Spark(八)【广播变量和累加器】
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
一. 广播变量
分布式共享只读变量
使用广播变量前
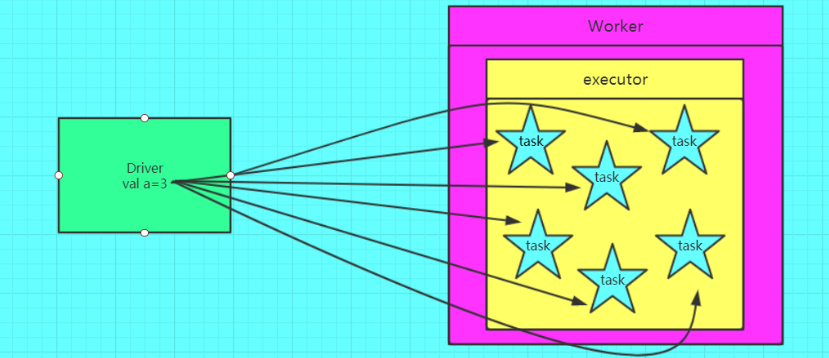
使用广播变量后
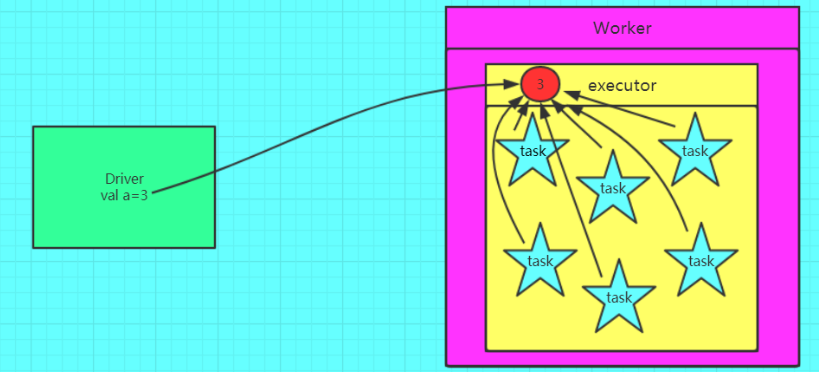
- 广播变量是将变量复制到每一台机器上而不是普通变量那样复制到每个task上,从图二可以看出变量先是从远程的driver上复制到一台机器上,然后这台机器的task就从这台机器上获取变量,不需要再从远程节点上获取,减少了IO,加快了速率。广播变量只能读取,并不能修改。经典应用是大表与小表的join中通过广播变量小表来实现以brodcast join 取代reduce join
- 广播是driver进行的操作,必须是有结果的变量,故不可能直接广播RDD,常常的是将通过collectAsMap算子将需要广播的RDD转换成Map集合然后广播出去
- 变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
使用
sc.broadcast 方法包装变量
bc.value 去除值
/**
* 广播变量
*/
def broadcast_test: Unit = {
val list = List(1, 2, 3, 4)
val rdd = sc.makeRDD(list, 2)
val list1 = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
//使用广播变量将list2包装起来
val bc: Broadcast[List[Int]] = sc.broadcast(list)
//使用.value方法去除广播变量中的值
rdd.filter(x => bc.value.contains(list))
}
注意
① 能不能将一个RDD使用广播变量广播出去?不能 ,因为RDD是不存数据的。可以将RDD的结果广播出去。
② 广播变量不能被修改,必须是只读
二. 累加器
分布式只写变量
累加器用来对信息进行聚合,通常在向 Spark传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用Driver中定义的变量,但是集群中运行的每个task任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
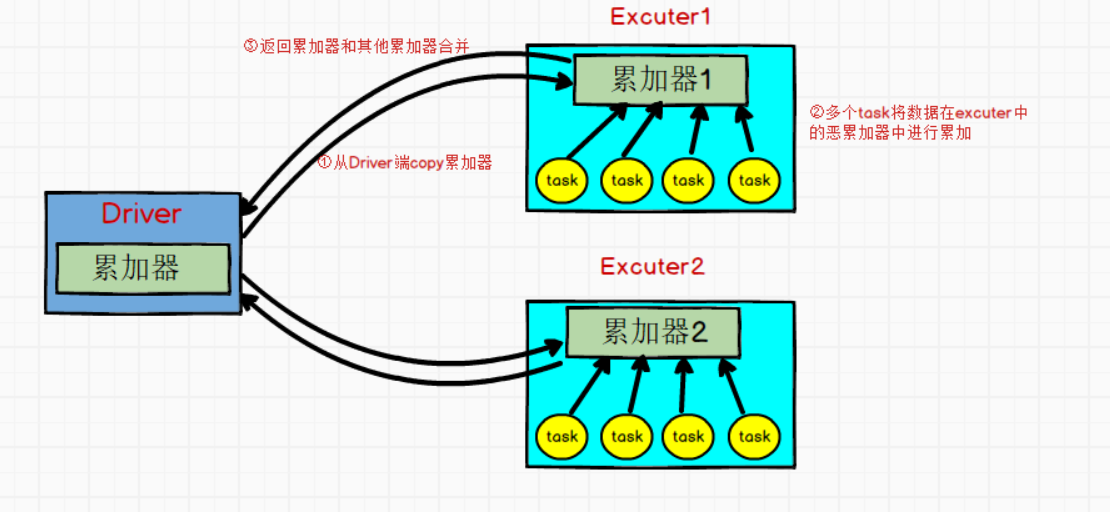
使用
1)基本类型
//1.创建一个累加器
acc : LongAccumulator = sc.longAccumulator("累加器名")
//2.在rdd中使用累加器进行累加
acc.add("值")
2)自定义类型
//TODO 创建一个累加器
val accumulator: WordCountAccumulator = new WordCountAccumulator
//TODO 注册累加器
sc.register(accumulator)
//调用add方法累加数据
rdd.foreach(x=>accumulator.add(x))
使用累加器前
val rdd = sc.makeRDD(List(3, 4, 5, 12, 43, 2), 4)
var sum = 0
rdd.foreach(sum += _)
print(sum)
//sum输出为0
使用累加器后
/**
* 累加器
*/
@Test
def accumulator {
val rdd = sc.makeRDD(List(3, 4, 5, 12, 43, 2), 2)
//创建一个累加器
val acc: LongAccumulator = sc.longAccumulator("sum")
//rdd计算中使用累加器进行累加
rdd.foreach(acc.add(_))
print(acc.value)
}
使用场景
模拟 counter(计数器) 或 执行sum(累加求和), 避免了Shuffle。
Spark默认只提供数值类型(整数,浮点)的累加器
自定义累加器
需求:实现WordCount案例
①自定义一个累加器类
//0.继承AccumulatorV2[IN,OUT]:声明两个泛型,IN:需要累加的数据类型。OUT:累加器返回的数据类型
class WordCountAccumulator() extends AccumulatorV2[String, mutable.Map[String, Int]] {
//1.用Map接收数据, 返回结果
private val result: mutable.Map[String, Int] = new mutable.HashMap[String, Int]()
//2.判断当前累加器是否为初始化状态
override def isZero: Boolean = result.isEmpty
//3.复制累加器对象
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = new WordCountAccumulator
//4.重置累加器
override def reset(): Unit = result.clear()
//5.往累加器中累加数据
override def add(v: String): Unit = {
//将单词v添加进map集合,若不存在key为v的数据,value就设为0,然后加1;若已经存在key为v的数据,直接在value基础上加1.
result.put(v, result.get(v).getOrElse(0) + 1)
}
//6.当前累加器和其他累加器合并
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
//变量other累加器结果,添加进当前累加器
other.value.foreach {
case (word, count) => result.put(word, result.get(word).getOrElse(0) + count)
}
}
//7.获取累加器结果
override def value: mutable.Map[String, Int] = result
}
②使用累加器进行编程
/**
* 自定义累加器
*/
@Test
def accumulator {
val rdd = sc.makeRDD(List("hello","spark","hello","hello","scala","spark"), 2)
//TODO 创建一个累加器
val accumulator: WordCountAccumulator = new WordCountAccumulator
//TODO 注册累加器
sc.register(accumulator)
//调用add方法累加数据
rdd.foreach(x=>accumulator.add(x))
print(accumulator.value)
}
参考:
Spark累加器(Accumulator)陷阱及解决办法
Spark(八)【广播变量和累加器】的更多相关文章
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
- Spark学习之路 (四)Spark的广播变量和累加器[转]
概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上,并 ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
随机推荐
- jQuery根据地址获取经纬度
一.HTML部分 1 @*景区位置*@ 2 <tr> 3 <th>景区名称:</th> 4 <td><input class="txt ...
- hdu 2860 Regroup(并查集)
题意: AP x yA recruit with ability rate x were asked to join company y. (0<=x<2^31, 0<=y<n ...
- 开源的分布式事务框架 springcloud Alibaba Seata 的搭建使用 一次把坑踩完。。。
seata的使用 1. Seata 概述 Seata 是 Simple Extensible Autonomous Transaction Architecture 的简写,由 feascar 改名而 ...
- 【java+selenium3】自动化截图 (十四)
一.截图 1. Firefox浏览器截图 FirefoxDriver firefoxDriver = new FirefoxDriver(); firefoxDriver.getScreenshotA ...
- Spring 之 BeanFactory 源码 - 抽象/类 分析
BeanFactory的基本类体系结构(类为主):
- [atARC115F]Migration
称$k$个物品的位置$(a_{1},a_{2},...,a_{k})$为一个状态,并设初始状态为$S$,结束状态为$T$ 定义状态的比较:首先根据$\sum_{i=1}^{k}h_{a_{i}}$,即 ...
- 一文带你吃透CLR垃圾回收机制
前言 今天我们来共同学习一下CLR的垃圾回收机制,这对我们写出健壮性的代码很有帮助,也许有人会认为多此一举,认为垃圾回收交给CLR就行,我不用关心这个,诚然,大多数情况下是这样的,但是,我们今天讨论的 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- File与IO基础
IO流的作用:持久化到磁盘 File类的使用 File类基本概念 文件和文件夹都是用File类来表示. File类是内存层面的对象,内存中创建出来的File对象不一定有一个真实存在的文件或文件夹,但是 ...
- 洛谷 P4548 - [CTSC2006]歌唱王国(概率生成函数)
洛谷题面传送门 PGF 入门好题. 首先介绍一下 PGF 的基本概念.对于随机变量 \(X\),满足 \(X\) 的取值总是非负整数,我们即 \(P(v)\) 表示 \(X=v\) 的概率,那么我们定 ...