Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码。


代码
package zhouls.bigdata.myMapReduce.Star; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* @function 统计分别统计出男女明星最大搜索指数
* @author 小讲
*/ /*
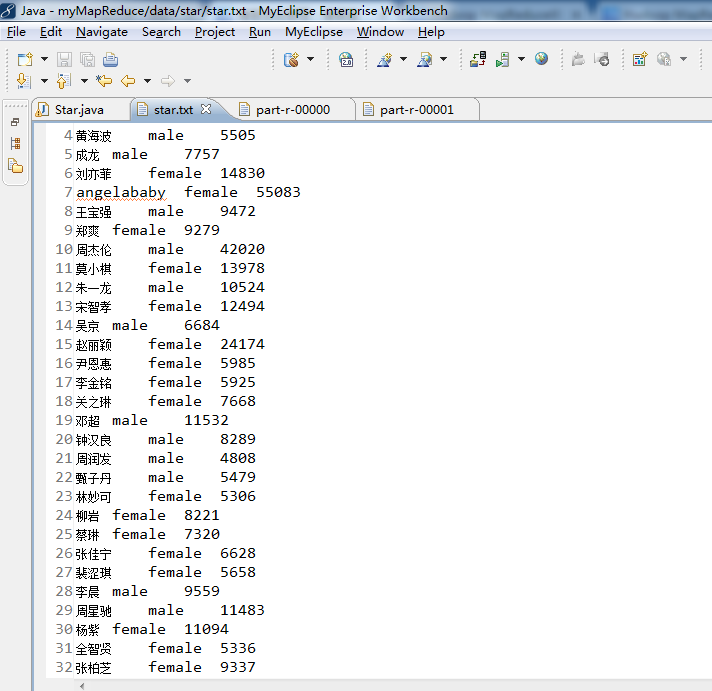
姓名 性别 搜索指数
李易峰 male 32670
朴信惠 female 13309
林心如 female 5242
黄海波 male 5505
成龙 male 7757
刘亦菲 female 14830
angelababy female 55083
王宝强 male 9472
郑爽 female 9279
周杰伦 male 42020
莫小棋 female 13978
朱一龙 male 10524
宋智孝 female 12494
吴京 male 6684
赵丽颖 female 24174
尹恩惠 female 5985
李金铭 female 5925
关之琳 female 7668
邓超 male 11532
钟汉良 male 8289
周润发 male 4808
甄子丹 male 5479
林妙可 female 5306
柳岩 female 8221
蔡琳 female 7320
张佳宁 female 6628
裴涩琪 female 5658
李晨 male 9559
周星驰 male 11483
杨紫 female 11094
全智贤 female 5336
张柏芝 female 9337
孙俪 female 7295
鲍蕾 female 5375
杨幂 female 20238
刘德华 male 19786
柯震东 male 6398
张国荣 male 5013
王阳 male 5169
李小龙 male 6859
林志颖 male 4512
林正英 male 5832
吴秀波 male 5668
陈伟霆 male 12817
陈奕迅 male 10472
赵又廷 male 5190
张馨予 female 35062
陈晓 male 17901
赵韩樱子 female 7077
乔振宇 male 8877
宋慧乔 female 5708
韩艺瑟 female 5426
张翰 male 7012
谢霆锋 male 6654
刘晓庆 female 5553
陈翔 male 7999
陈学冬 male 8829
秋瓷炫 female 6504
王祖蓝 male 6662
吴亦凡 male 16472
陈妍希 female 32590
倪妮 female 9278
高梓淇 male 7101
赵奕欢 female 7197
赵本山 male 12655
高圆圆 female 13688
陈赫 male 6820
鹿晗 male 32492
贾玲 female 5304
宋佳 female 6202
郭碧婷 female 5295
唐嫣 female 12055
杨蓉 female 10512
李钟硕 male 26278
郑秀晶 female 10479
熊黛林 female 26732
金秀贤 male 11370
古天乐 male 4954
黄晓明 male 10964
李敏镐 male 10512
王丽坤 female 5501
谢依霖 female 7000
陈冠希 male 9135
范冰冰 female 13734
姚笛 female 6953
彭于晏 male 14136
张学友 male 4578
谢娜 female 6886
胡歌 male 8015
古力娜扎 female 8858
黄渤 male 7825
周韦彤 female 7677
刘诗诗 female 16548
郭德纲 male 10307
郑恺 male 21145
赵薇 female 5339
李连杰 male 4621
宋茜 female 11164
任重 male 8383
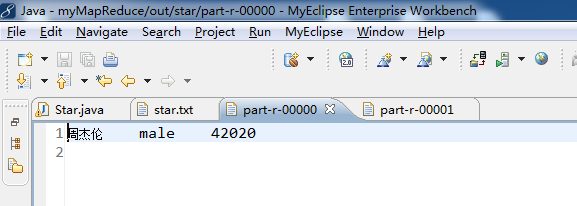
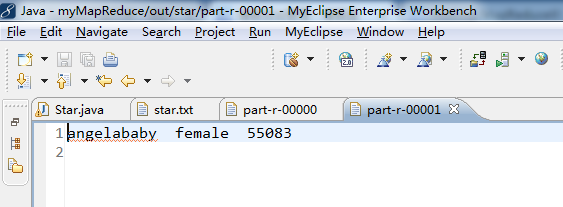
李若彤 female 9968 得到:
angelababy female 55083
周杰伦 male 42020
*/
public class Star extends Configured implements Tool{
/**
* @function Mapper 解析明星数据
* @input key=偏移量 value=明星数据
* @output key=gender value=name+hotIndex
*/
public static class ActorMapper extends Mapper<Object,Text,Text,Text>{
//在这个例子里,第一个参数Object是Hadoop根据默认值生成的,一般是文件块里的一行文字的行偏移数,这些偏移数不重要,在处理时候一般用不上
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
//拿:周杰伦 male 42020
//value=name+gender+hotIndex
String[] tokens = value.toString().split("\t");//使用分隔符\t,将数据解析为数组 tokens
String gender = tokens[1].trim();//性别,trim()是去除两边空格的方法
//tokens[0] tokens[1] tokens[2]
//周杰伦 male 42020
String nameHotIndex = tokens[0] + "\t" + tokens[2];//名称和关注指数
//输出key=gender value=name+hotIndex
context.write(new Text(gender), new Text(nameHotIndex));//写入gender是k2,nameHotIndex是v2
// context.write(gender,nameHotIndex);等价
//将gender和nameHotIndex写入到context中
}
} /**
* @function Partitioner 根据sex选择分区
*/
public static class ActorPartitioner extends Partitioner<Text, Text>{
@Override
public int getPartition(Text key, Text value, int numReduceTasks){
String sex = key.toString();//按性别分区 // 默认指定分区 0
if(numReduceTasks==0)
return 0; //性别为male 选择分区0
if(sex.equals("male"))
return 0;
//性别为female 选择分区1
if(sex.equals("female"))
return 1 % numReduceTasks;
//其他性别 选择分区2
else
return 2 % numReduceTasks; }
} /**
* @function 定义Combiner 合并 Mapper 输出结果
*/
public static class ActorCombiner extends Reducer<Text, Text, Text, Text>{
private Text text = new Text();
@Override
public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException{
int maxHotIndex = Integer.MIN_VALUE;
int hotIndex = 0;
String name="";
for (Text val : values){//星型for循环,即把values的值传给Text val
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[1]);
if(hotIndex>maxHotIndex){
name = valTokens[0];
maxHotIndex = hotIndex;
}
}
text.set(name+"\t"+maxHotIndex);
context.write(key, text);
}
} /**
* @function Reducer 统计男、女明星最高搜索指数
* @input key=gender value=name+hotIndex
* @output key=name value=gender+hotIndex(max)
*/
public static class ActorReducer extends Reducer<Text,Text,Text,Text>{
@Override
public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException{
int maxHotIndex = Integer.MIN_VALUE; String name = " ";
int hotIndex = 0;
// 根据key,迭代 values 集合,求出最高搜索指数
for (Text val : values){//星型for循环,即把values的值传给Text val
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[1]);
if (hotIndex > maxHotIndex){
name = valTokens[0];
maxHotIndex = hotIndex;
}
}
context.write(new Text(name), new Text(key + "\t"+ maxHotIndex));//写入name是k3,key + "\t"+ maxHotIndex是v3
// context.write(name,key + "\t"+ maxHotIndex);//等价
}
} /**
* @function 任务驱动方法
* @param args
* @return
* @throws Exception
*/ public int run(String[] args) throws Exception{
// TODO Auto-generated method stub Configuration conf = new Configuration();//读取配置文件,比如core-site.xml等等
Path mypath = new Path(args[1]);//Path对象mypath
FileSystem hdfs = mypath.getFileSystem(conf);//FileSystem对象hdfs
if (hdfs.isDirectory(mypath)){
hdfs.delete(mypath, true);
} Job job = new Job(conf, "star");//新建一个任务
job.setJarByClass(Star.class);//主类 job.setNumReduceTasks(2);//reduce的个数设置为2
job.setPartitionerClass(ActorPartitioner.class);//设置Partitioner类 job.setMapperClass(ActorMapper.class);//Mapper
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型 job.setCombinerClass(ActorCombiner.class);//设置Combiner类 job.setReducerClass(ActorReducer.class);//Reducer
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value类型 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.waitForCompletion(true);//提交任务
return 0;
} /**
* @function main 方法
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
// String[] args0 = { "hdfs://HadoopMaster:9000/star/star.txt",
// "hdfs://HadoopMaster:9000/out/star/" };
String[] args0 = { "./data/star/star.txt",
"./out/star" }; int ec = ToolRunner.run(new Configuration(), new Star(), args0);
System.exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之分区和合并(十四)的更多相关文章
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之网页流量版本1(二十一)
不多说,直接上代码. 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件. 代码 package zhouls.bigdata.myMapReduce.areapartition; i ...
- Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
不多说,直接上代码. 统计出每个年龄段的 男.女 学生的最高分 这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据. 代码 package zhouls.bigdata.myMapRedu ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
随机推荐
- c#同步锁Monitor.Enter(T)
protected static object MObjLock = new object();//同步锁 public string GetData(int mId) { Monitor.Enter ...
- html 复杂表格
123456789 123456789 0000000000 日期 123456789 1234560000000789 ----------- ----------- ----------- --- ...
- centos7 删除libc.so.6 紧急救援
wget http://ftp.gnu.org/gnu/glibc/glibc-2.18.tar.gz tar zxvf glibc-2.18.tar.gz cd glibc-2.18 mkdir b ...
- freemarker使用map替换字符串中的值
package demo01; import java.io.IOException;import java.io.OutputStreamWriter;import java.io.StringRe ...
- Python基础学习(day1)
一.Python几点使用规范: 1.关于引号的使用规范 (1)字符串中含有单引号,则使用双引号外扩 print("It's ok") (2)字符串中含有双引号,则使用单引号外扩 p ...
- 【剑指Offer】4、重建二叉树
题目描述: 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字.例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列 ...
- C#第十五节课
函数复习 using System;using System.Collections.Generic;using System.Linq;using System.Text;using System. ...
- 爬虫系列(十二) selenium的基本使用
一.selenium 简介 随着网络技术的发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载 对于爬取这些网站,一般有两种思路: 分析 Ajax 请 ...
- 使用Vue CLI 3将基于element-ui二次封装的组件发布到npm
前言:之前在网上找的好多都是基于vue-cli 2.x的,而使用vue-cli 3的文章比较少,Vue CLI 3 中文文档,所以我在自己尝试的时候把几篇文章结合了一下,调出来了我想要的模式,也就是V ...
- tornado服务器运行django应用
在jumpserver项目中看到的 def main(): from django.core.wsgi import get_wsgi_application import tornado.wsgi ...