PCA算法数学原理及实现
数学原理参考:https://blog.csdn.net/aiaiai010101/article/details/72744713
实现过程参考:https://www.cnblogs.com/eczhou/p/5435425.html
两篇博文都写的透彻明白。
自己用python实现了一下,有几点疑问,主要是因为对基变换和坐标变换理解不深。
先附上代码和实验结果:
code:
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat cx = mat([[2.5, 2.4],
[0.5, 0.7],
[2.2, 2.9],
[1.9, 2.2],
[3.1, 3.0],
[2.3, 2.7],
[, 1.6],
[, 1.1],
[1.5, 1.6],
[1.1, 0.9]])
# print(cx.shape)
sz = cx.shape
m = sz[]
n = sz[] # 显示原数据
def plot_oridata( cx ):
plt.figure(num='原数据图', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(cx[:, ].tolist(), cx[:, ].tolist(), c='r', marker='+')
plt.plot([, ], [-, ], 'k-')
plt.plot([-, ], [, ], 'k-')
plt.show()
return #求协方差矩阵
def get_covMat( cx ):
print('+++++++++++++ 求协方差矩阵 +++++++++++++++')
# 零均值化
ecol = np.mean(cx, axis=)
cx1 = (cx[:, ]) - ecol[, ]
cx2 = cx[:, ] - ecol[, ]
Mcx = np.column_stack((cx1, cx2))
Covx = np.transpose(Mcx)*Mcx/(m-)
# print(Covx)
return Covx, Mcx #计算特征值和特征向量
def get_eign(Covx, k):
eVals, eVecs = np.linalg.eig(Covx)
# print(eVals)
# print(eVecs, ' ', eVecs.shape)
sorted_indices = np.argsort(eVals)
topk_evecs = eVecs[:, sorted_indices[:-k-:-]]
# print(topk_evecs) plt.figure(num='特征向量', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , )
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(cx[:, ].tolist(), cx[:, ].tolist(), c='r', marker='+')
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.show()
return eVecs, topk_evecs #转换数据
def transform_data(eVecs, Mcx):
print("------------------转换数据---------------------")
tran_data = Mcx * eVecs
plt.figure(num='转换数据', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(tran_data[:, ].tolist(), tran_data[:, ].tolist(), c='r', marker='+')#哪一维对应x,哪一维对应y
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.show()
return #压缩数据
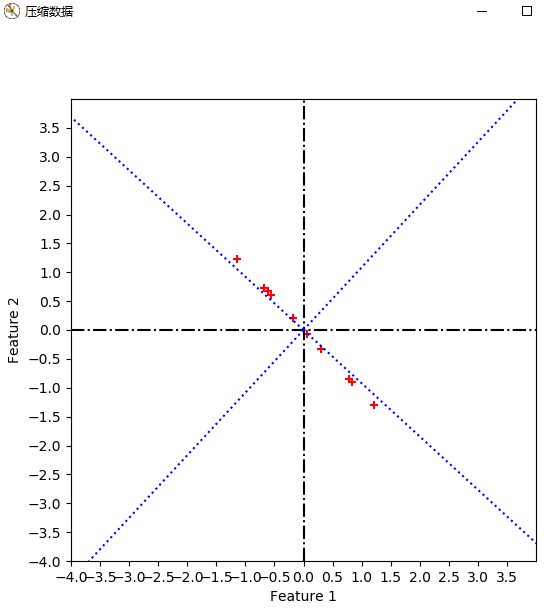
def compress_data(Mcx, topkevecs, eVecs):
print("------------------压缩数据---------------------")
comdata = Mcx * topkevecs
c1 = np.zeros((, ), dtype=int)
comdata1 = np.column_stack((c1, comdata))
comdata2 = comdata1 * eVecs plt.figure(num='压缩数据', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(comdata2[:, ].tolist(), comdata2[:, ].tolist(), c='r', marker='+') # 哪一维对应x,哪一维对应y
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.show()
return plot_oridata(cx)
Covx, Mcx = get_covMat(cx)
eVecs, topk_evecs = get_eign(Covx, )
transform_data(eVecs, Mcx)
compress_data(Mcx, topk_evecs, eVecs)
print('end')
初学python,代码肯定很啰嗦,并且很丑。
实验结果:
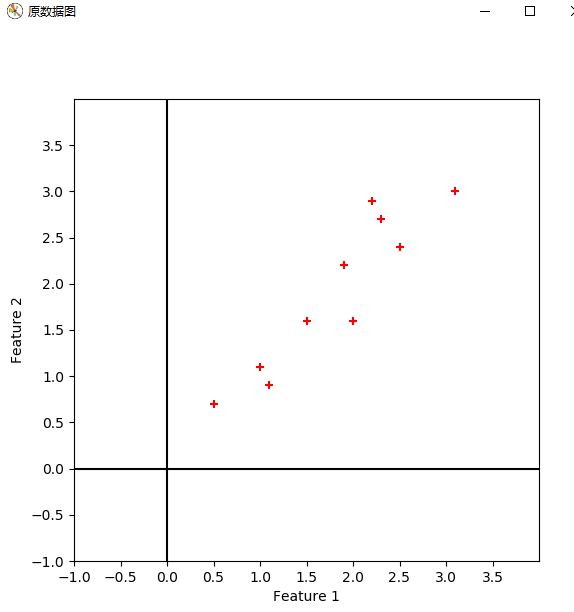
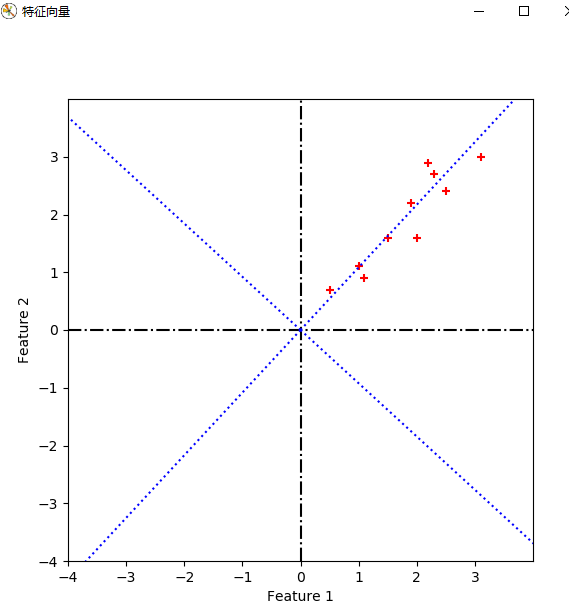
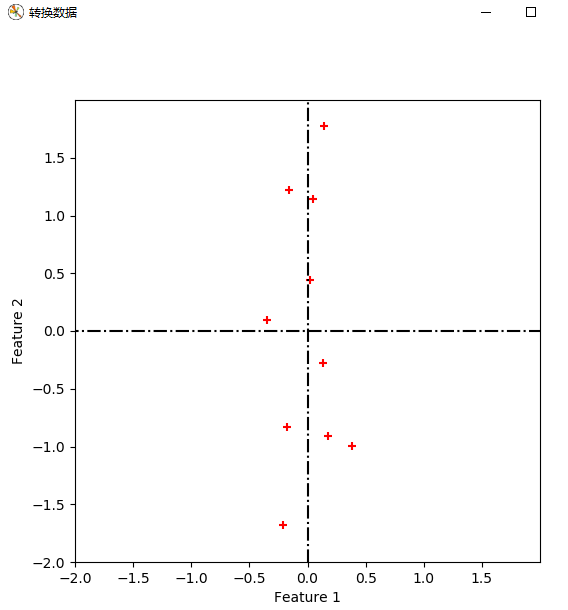
疑问1:对数据进行特征向量为基的转换时,公式如下。我得到的坐标是以原坐标系为参考的,那么哪一维对应x,哪一维对应y,如果我将特征向量按照特征值降序的顺序重新排列,是否有影响呢?
得到的坐标是新坐标系下的。根据转换向量对应。

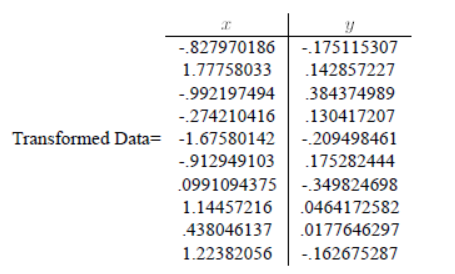
疑问2:取最大特征值对应的特征向量为基时,对数据进行降维,此时我得到的一维坐标是以这个特征向量为参考的吗?此时我应该如何在原坐标系show出这些数据?
我的代码中,取第一维为0,第二维为得到的坐标,以此再进行以此疑问1中的二维基转换,得到坐标,并且plot。不太理解道理。
对一维坐标,分别对两个坐标轴投影即可得到新坐标系下的两个坐标。
PCA算法数学原理及实现的更多相关文章
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- 【机器学习笔记之七】PCA 的数学原理和可视化效果
PCA 的数学原理和可视化效果 本文结构: 什么是 PCA 数学原理 可视化效果 1. 什么是 PCA PCA (principal component analysis, 主成分分析) 是机器学习中 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 非对称加密技术- RSA算法数学原理分析
非对称加密技术,在现在网络中,有非常广泛应用.加密技术更是数字货币的基础. 所谓非对称,就是指该算法需要一对密钥,使用其中一个(公钥)加密,则需要用另一个(私钥)才能解密. 但是对于其原理大部分同学应 ...
- PCA的数学原理Matlab演示
关于 PCA(Principal component analysis)主成分分析.是SVD(Singular value decomposition)神秘值分析的一种特殊情况.主要用于数据降维.特征 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- pca数学原理(转)
PCA的数学原理 前言 数据的向量表示及降维问题 向量的表示及基变换 内积与投影 基 基变换的矩阵表示 协方差矩阵及优化目标 方差 协方差 协方差矩阵 协方差矩阵对角化 算法及实例 PCA算法 实例 ...
- python实现PCA算法原理
PCA主成分分析法的数据主成分分析过程及python原理实现 1.对于主成分分析法,在求得第一主成分之后,如果需要求取下一个主成分,则需要将原来数据把第一主成分去掉以后再求取新的数据X’的第一主成分, ...
随机推荐
- Python爬虫与一汽项目【综述】
项目来源 这个爬虫项目是 去年实验室去一汽后的第一个项目(基本交工,现在处于更新维护阶段).内容大概是,获取到全国31个省份政府的关于汽车的招标公告,再用图形界面的方式展示爬虫内容.在完成政府招标采购 ...
- 移动端js调试工具:eruda
通常写前端页面都在Chrome浏览器的开发模式下进行调试,但是写放在移动端的H5页面时,有时候会遇到在Chrome上调试没有问题,但是在手机的浏览器上有问题的情况:或者有些功能只能在特定的容器中才能其 ...
- Py 最全的常用正则表达式大全 ZZ
很多不太懂正则的朋友,在遇到需要用正则校验数据时,往往是在网上去找很久,结果找来的还是不很符合要求.所以我最近把开发中常用的一些正则表达式整理了一下,在这里分享一下.给自己留个底,也给朋友们做个参考. ...
- 结巴库及词频统计bb
下面是利用云图和结巴库完成词频统计.代码如下: # -*- coding:utf- -*- from wordcloud import WordCloud import matplotlib.pypl ...
- Oracle中的位图索引和函数索引
位图索引 同样的,先说是什么,再说为什么. 上篇我们说过BTREE索引是将数据表的索引列和行号排序后以树状形式存在磁盘中.那位图索引是什么样的呢? 现有如下日志表,有操作类型字段op_type,该字段 ...
- gitlab 存储仓库目录设置及数据迁移
注:一开始没有考虑到把gitlab划分好存储目录,占用系统磁盘,由于gitlab是默认安装的,随着公司代码越来越多,导致gitlab数据目录空间不足 磁盘空间: [root@gitlab ~]# df ...
- CF666E Forensic Examination
思路 线段树合并+广义SAM 先把所有串都插入SAM中,然后用线段树合并维护right集合,对S匹配的同时离线询问,然后就好啦 代码 #include <cstdio> #include ...
- 容器中的诊断与分析4——live diagnosis——LTTng
官网地址 LTTng 简介&使用实战 使用LTTng链接内核和用户空间应用程序追踪 简介: LTTng: (Linux Trace Toolkit Next Generation),它是用于跟 ...
- @resource、@Autowired、@Service在一个接口多个实现类中的应用
Spring在没有引入注解之前,传统的Spring做法是使用.xml文件来对bean进行注入,所有的内容都需要配置在.xml文件中,使配置和编程分离,却增加了可读性和复杂度. Spring注解将复杂的 ...
- hibernate 一对多关系中的孤儿属性
@OneToMany(targetEntity = BenefitType.class, mappedBy = "sitePerson",cascade = CascadeType ...