强化学习实战 | 自定义Gym环境之井字棋
在文章 强化学习实战 | 自定义Gym环境 中 ,我们了解了一个简单的环境应该如何定义,并使用 print 简单地呈现了环境。在本文中,我们将学习自定义一个稍微复杂一点的环境——井字棋。回想一下井字棋游戏:
- 这是一个双人回合制博弈游戏,双方玩家使用的占位符是不一样的(圈/叉),动作编写需要区分玩家
- 双方玩家获得的终局奖励是不一样的,胜方+1,败方-1(除非平局+0),奖励编写需要区分玩家
- 终局的条件是:任意行 / 列 / 对角 占满了相同的占位符 or 场上没有空位可以占位
- 从单个玩家的视角看,当前状态 s 下采取动作 a 后,新的状态 s_ 并不是后继状态,而是一个等待对手动作的中间状态,真正的后继状态是对手动作之后产生的状态 s'(除非采取动作 a 后游戏直接结束),如下图所示:
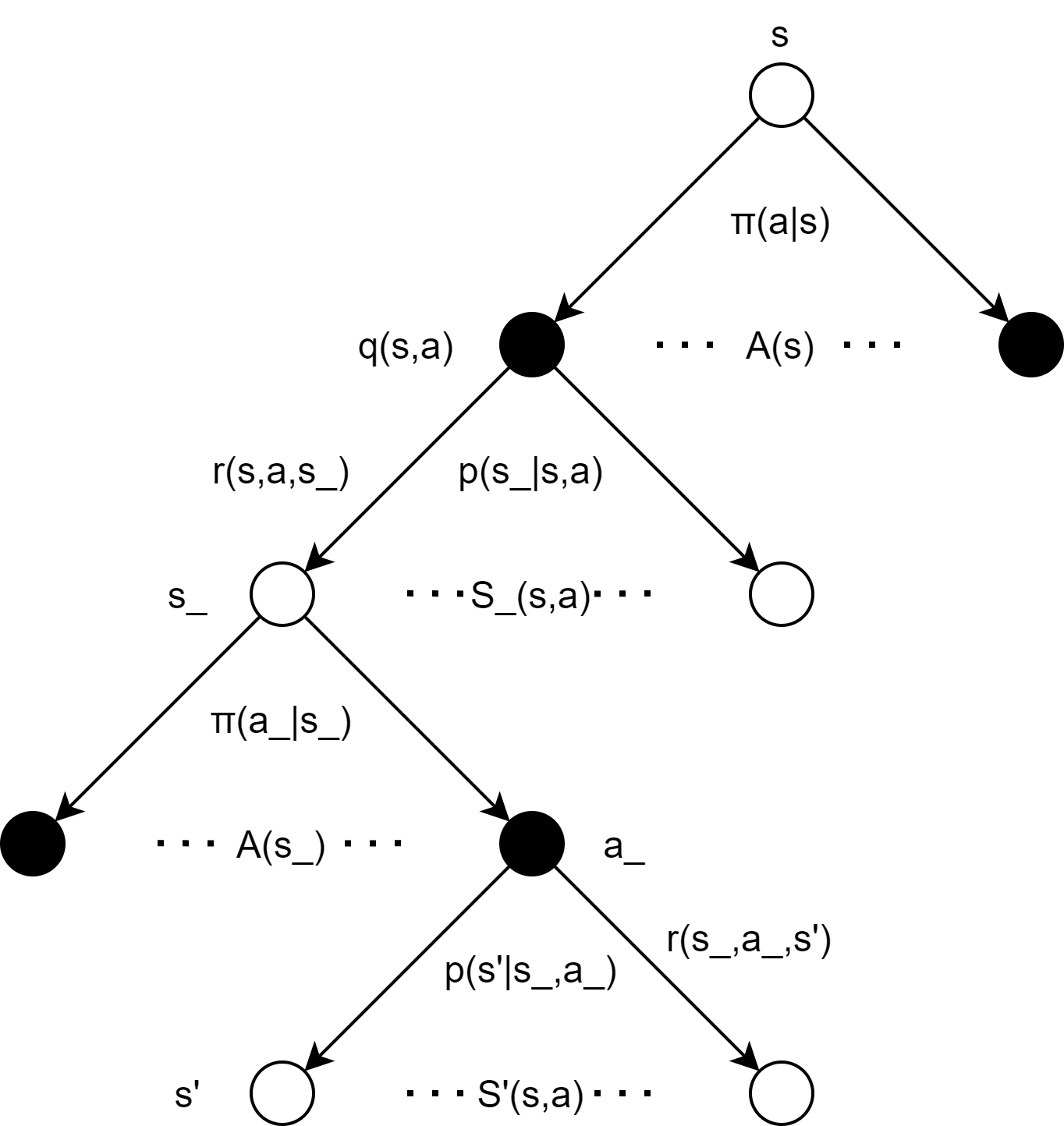
除了游戏本身的机制,考虑到与gym的API接口格式的契合,通过外部循环控制游戏进程是较方便的,所以env本身定义时不必要编写控制游戏进程 / 切换行动玩家的代码。另外,我们还需要更生动的环境呈现方式,而不是print!那么,接下来我们就来实现上述的目标吧!
步骤1:新建文件
来到目录:D:\Anaconda\envs\pytorch1.1\Lib\site-packages\gym\envs\user,创建文件 __init__.py 和 TicTacToe_env.py(还记得吗?文件夹user是文章 强化学习实战 | 自定义Gym环境 中我们创建的用来存放自定义环境的文件夹)。
步骤2:编写 TicTacToe_env.py 和 __init__.py
gym内置了一个绘图工具rendering,不过功能并不周全,想要绘制复杂的东西非常麻烦。本文不打算深入研究,只借助rendering中基本的线条 / 方块 / 圆圈呈现环境(更生动的游戏表现我们完全可以通过pygame来实现)。rendering是单帧绘制的,当调用env.render()时,将呈现当前 self.viewer.geoms 中所记录的绘画元素。环境的基本要素设计如下:
- 状态:由二维的numpy.array表示,无占位符值为0,有蓝色占位符值为1,有红色占位符值为-1。
- 动作:设计为一个字典,有着格式:action = {'mark':'blue', 'pos':(x, y)},其中'mark'表示占位符的颜色,用以区分玩家,'pos'表示占位符的位置。
- 奖励:锁定蓝方视角,胜利+1,失败-1,平局+0。
TicTacToe_env.py 的整体代码如下:
import gym
import random
import time
import numpy as np
from gym.envs.classic_control import rendering class TicTacToeEnv(gym.Env):
def __init__(self):
self.state = np.zeros([3, 3])
self.winner = None
WIDTH, HEIGHT = 300, 300
self.viewer = rendering.Viewer(WIDTH, HEIGHT) def reset(self):
self.state = np.zeros([3, 3])
self.winner = None
self.viewer.geoms.clear() # 清空画板中需要绘制的元素
self.viewer.onetime_geoms.clear() def step(self, action):
# 动作的格式:action = {'mark':'circle'/'cross', 'pos':(x,y)}# 产生状态
x = action['pos'][0]
y = action['pos'][1]
if action['mark'] == 'blue':
self.state[x][y] = 1
elif action['mark'] == 'red':
self.state[x][y] = -1
# 奖励
done = self.judgeEnd()
if done:
if self.winner == 'blue':
reward = 1
else:
reward = -1
else: reward = 0
# 报告
info = {}
return self.state, reward, done, info def judgeEnd(self):
# 检查两对角
check_diag_1 = self.state[0][0] + self.state[1][1] + self.state[2][2]
check_diag_2 = self.state[2][0] + self.state[1][1] + self.state[0][2]
if check_diag_1 == 3 or check_diag_2 == 3:
self.winner = 'blue'
return True
elif check_diag_1 == -3 or check_diag_2 == -3:
self.winner = 'red'
return True
# 检查三行三列
state_T = self.state.T
for i in range(3):
check_row = sum(self.state[i]) # 检查行
check_col = sum(state_T[i]) # 检查列
if check_row == 3 or check_col == 3:
self.winner = 'blue'
return True
elif check_row == -3 or check_col == -3:
self.winner = 'red'
return True
# 检查整个棋盘是否还有空位
empty = []
for i in range(3):
for j in range(3):
if self.state[i][j] == 0: empty.append((i,j))
if empty == []: return True return False def render(self, mode='human'):
SIZE = 100
# 画分隔线
line1 = rendering.Line((0, 100), (300, 100))
line2 = rendering.Line((0, 200), (300, 200))
line3 = rendering.Line((100, 0), (100, 300))
line4 = rendering.Line((200, 0), (200, 300))
line1.set_color(0, 0, 0)
line2.set_color(0, 0, 0)
line3.set_color(0, 0, 0)
line4.set_color(0, 0, 0)
# 将绘画元素添加至画板中
self.viewer.add_geom(line1)
self.viewer.add_geom(line2)
self.viewer.add_geom(line3)
self.viewer.add_geom(line4)
# 根据self.state画占位符
for i in range(3):
for j in range(3):
if self.state[i][j] == 1:
circle = rendering.make_circle(30) # 画直径为30的圆
circle.set_color(135/255, 206/255, 250/255) # mark = blue
move = rendering.Transform(translation=(i * SIZE + 50, j * SIZE + 50)) # 创建平移操作
circle.add_attr(move) # 将平移操作添加至圆的属性中
self.viewer.add_geom(circle) # 将圆添加至画板中
if self.state[i][j] == -1:
circle = rendering.make_circle(30)
circle.set_color(255/255, 182/255, 193/255) # mark = red
move = rendering.Transform(translation=(i * SIZE + 50, j * SIZE + 50))
circle.add_attr(move)
self.viewer.add_geom(circle) return self.viewer.render(return_rgb_array=mode == 'rgb_array')
在 __init__.py 中引入类的信息,添加:
from gym.envs.user.TicTacToe_env import TicTacToeEnv
步骤3:注册环境
来到目录:D:\Anaconda\envs\pytorch1.1\Lib\site-packages\gym,打开 __init__.py,添加代码:
register(
id="TicTacToeEnv-v0",
entry_point="gym.envs.user:TicTacToeEnv",
max_episode_steps=20,
)
步骤4:测试环境
在测试代码中,我们在主循环中让游戏不断地进行。蓝红双方玩家以0.5s的间隔,随机选择空格子动作,代码如下:
import gym
import random
import time # 查看所有已注册的环境
# from gym import envs
# print(envs.registry.all()) def randomAction(env_, mark): # 随机选择未占位的格子动作
action_space = []
for i, row in enumerate(env_.state):
for j, one in enumerate(row):
if one == 0: action_space.append((i,j))
action_pos = random.choice(action_space)
action = {'mark':mark, 'pos':action_pos}
return action def randomFirst():
if random.random() > 0.5: # 随机先后手
first_, second_ = 'blue', 'red'
else:
first_, second_ = 'red', 'blue'
return first_, second_ env = gym.make('TicTacToeEnv-v0')
env.reset() # 在第一次step前要先重置环境 不然会报错
first, second = randomFirst()
while True:
# 先手行动
action = randomAction(env, first)
state, reward, done, info = env.step(action)
env.render()
time.sleep(0.5)
if done:
env.reset()
env.render()
first, second = randomFirst()
time.sleep(0.5)
continue
# 后手行动
action = randomAction(env, second)
state, reward, done, info = env.step(action)
env.render()
time.sleep(0.5)
if done:
env.reset()
env.render()
first, second = randomFirst()
time.sleep(0.5)
continue
效果如下图所示:
强化学习实战 | 自定义Gym环境之井字棋的更多相关文章
- 强化学习实战 | 表格型Q-Learning玩井字棋(一)
在 强化学习实战 | 自定义Gym环境之井子棋 中,我们构建了一个井字棋环境,并进行了测试.接下来我们可以使用各种强化学习方法训练agent出棋,其中比较简单的是Q学习,Q即Q(S, a),是状态动作 ...
- 强化学习实战 | 自定义Gym环境之扫雷
开始之前 先考虑几个问题: Q1:如何展开无雷区? Q2:如何计算格子的提示数? Q3:如何表示扫雷游戏的状态? A1:可以使用递归函数,或是堆栈. A2:一般的做法是,需要打开某格子时,再去统计周围 ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(二)
在 强化学习实战 | 表格型Q-Learning玩井字棋(一)中,我们构建了以Game() 和 Agent() 类为基础的框架,本篇我们要让agent不断对弈,维护Q表格,提升棋力.那么我们先来盘算一 ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(四)游戏时间
在 强化学习实战 | 表格型Q-Learning玩井字棋(三)优化,优化 中,我们经过优化和训练,得到了一个还不错的Q表格,这一节我们将用pygame实现一个有人机对战,机机对战和作弊功能的井字棋游戏 ...
- 强化学习实战 | 自定义gym环境之显示字符串
如果想用强化学习去实现扫雷.2048这种带有数字提示信息的游戏,自然是希望自定义 gym 环境时能把字符显示出来.上网查了很久,没有找到gym自带的图形工具Viewer可以显示字符串的信息,反而是通过 ...
- 强化学习实战 | 自定义Gym环境
新手的第一个强化学习示例一般都从Open Gym开始.在这些示例中,我们不断地向环境施加动作,并得到观测和奖励,这也是Gym Env的基本用法: state, reward, done, info = ...
- 强化学习实战 | 表格型Q-Learning玩井子棋(三)优化,优化
在 强化学习实战 | 表格型Q-Learning玩井字棋(二)开始训练!中,我们让agent"简陋地"训练了起来,经过了耗费时间的10万局游戏过后,却效果平平,尤其是初始状态的数值 ...
- [游戏学习22] MFC 井字棋 双人对战
>_<:太多啦,感觉用英语说的太慢啦,没想到一年做的东西竟然这么多.....接下来要加速啦! >_<:注意这里必须用MFC和前面的Win32不一样啦! >_<:这也 ...
- quick cocos2d-x 入门---井字棋
学习quick cocos2d-x 第二天 ,使用quick-x 做了一个井字棋游戏 . 我假设读者已经 http://wiki.quick-x.com/doku.php?id=zh_cn阅读了这个链 ...
随机推荐
- 2021.9.9考试总结[NOIP模拟50]
T1 第零题 神秘结论:从一个点满体力到另一个点的复活次数与倒过来相同. 于是预处理出每个点向上走第$2^i$个死亡点的位置,具体实现可以倍增或二分. 每次询问先从两个点同时向上倍增,都转到离$LCA ...
- 2021.8.21考试总结[NOIP模拟45]
T1 打表 由归纳法可以发现其实就是所有情况的总和. $\frac{\sum_{j=1}^{1<<k}(v_j-v_{ans})}{2^k}$ $code:$ 1 #include< ...
- DP接口中AUX
背景技术: DP接口(DisplayPort)是一种图像显示接口,它不仅可以支持全高清显示分辨率(1920×1080),还能支持4k分辨率(3840×2160),以及最新的8k分辨率(7680×432 ...
- 零基础学习C语言字符串操作总结大全
本篇文章是对C语言字符串操作进行了详细的总结分析,需要的朋友参考下 1)字符串操作 strcpy(p, p1) 复制字符串 strncpy(p, p1, n) 复制指定长度字符串 strcat(p, ...
- Verdi Protocol Analyzer Debug 简单使用
转载:Verdi Protocol Analyzer Debug 简单使用_Holden_Liu的博客-CSDN博客_verdi 技巧 文档与源码: User Guide: UVMDebugUserG ...
- jquery正则表达式验证【是否带有小数、是否中文名称组成、是否全由8位数字组成、电话码格式、邮件地址】
1 <form name="myform" action="" onsubmit="return fun1()"> 2 < ...
- Python import commands ImportError: No module named 'commands'
ImportError: No module named 'commands' 在Python3中执行shell脚本,想要获取其执行状态和标准输出.错误输出 的数据,遇到这个错误,原因是command ...
- Mysql 5.7 集群部署,keepalived
参考文章: https://blog.csdn.net/f18770366447/article/details/80703347 https://www.cnblogs.com/benjamin77 ...
- 浅谈对typora的使用
内容概要 - 什么是typora - typora的具体使用 目录 内容概要 - 什么是typora - typora的具体使用 1. 什么是typora 2.typora的具体使用 1.标题级别 2 ...
- React 三大属性state,props,refs以及组件嵌套的应用
React 三大属性state,props,refs以及组件嵌套的应用 该项目实现了一个简单的表单输入添加列表的内容 代码如下 <!DOCTYPE html> <html> & ...