【hadoop】MapReduce分布式计算框架原理
PS:实操部分就省略了哈,准备最近好好看下理论这块,其实我是比较懒得哈!!!
<?>MapReduce的概述
MapReduce是一种计算模型,进行大数据量的离线计算。
MapReduce实现了Map和Reduce两个功能:
其中Map是滴数据集上的独立元素进行指定的操作,生成键——值对形式中间结果。
其中Reduce则对中间结果中相同“键”的所有“值”进行规约(分类和归纳),以得到最终结果。
<?>如何进行并行分布式计算?
并行计算(如SPARK)
是相对于串行计算而言,一般可分为时间并行和空间并行。时间并行可以看做是流水线操作,类似CPU执行的流水线,而空间并行则是目前大多数研究的问题,例如一台机器拥有多个处理器,在多个CPU上执行计算,例如MPI技术,通常可分为数据并行和任务并行。
分布式计算(如HADOOP)
是相对单机计算而言的,利用多台机器,通过网络连接和消息传递协调完成计算。把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出最终结果。
<?>如何分发待处理数据?
在大规模集群环境下,如何解决大数据的划分、存储、访问管理
<?>如何处理分布式计算中的错误?
* 大数据并行计算系统使用,因此,节点出错或失效是常态,不能因为一个节点失效导致数据丢失、程序终止或系统崩溃。因此,系统需要有良好的可靠性设计和有效的失效检测和恢复计算。
* 设1万个服务器节点,每个服务器的平均无故障时间是1千天,则平均每天10个服务器出错!
<?>MapReduce是什么?
* 一种编程模型:不是一门语言,是一个模型
* 处理大数据集
* 部署于大规模计算机集群
* 分布式处理方式
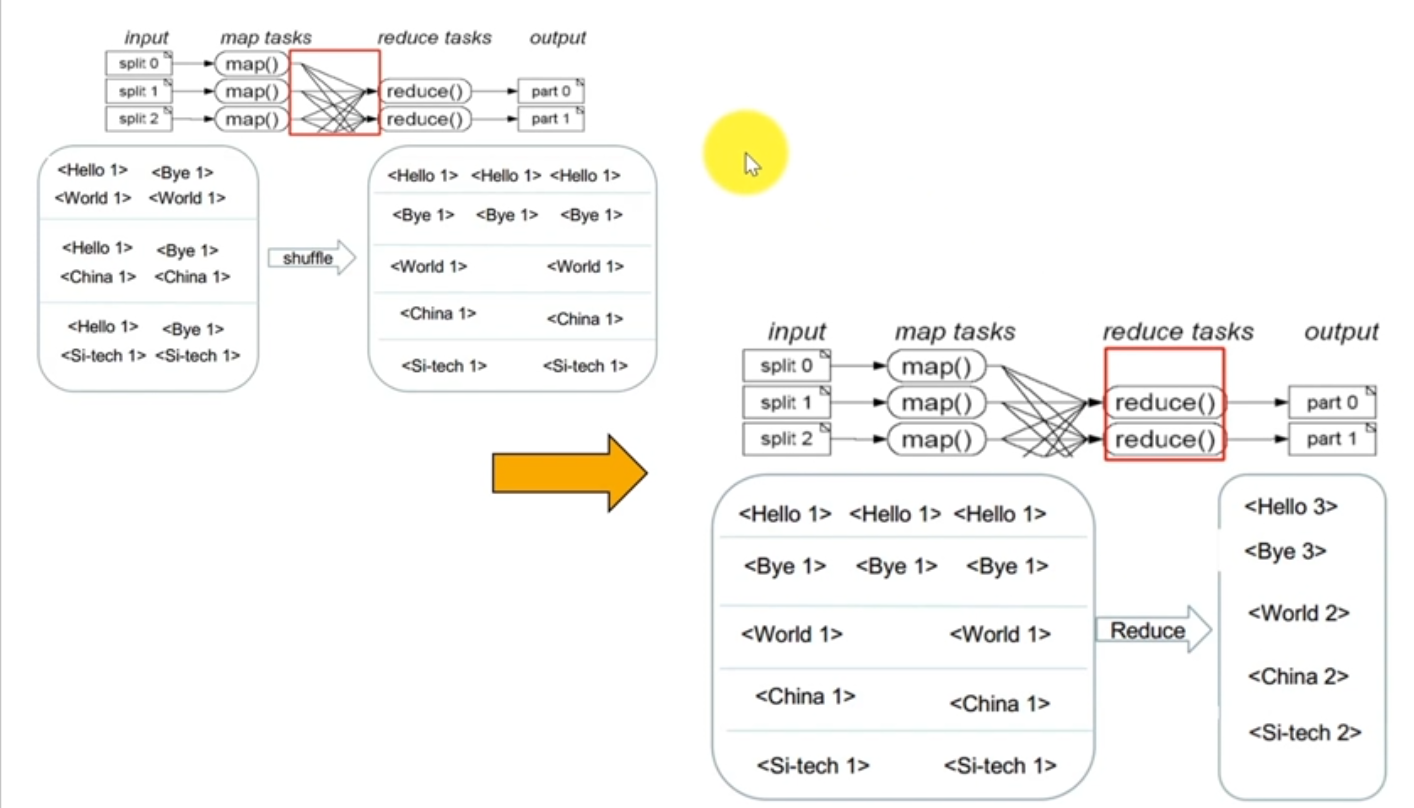
MapReduce核心代码:
输入数据:
hello word bye world
hello china bye china 经过mapreduce处理后 :hello:3,bye:3,word:2,china:2,chongqing:2
hello chongqing bye chongqing Map核心代码:
Map(Key,Value){
for(each word ‘word’ in value)
collect(‘word’,1);
} Reduce核心代码: Map(Key,Value[]){
int count=0;
for(each w in value)
count++;
collect(Key,count);
}
图解如下:

MapReduce的优势:
1、通过MapReduce这个分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如:自动并行化、负载均衡和灾备管理,这将极大地简化程序员的开发工作
2、MapReduce的伸缩性非常好,也就是:每增加一台服务器,就能将差不多的计算能力接入到集群中,而过去大部分分布式处理框架,在伸缩性方面都与MapReduce相差甚远
MapReduce的不足:
1、不适合事务/单一请求处理
MapReduce绝对是一个离线批处理系统,对于批处理数据应用的很好,MapReduce(不论是Google的还是Hadoop的)是用于处理不适合传统数据库的海量数据的理想技术,但它又不适合事务/单一请求。(Hbase使用了来自Hadoop核心的HDFS,在其常用操作中并没有使用MapReduce)
2、不能随即读取
3、以蛮力代替索引
在索引是更好的存取机制时,MapReduce将劣势尽显
4、low-level语言和操作
“直接开始你想要的 —— 而不是展现一个算法, 解释如何工作的。”(关系型数据库的观点) —— High level(DBMS) “展示数据存取的算法”(Codasyl 的观点)—— Low level (MapReduce)
5、性能问题
想想N 个map实例产生M个输出文件,每个最后由不同的reduce 实例处理,这些文件写到运行map实例机器的本地磁盘。如果N是1000,M是500,map阶段产生500,000个本地文件,当reduce阶段开始,500个reduce实例每个需要读入1000个文件,并用类似FTP协议把它要的输入文件从map实例运行的节点上pull取过来,假如同时有数量级为100的reduce实例运行,那么2个或者2个以上的reduce实例同时访问一个map阶段来获取输入文件是不可避免的——导致大量的硬盘查找,有效的硬盘运转速度至少降低20%。
6、仅提供了现在DBMS功能的一部分
作为用于分布式处理的算法技术,MapReduce不是数据库,不支持索引、数据更新、事务及完整性约束,且与多数DBMS工具不兼容。
7、不适合一般的web应用
大部分的web应用,只是对数据进行简单的访问,每次请求处理所耗费的资源其实非常小,它的问题是高并发,所以采用负载均衡技术来分担负载。只有当特殊情况下,比如建索引、进行数据分析等,才可能用MR.
【hadoop】MapReduce分布式计算框架原理的更多相关文章
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- [转载] Hadoop MapReduce
转载自http://blog.csdn.net/yfkiss/article/details/6387613和http://blog.csdn.net/yfkiss/article/details/6 ...
- python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍 59888745@qq.com 大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽), 把用户的交易 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架 1.1 MapReduce抽象模型 大数据计算的核心思想是:分而治之.如下图所示.把大量的数据划分开来,分配给各个子任务来完成.再将结果合并到一起输出.注: ...
- Hadoop- MapReduce分布式计算框架原理
分布式计算: 原则:移动计算而尽可能减少移动数据(减少网络开销) 分布式计算其实就是将单台机器上的计算拓展到多台机器上并行计算. MapReduce是一种编程模型.Hadoop MapReduce采用 ...
- [转] hadoop MapReduce实例解析-非常不错,讲解清晰
来源:http://blog.csdn.net/liuxiaochen123/article/details/8786715?utm_source=tuicool 2013-04-11 10:15 4 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!
Hadoop 涉及的知识点如下图所示,本文将逐一讲解: 本文档参考了关于 Hadoop 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图 ...
随机推荐
- Java基础 switch 简单示例
JDK :OpenJDK-11 OS :CentOS 7.6.1810 IDE :Eclipse 2019‑03 typesetting :Markdown code ...
- Linux_CentOS 内存、cpu、进程、端口、硬盘管理
内存.cup 管理 top 命令 top 1.top 命令的第一行: top - :: up :, users, load average: 0.00, 0.02, 0.05 依次对应:系统当前时间 ...
- spark streaming流式计算---监听器
随着对spark的了解,有时会觉得spark就像一个宝盒一样时不时会出现一些难以置信的新功能.每一个新功能被挖掘,就可以使开发过程变得更加便利一点.甚至使很多不可能完成或者完成起来比较复杂的操作,变成 ...
- ROS tf-增加坐标系
博客参考:https://www.ncnynl.com/archives/201702/1312.html ROS与C++入门教程-tf-增加坐标系 说明: 介绍如何为TF增加额外固定的坐标系 为何增 ...
- 警方破获超大DDoS黑产案,20万个僵尸网络运营商被抓
中国警方已镇压并逮捕了一个犯罪集团,该集团经营着一个由200,000多个受感染网站构成的僵尸网络,这些网站被用来发起DDoS攻击. 这是中国当局针对兴旺的本地DDoS租用场景进行的首次重大镇压,最大的 ...
- redis密码配置
配置密码 重启密码会失效 配置在redis.conf中 requirepass test123,则重启不会失效
- Tomcat启动原理/使用tomcat的应用是如何从tomcat的main函数开始运行的
从main方法开始打断点,逐步调试,了解程序运行过程 全局唯一的public static void main(String[] args)main Springboot* 内置tomcat,开发的时 ...
- python测试工具nosetests
今天在github上找东西,找到个工具是python写的,但是需要安装nosetests,因此了解了下nosetests python除了unittest,还有nosetests,使用更快捷 nose ...
- Python 内置函数--super()
描述 super() 函数是用于调用父类(超类)的一个方法. super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO).重复 ...
- 「中山纪中集训省选组D4T1」折射伤害 高斯消元
题目描述 在一个游戏中有n个英雄,初始时每个英雄受到数值为ai的伤害,每个英雄都有一个技能"折射",即减少自己受到的伤害,并将这部分伤害分摊给其他人.对于每个折射关系,我们用数对\ ...