python爬虫从入门到放弃(七)之 PyQuery库的使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
初始化
初始化的时候一般有三种传入方式:传入字符串,传入url,传入文件
字符串初始化
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
''' from pyquery import PyQuery as pq
doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
结果如下:
由于PyQuery写起来比较麻烦,所以我们导入的时候都会添加别名:
from pyquery import PyQuery as pq
这里我们可以知道上述代码中的doc其实就是一个pyquery对象,我们可以通过doc可以进行元素的选择,其实这里就是一个css选择器,所以CSS选择器的规则都可以用,直接doc(标签名)就可以获取所有的该标签的内容,如果想要获取class 则doc('.class_name'),如果是id则doc('#id_name')....
URL初始化
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')
print(doc('head'))
文件初始化
我们在pq()这里可以传入url参数也可以传入文件参数,当然这里的文件通常是一个html文件,例如:pq(filename='index.html')
基本的CSS选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
这里我们需要注意的一个地方是doc('#container .list li'),这里的三者之间的并不是必须要挨着,只要是层级关系就可以,下面是常用的CSS选择器方法:
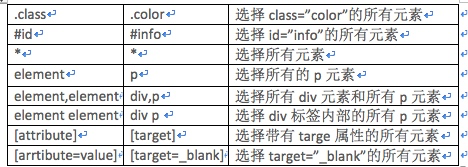
查找元素
子元素
children,find
代码例子:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)
运行结果如下
从结果里我们也可以看出通过pyquery找到结果其实还是一个pyquery对象,可以继续查找,上述中的代码中的items.find('li') 则表示查找ul里的所有的li标签
当然这里通过children可以实现同样的效果,并且通过.children方法得到的结果也是一个pyquery对象
li = items.children()
print(type(li))
print(li)
同时在children里也可以用CSS选择器
li2 = items.children('.active') print(li2)
父元素
parent,parents方法
通过.parent就可以找到父元素的内容,例子如下:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)
通过.parents就可以找到祖先节点的内容,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)
结果如下:从结果我们可以看出返回了两部分内容,一个是的父节点的信息,一个是父节点的父节点的信息即祖先节点的信息
同样我们通过.parents查找的时候也可以添加css选择器来进行内容的筛选
兄弟元素
siblings
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())
代码中doc('.list .item-0.active') 中的.tem-0和.active是紧挨着的,所以表示是并的关系,这样满足条件的就剩下一个了:thired item的那个标签了
这样在通过.siblings就可以获取所有的兄弟标签,当然这里是不包括自己的
同样的在.siblings()里也是可以通过CSS选择器进行筛选
遍历
单个元素
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li) lis = doc('li').items()
print(type(lis))
for li in lis:
print(type(li))
print(li)
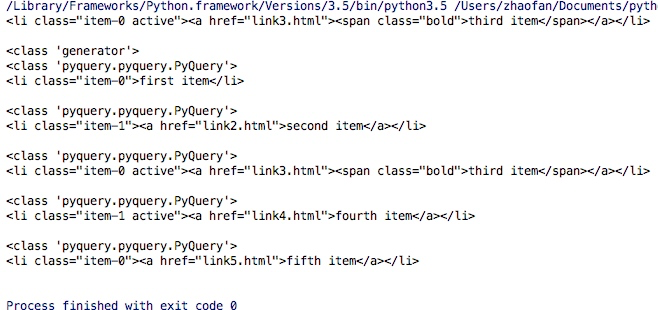
运行结果如下:从结果中我们可以看出通过items()可以得到一个生成器,并且我们通过for循环得到的每个元素依然是一个pyquery对象。
获取信息
获取属性
pyquery对象.attr(属性名)
pyquery对象.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)
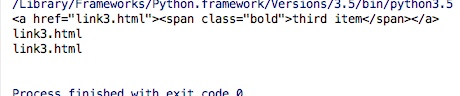
所以这里我们也可以知道获得属性值的时候可以直接a.attr(属性名)或者a.attr.属性名
获取文本
在很多时候我们是需要获取被html标签包含的文本信息,通过.text()就可以获取文本信息
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())
结果如下:

获取html
我们通过.html()的方式可以获取当前标签所包含的html信息,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())
结果如下:

DOM操作
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)
attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)
结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())
结果如下:

pyquery中DOM的其他api操作参考:
http://pyquery.readthedocs.io/en/latest/api.html
python爬虫从入门到放弃(七)之 PyQuery库的使用的更多相关文章
- python爬虫从入门到放弃(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用(转)
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫从入门到放弃(二)之爬虫的原理
在上文中我们说了:爬虫就是请求网站并提取数据的自动化程序.其中请求,提取,自动化是爬虫的关键!下面我们分析爬虫的基本流程 爬虫的基本流程 发起请求通过HTTP库向目标站点发起请求,也就是发送一个Req ...
- python爬虫从入门到放弃(三)之 Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- python爬虫从入门到放弃(八)之 Selenium库的使用
一.什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- Caffe学习系列(四)之--训练自己的模型
前言: 本文章记录了我将自己的数据集处理并训练的流程,帮助一些刚入门的学习者,也记录自己的成长,万事起于忽微,量变引起质变. 正文: 一.流程 1)准备数据集 2)数据转换为lmdb格式 3)计算 ...
- Anaconda配置多spyder多python环境
作者:桂. 时间:2017-04-17 22:02:37 链接:http://www.cnblogs.com/xingshansi/p/6725298.html 前言 最近在看<统计学习方法 ...
- netcore实践:跨平台动态加载native组件
缘起netcore框架下实现基于zmq的应用. 在.net framework时代,我们进行zmq开发由很多的选择,比较常用的有clrzmq4和NetMQ. 其中clrzmq是基于libzmq的Int ...
- 初学strurs基础
Struts2基础学习总结 Struts 2是在WebWork2基础发展而来的. 注意:struts 2和struts 1在代码风格上几乎不一样. Struts 2 相比Struts 1的优点: 1. ...
- jquery分页插件的修改
前言 最近分页功能使用的比较多,所以从网上下载个jquery分页插件来使用, 之前用的都挺好的,直到昨天出现了逻辑问题,反复查看自己的代码,最后发现是点击页码后执行了多个点击事件.最后只有自己查看源码 ...
- python13_day4
上周复习 1,python基础 2,基本数据类型 3,函数式编程 函数式编程.三元运行.内置函数.文件处理 容易出问题的点 函数默认返回值为none,对于列表字典,传入引用. 1 2 3 4 5 6 ...
- 创建,删除DOM
需求说明: 1.上传图片,有删除功能,可上传5张,至少上传一张 html代码如下 <div class="imgUpBox"> <div class=" ...
- 关于特殊文件权限:suid、sgid和sticky-bit
用 ls –l 命令时,能看到三个八进制数字,表示文件的权限.其实文件的权限应该用4个八进制文件来表示,没有显示的那个是第一位,用来设定一些特殊的权限,这个八进制数字的三个位是:SUID.SGID.s ...
- Spring框架基础知识
本人博客文章网址:https://www.peretang.com/basic-knowledge-of-spring-framework/ Spring框架简介 Spring , 一个开源的框架 , ...
- 使用CSS3中的input标签与lable标签组合实现banner图的切换
在做网页时,我们经常可以碰到banner图的切换.对于那些JS薄弱的同学来说,这就很尴尬了.今天,我来告诉大家如何使用CSS做出banner图切换的效果. 这里,用到了lable标签与input的组合 ...