Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
原文:Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来。目前Lucene.Net的分词库很不完善,实际应用价值不高。唯一能用在实际场合的StandardAnalyzer类,效果也不是很好。内置在Lucene.Net里的分词都被放在项目的Analysis目录下,也就是Lucene.Net.Analysis命名空间下。分词类的命名一般都是以“Analyzer”结束,比如StandardAnalyzer,StopAnalyzer,SimpleAnalyzer等。全部继承自Analyzer类。而它们一般各有一个辅助类,一般以”“Tokenizer”结尾,分词的逻辑大都在辅助类完成。
使用Lucene.Net,要很好地使用Lucene.Net,必须理解分词,甚至能自己扩展分词。如果只使用拉丁语系,那么使用内置的分词可能足够了,但是对于中文肯定是不行的。目前中文方面的分词分为单字分词,二元分词,词库匹配,语义理解这几种。StandardAnalyzer类就是按单字分,二元分就是把两个字作为一组拆分,而词库的话肯定是有一个复杂的对比过程,语义理解的就更加复杂了。这是分词的方式,而匹配的方式也分为正向和逆向两种,一般逆向要优于正向,但是写起来也要复杂一些。
1、内置分词器
本节将详细介绍Lucene.Net内置分词的效果,工作过程,及整体结构。
1.1、分词效果
1.1.1 如果得到分词效果
如果得到分词效果?有效的方式就是进行测试。这里将引入自动测试的方法,这样更加便于测试,将使用NUnit来完成。Nunit的简单实用方法见附录二。
创建一个新的项目,命名为Test。步骤如图 1.1.1.1 - 1.1.1.2
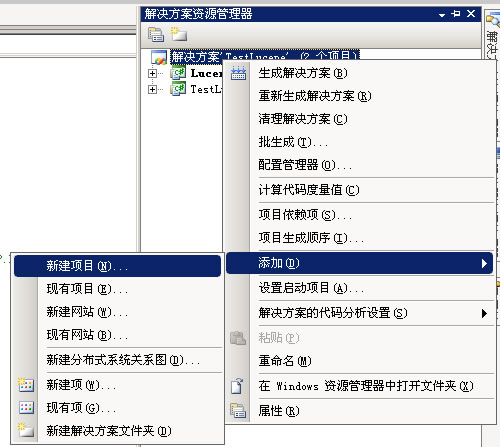
图1.1.1.1
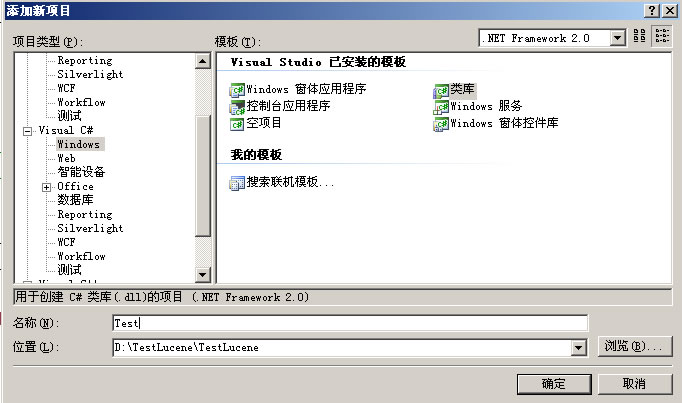
图 1.1.1.2
点确定,就加入了新项目Test,选择类库模板。再引用Nunit.framework类库。如图 1.1.1.3。
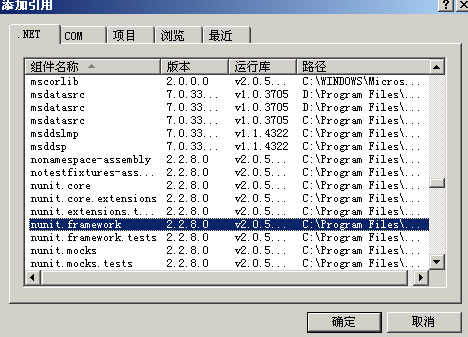
图 1.1.1.3
再按第一章节的步骤引入Lucene.Net类库。先来试试SimpleAnalyzer类的效果。在Test项目中添加SimpleAnalyzerTest,代码 1.1.1.1。
代码 1.1.1.1
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using NUnit.Framework; 5using Lucene.Net.Analysis; 6using System.IO; 7namespace Test 8{ 9 [TestFixture]10 public class SimpleAnalyzerTest11 {12 [Test]13 public void ReusableTokenStreamTest()14 {15 string testwords = "我是中国人,I can speak chinese!";1617 SimpleAnalyzer simple = new SimpleAnalyzer();18 TokenStream ts = simple.ReusableTokenStream("", new StringReader(testwords));19 Token token;20 while ((token = ts.Next()) != null)21 {22 Console.WriteLine(token.TermText());23 }24 ts.Close();25 }26 }27}28
运行结果:
我是中国人
i
can
speak
chinese
查看这个结果,基本可以确定,SimpleAnalyzer分词就是以空格或符号为断点,把句子分析出来。对于英文大写还会执行一个转换到小写的操作。
1.1.2 内置分词的分词效果
按照1.1.1节介绍的方式,就可以分析分析效果了。不过这样写出来的测试代码过于麻烦,改造一下。
(1)、在Test项目中新建Analysis目录;
(2)、在Analysis下建立TestData类,代码1.1.2.1;
代码1.1.2.1
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4 5namespace Test.Analysis 6{ 7 public class TestData 8 { 9 public static string TestWords = "我是中国人,I can speak chinese!";10 }11}12
(3)、建立TestFactory类,代码1.1.2.2
代码1.1.2.2
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using Lucene.Net.Analysis; 5using System.IO; 6 7namespace Test.Analysis 8{ 9 public class TestFactory10 {11 public static void TestFunc(Analyzer analyzer)12 {13 TokenStream ts = analyzer.ReusableTokenStream("", new StringReader(TestData.TestWords));14 Token token;15 while ((token = ts.Next()) != null)16 {17 Console.WriteLine(token.TermText());18 }19 ts.Close();20 }21 }22}
(4)、建立AllAnalysisTest类,代码1.1.2.3
代码1.1.2.3
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using NUnit.Framework; 5using Lucene.Net.Analysis; 6using Lucene.Net.Analysis.Standard; 7namespace Test.Analysis 8{ 9 [TestFixture]10 public class AllAnalysisTest11 {12 [Test]13 public void TestMethod()14 {15 List<Analyzer> analysis = new List<Analyzer>() { 16 new KeywordAnalyzer(),17 new SimpleAnalyzer(),18 new StandardAnalyzer(),19 new StopAnalyzer(),20 new WhitespaceAnalyzer() };2122 for (int i = 0; i < analysis.Count; i++)23 {24 Console.WriteLine(analysis[i].ToString() + "结果:");25 Console.WriteLine("--------------------------------");26 TestFactory.TestFunc(analysis[i]);27 Console.WriteLine("--------------------------------");28 }29 }30 }31}32
(5)、运行。
对于TestWords = "我是中国人,I can speak chinese!";测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I can speak chinese!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I
can
speak
chinese!
--------------------------------
换一句话试试:更改TestData类TestWords字段值为“我是中国人,I'can speak chinese,hello world,沪江小Q!”。测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese,hello world,沪江小Q!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i'can
speak
chinese
沪
江
小
q
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I'can
speak
chinese,hello
world,沪江小Q!
--------------------------------
对于这几种分词效果基本可以看出来了。
KeywordAnalyzer分词,没有任何变化;
SimpleAnalyzer对中文效果太差;
StandardAnalyzer对中文单字拆分;
StopAnalyzer和SimpleAnalyzer差不多;
WhitespaceAnalyzer只按空格划分。
当然,这只是个粗略的结果。
Lucene.Net 2.3.1开发介绍 —— 二、分词(一)的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(六) Lucene.Net的上一个版本是2.1,而在2.3.1版本中才引入了Next(Token)方法重载,而ReusableStrin ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(五) 2.1.3 二元分词 上一节通过变换查询表达式满足了需求,但是在实际应用中,如果那样查询,会出现另外一个问题,因为,那样搜索,是只 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(三) 1.3 分词器结构 1.3.1 分词器整体结构 从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(四) 2.1.2 可以使用的内置分词 简单的分词方式并不能满足需求.前文说过Lucene.Net内置分词中StandardAnalyze ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(二) 1.2.分词的过程 1.2.1.分词器工作的过程 内置的分词器效果都不好,那怎么办?只能自己写了!在写之前当然是要先看看内置的分词 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(二)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(二) 4.3 表达式用户搜索,只会输入一个或几个词,也可能是一句话.输入的语句是如何变成搜索条件的上一篇已经略有提及. 4.3.1 观察 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(二)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(二) 2.索引中用到的核心类 在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类.其中Analyzer是索引建立的 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(四)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(四) 4.索引对搜索排序的影响 搜索的时候,同一个搜索关键字和同一份索引,决定了一个结果,不但决定了结果的集合,也确定了结果的顺序.那个 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(三)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(三) Lucene有表达式就有运算符,而运算符使用起来确实很方便,但另外一个问题来了. 代码 4.3.4.1 Analyzer anal ...
随机推荐
- ACM第三次比赛UVA11877 The Coco-Cola Store
Once upon a time, there is a special coco-cola store. If you return three empty bottles to the sho ...
- Selenium Grid跨浏览器-兼容性测试
Selenium Grid跨浏览器-兼容性测试 这里有两台机子,打算这样演示: 一台机子启动一个作为主点节的hub 和 一个作为次节点的hub(系统windows 浏览器为ie) ip为:192.16 ...
- 【ant项目构建学习点滴】--(3)打包及运行jar文件
<?xml version="1.0" encoding="UTF-8"?> <project default="compile&q ...
- Python 第一篇:python简介和入门
一.python简介 1.python下载地址:https://www.python.org/downloads/ Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆 ...
- WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于HTTP-GET的实现](提供模拟程序)
原文:WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于HTTP-GET的实现](提供模拟程序) 基于HTTP-GET的元数据发布方式与基于WS-MEX原理类似,但是ServiceMetad ...
- Mapper XML Files详解
扫扫关注"茶爸爸"微信公众号 坚持最初的执着,从不曾有半点懈怠,为优秀而努力,为证明自己而活. Mapper XML Files The true power of MyBatis ...
- AV_百度百科
AV_百度百科 AV(影片门类)
- Mac中MacPorts安装和使用
文章转载至http://www.zikercn.com/node/8 星期四, 06/07/2012 - 19:02 - 张慧敏 MacPorts简单介绍 MacPorts,以前叫做DarwinPor ...
- ListView 使用方法(Asp.Net)
您将须要用到的独有数据绑定控件. Fritz Onion 代码下载位置: ExtremeASPNET2008_03.exe (192 KB) Browse the Code Online 文件夹 L ...
- int 转换成 CString(VC2008里有这个问题)
int s = 123; CString str; str.Format("%d",s); 这样就可以了,但是有的会提示这个错误 如果出现这个错误,就改成下面这个就OK了: st ...