & 1 & 1\\
1 & & 1 & 1 & 1\\
1 & 1 & & & 1\\
1 & & & 1 &
\end{bmatrix}$$
但这种表示方式不是唯一的,比如我们可以把提示数矩阵拆成9个频道,分别表示0~8的提示数。那么观测状态就变成了 $M \times N \times 10$ 的张量:
$$\begin{bmatrix}
& & & 1 & 1\\
& & & 1 & 1\\
& & & & \\
& & & & \\
& & & &
\end{bmatrix}\times
\begin{bmatrix}
1 & & 1 & & \\
1 & & 1 & & \\
1 & & & 1 & 1\\
& & & & 1\\
& & & 1 &
\end{bmatrix}\times
\begin{bmatrix}
& & & & \\
& & & & \\
& & 1 & & \\
1 & 1 & & & \\
& & & &
\end{bmatrix}\times
\begin{bmatrix}
& & & & \\
& & & & \\
& & & & \\
& & & & \\
& & & &
\end{bmatrix}\times
\cdots \times
\begin{bmatrix}
& & & & \\
& & & & \\
& & & & \\
& & & & \\
& & & &
\end{bmatrix}\times
\begin{bmatrix}
1 & & 1 & 1 & 1\\
1 & & 1 & 1 & 1\\
1 & & 1 & 1 & 1\\
1 & 1 & & & 1\\
1 & & & 1 &
\end{bmatrix}$$
状态空间的设计是灵活的,唯一的评价的标准是完整的学习系统的性能表现。如果采用以上多频道式的状态空间设计,那么后续可以很方便地使用卷积神经网络开展学习任务。你也可以把张量阵展成一维的向量,然后用全连接神经网络处理。本文后续的实现将采用 $M \times N \times 2$ 的状态空间表达。
步骤1:新建文件
为了运行pytorch,我使用anaconda的环境管理操作创建了名为pytorch1.1的环境名,并在这个环境下安装了openAI gym,因此我来到目录:D:\Anaconda\envs\pytorch1.1\Lib\site-packages\gym\envs\user 下,新建文件 __init__.py 和 MineSweeper_env.py。
步骤2:编写文件 MineSweeper_env.py
一个标准的gym env类包含三个方法:reset(),step(action),和render()。
- reset() 用于初始化环境;
- step(action) 有四个返回值:state,reward,done,和info,因此我们需要在该函数中完成扫雷游戏的全部逻辑;
- render() 用于可视化环境。我在网上没有找到gym的原生方法rendering可以显示文字的说法(如果有知晓的朋友请留言,感谢!),所以是通过pyglet + 动态变量名的方式实现大量字符的显示,具体做法可见 强化学习实战 | 自定义Gym环境之显示字符串。
MineSweeper_env.py 的整体代码如下:
import gym
import random
import time
import numpy as np
from scipy import signal # 二维卷积
import pyglet # 显示文字
from gym.envs.classic_control import rendering class DrawText: # 用于在rendering中显示文字
def __init__(self, label:pyglet.text.Label):
self.label=label
def render(self):
self.label.draw() class MineSweeperEnv(gym.Env):
def __init__(self):
self.MINE_NUM = 20
self.ROW, self.COL = 12, 12
self.SIZE = 40
WIDTH = self.COL * self.SIZE
HEIGHT = self.ROW * self.SIZE
self.viewer = rendering.Viewer(WIDTH, HEIGHT)
self.state_mine = None
self.state_num = None
self.state_open = None
self.gameOver = False def reset(self):
# 初始化:布雷状态
MINE_NUM = self.MINE_NUM
self.state_mine = np.zeros(self.ROW * self.COL)
self.state_mine[:MINE_NUM] = 1
random.shuffle(self.state_mine)
self.state_mine = self.state_mine.reshape(self.ROW, self.COL)
# 初始化:提示数字
KERNAL = np.array([[1,1,1], [1,0,1], [1,1,1]])
self.state_num = signal.convolve2d(self.state_mine, KERNAL, 'same')
# 初始化:打开状态
self.state_open = np.zeros((self.ROW, self.COL))
# 初始化:游戏是否结束
self.gameOver = False def getRoundSet(self, x, y):
roundSet = []
for i in range(x-1, x+2):
for j in range(y-1, y+2):
if 0 <= i < self.ROW and 0 <= j < self.COL and (i, j) != (x, y):
roundSet.append((i, j))
return roundSet def step(self, action):
# 执行动作
x, y = action
# 若打开数字不为0
if self.state_num[x, y] >= 1:
self.state_open[x, y] = 1
# 若打开数字为0 则展开无雷区
if self.state_num[x, y] == 0:
stack = []
stack.append((x, y))
while len(stack):
row, col = stack.pop()
self.state_open[row, col] = 1
for one in self.getRoundSet(row, col):
# 排除已经打开的格子
if self.state_open[one] == 1:
continue
if self.state_num[one] >= 1:
self.state_open[one] = 1
else:
stack.append(one) # 是否获胜或失败/获得奖励
done, reward = False, 0
# 若打开雷 则游戏失败
if self.state_mine[x, y] == 1:
self.state_open[x, y] = 1
self.gameOver = True
done, reward = True, -1
# 若剩余未打开的格子数 = 雷数 则获胜
if ROW*COL - self.state_open.sum() == self.MINE_NUM:
self.gameOver = True
done, reward = True, 1 # 报告(维持gym step的标准格式)
info = {}
# 观测状态
observe_num = self.state_num * self.state_open
observe = [observe_num, self.state_open]
return observe, reward, done, info def render(self, mode='human'):
ROW, COL, SIZE = self.ROW, self.COL, self.SIZE
# 画方块
for i in range(ROW):
for j in range(COL):
X, Y = j*SIZE, (ROW-i-1)*SIZE
tile = rendering.make_polygon([(X,Y), (X+SIZE,Y), (X+SIZE,Y+SIZE), (X,Y+SIZE)], filled=True)
if self.state_open[i,j] == 0:
tile.set_color(106/255,116/255,166/255)
if self.state_open[i,j] == 1 and self.state_mine[i,j] == 0:
tile.set_color(255/255,242/255,204/255)
if self.state_open[i,j] == 1 and self.state_mine[i,j] == 1:
tile.set_color(220/255,20/255,60/255)
self.viewer.add_geom(tile)
# 画分隔线
WIDTH = COL*SIZE
HEIGHT = ROW*SIZE
for i in range(ROW+1):
line = rendering.Line((0, i*SIZE), (WIDTH, i*SIZE))
line.set_color(80/255, 80/255, 80/255)
self.viewer.add_geom(line)
for j in range(COL+1):
line = rendering.Line((j*SIZE, 0), (j*SIZE, HEIGHT))
line.set_color(80/255, 80/255, 80/255)
self.viewer.add_geom(line)
# 画数字
for i in range(ROW):
for j in range(COL):
exec('label_{}_{} = {}'.format(i, j, None))
names = locals()
NUM = int(self.state_num[i,j])
COLOR = (255, 255, 255, 255)
if NUM == 1:
COLOR = (46, 117, 182, 255)
elif NUM == 2:
COLOR = (84, 130, 53, 255)
elif NUM == 3:
COLOR = (192, 0, 0, 255)
elif NUM == 4:
COLOR = (112, 48, 160, 255)
elif NUM == 5:
COLOR = (132, 60, 12, 255)
elif NUM == 6:
COLOR = (191, 144, 0, 255)
elif NUM == 7:
COLOR = (32, 56, 100, 255)
elif NUM == 8:
COLOR = (13, 13, 13, 255)
names['label_' + str(i) + '_' + str(j)] = pyglet.text.Label('{}'.format(NUM), font_size=15,
x=(j+0.32)*SIZE, y=(ROW-i-1+0.23)*SIZE, anchor_x='left', anchor_y='bottom',
color=COLOR)
label = names['label_{}_{}'.format(i, j)]
label.draw()
if self.state_mine[i,j] == 0 and self.state_open[i,j] == 1 and self.state_num[i,j] >= 1:
self.viewer.add_geom(DrawText(label))
# 画雷
if self.gameOver == True:
if self.state_mine[i,j] == 1:
mine = rendering.make_circle(10, 6, filled=True)
mine.set_color(30/255, 30/255, 30/255)
translation = rendering.Transform(translation=((j+0.5)*SIZE, (ROW-i-1+0.5)*SIZE))
mine.add_attr(translation)
self.viewer.add_geom(mine) return self.viewer.render(return_rgb_array=mode == 'rgb_array') # 测试代码:以随机策略执行动作
if __name__ == '__main__':
MineSweeper = MineSweeperEnv()
ROW, COL = MineSweeper.ROW, MineSweeper.COL
MineSweeper.reset()
MineSweeper.render()
while MineSweeper.gameOver is not True:
while True:
rand = random.choice(range(ROW*COL))
x, y = rand//ROW, rand%ROW
if MineSweeper.state_open[x, y] == 0:
action = (x, y)
break
state, reward, done, info = MineSweeper.step(action)
MineSweeper.render()
time.sleep(0.5)
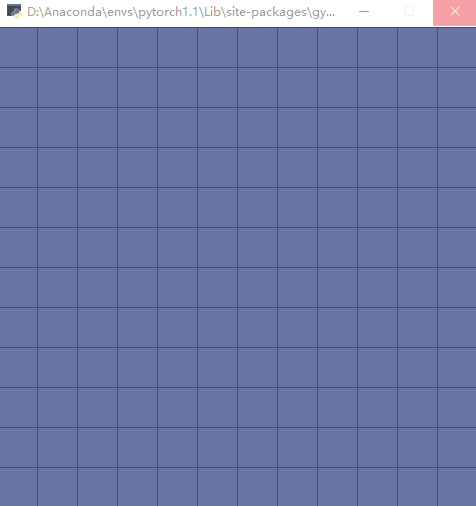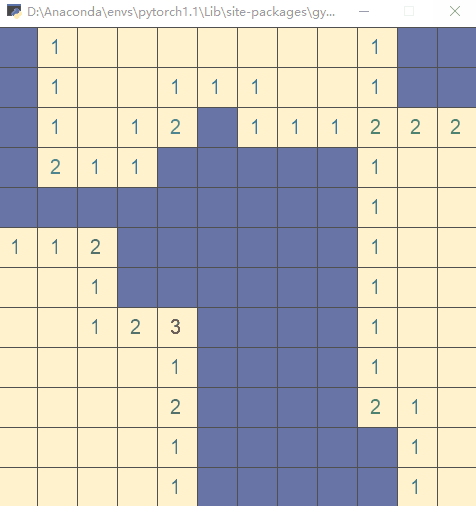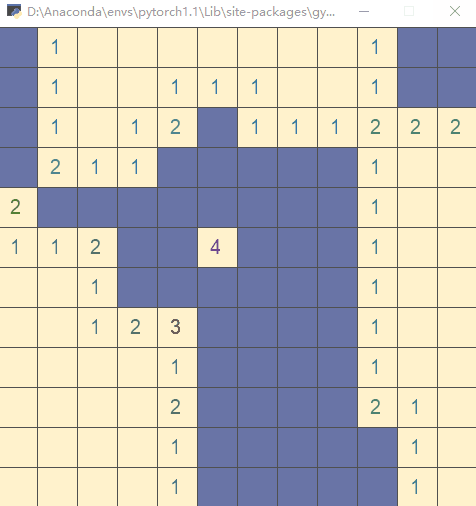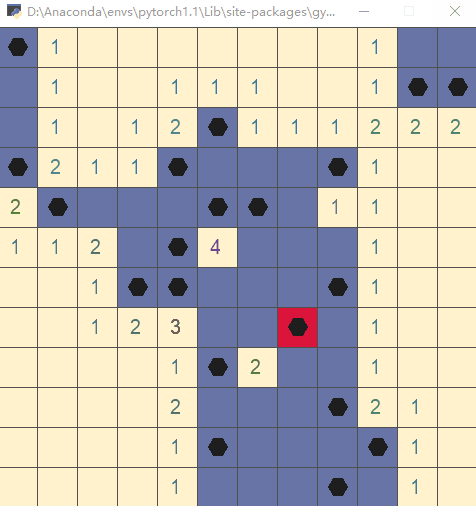
直接运行文件,执行测试代码(以随机策略执行动作):
步骤3:编写 __init__.py
在 __init__.py 中引入类的信息,添加:
from gym.envs.user.MineSweeper_env import MineSweeperEnv
步骤4:注册环境
来到目录:D:\Anaconda\envs\pytorch1.1\Lib\site-packages\gym,打开 __init__.py,添加代码:
register(
id="MineSweeperEnv-v0",
entry_point="gym.envs.user:MineSweeperEnv",
max_episode_steps=200,
)
步骤5:测试环境
在相同的conda环境下,输入代码:
import gym
env = gym.make('MineSweeperEnv-v0')
env.reset()
env.render()
若无报错,则说明gym环境注册成功。
强化学习实战 | 自定义Gym环境之扫雷的更多相关文章
- 强化学习实战 | 自定义Gym环境之井字棋
在文章 强化学习实战 | 自定义Gym环境 中 ,我们了解了一个简单的环境应该如何定义,并使用 print 简单地呈现了环境.在本文中,我们将学习自定义一个稍微复杂一点的环境--井字棋.回想一下井字棋 ...
- 强化学习实战 | 自定义gym环境之显示字符串
如果想用强化学习去实现扫雷.2048这种带有数字提示信息的游戏,自然是希望自定义 gym 环境时能把字符显示出来.上网查了很久,没有找到gym自带的图形工具Viewer可以显示字符串的信息,反而是通过 ...
- 强化学习实战 | 自定义Gym环境
新手的第一个强化学习示例一般都从Open Gym开始.在这些示例中,我们不断地向环境施加动作,并得到观测和奖励,这也是Gym Env的基本用法: state, reward, done, info = ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(一)
在 强化学习实战 | 自定义Gym环境之井子棋 中,我们构建了一个井字棋环境,并进行了测试.接下来我们可以使用各种强化学习方法训练agent出棋,其中比较简单的是Q学习,Q即Q(S, a),是状态动作 ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(二)
在 强化学习实战 | 表格型Q-Learning玩井字棋(一)中,我们构建了以Game() 和 Agent() 类为基础的框架,本篇我们要让agent不断对弈,维护Q表格,提升棋力.那么我们先来盘算一 ...
- 强化学习实战 | 表格型Q-Learning玩井子棋(三)优化,优化
在 强化学习实战 | 表格型Q-Learning玩井字棋(二)开始训练!中,我们让agent"简陋地"训练了起来,经过了耗费时间的10万局游戏过后,却效果平平,尤其是初始状态的数值 ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(四)游戏时间
在 强化学习实战 | 表格型Q-Learning玩井字棋(三)优化,优化 中,我们经过优化和训练,得到了一个还不错的Q表格,这一节我们将用pygame实现一个有人机对战,机机对战和作弊功能的井字棋游戏 ...
- 强化学习-linux安装gym、atari和box2d环境
安装gym和atari环境 pip3 install gym pip3 install gym[atari] pip3 install gym[accept-rom-license] 安装box2d环 ...
- 强化学习-Windows安装gym、atari和box2d环境
安装gym pip3 install gym pip3 install gym[accept-rom-license] 安装atari环境[可选] 下载安装VS build tools 如果出现 OS ...
随机推荐
- 【LeetCode】490. The Maze 解题报告 (C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 BFS 日期 题目地址:https://leetcod ...
- 【LeetCode】1007. Minimum Domino Rotations For Equal Row 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历一遍 日期 题目地址:https://leetc ...
- 【LeetCode】274. H-Index 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/h-index/ ...
- 【LeetCode】91. Decode Ways 解题报告(Python)
[LeetCode]91. Decode Ways 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fux ...
- 1057 - Collecting Gold
1057 - Collecting Gold PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB ...
- Java程序设计基础笔记 • 【第7章 Java中的类和对象】
全部章节 >>>> 本章目录 7.1 理解类和对象 7.1.1 对象 7.1.2 抽象与类 7.1.3 类与对象的关系: 7.2 Java中的类和对象 7.2.1 类的定义 ...
- docker学习:dockefile解析
是什么 DockerFile 是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本 构建三部曲 编写Dockerfile文件 docker build docker run 文件什么样 ...
- Drools创建Maven工程
1.说明 本文介绍创建Drools的Maven工程的方法, 仅使用Eclipse开发工具, 不使用Drools的相关插件, 先创建一个Maven工程, 然后引入Drools的相关依赖即可, 最后再写一 ...
- Log4j2进阶使用(按大小时间备份日志)
1.进阶说明 本文介绍Log4j2进阶使用, 基本使用请参考Log4j2基本使用入门. 本文基于上面的基本使用入门, 主要介绍按照日志大小和时间备份日志, 并且限制备份日志的个数, 以及删除过期的备份 ...
- spring boot + redis --- 心得
1.前言 习惯使用springMVC 配置 redis ,现在使用spring boot ,得好好总结怎么在spring boot 配置和使用 ,区别真的挺大的. 2.环境 spring boot ...