[01-01] 示例:用Java爬取新闻
1、分析url
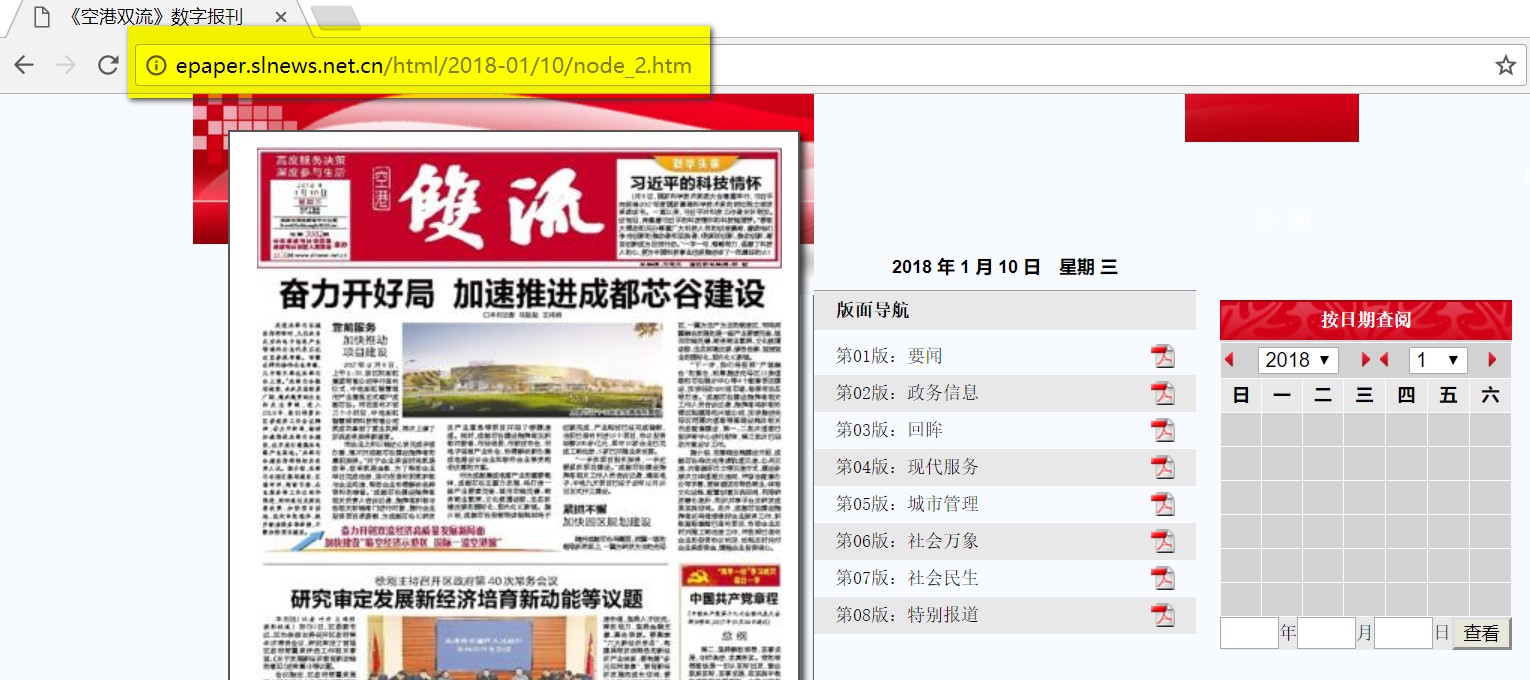
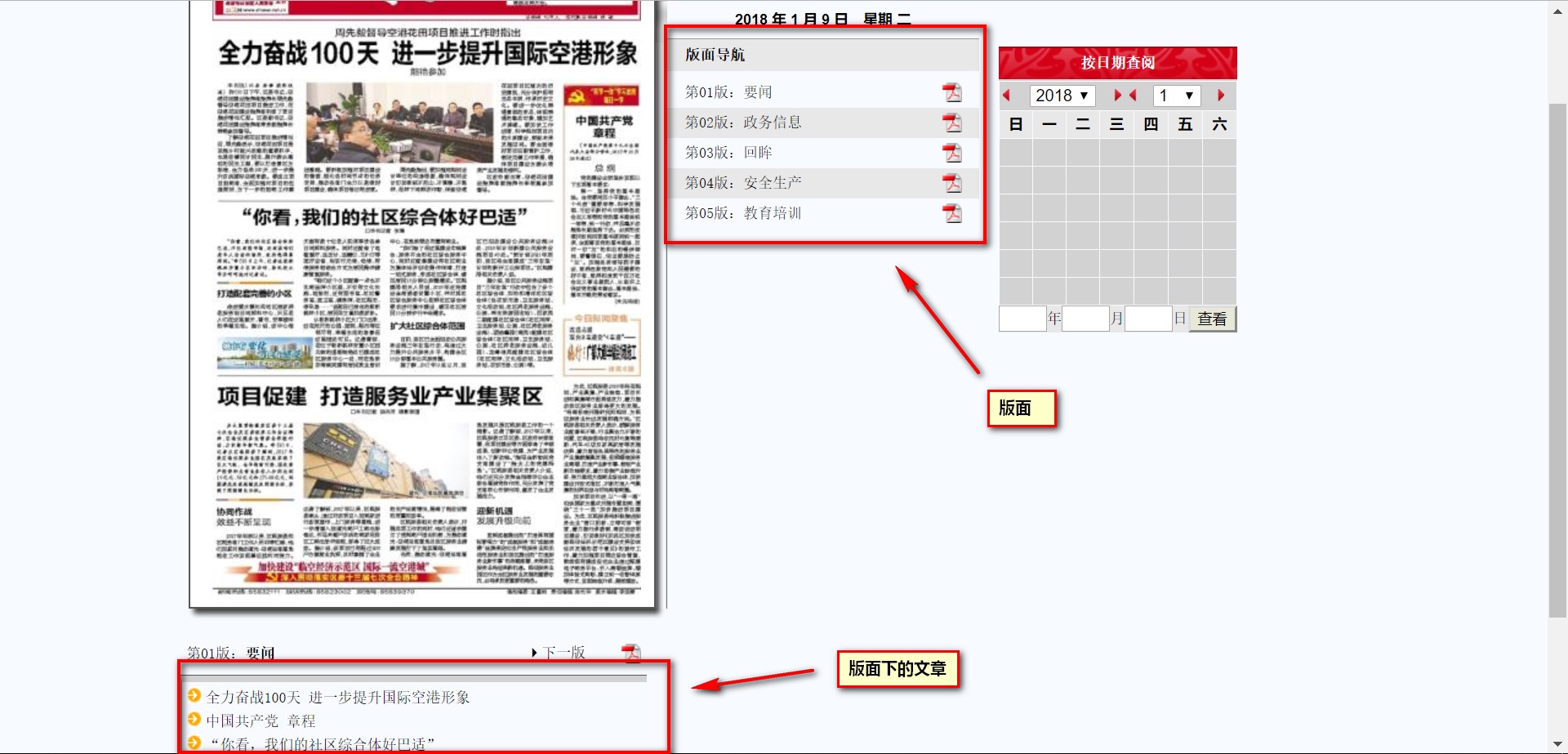
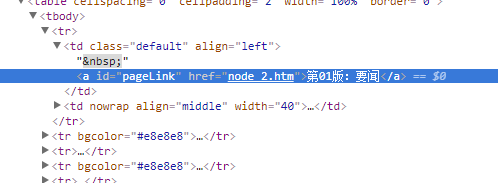

- 先得到所有版面的url
- 访问版面网页并抓取其中的所有文章的url
- 最后访问文章url就可以得到新闻网页内容了
2、代码部分
public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}
/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}
/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}
/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}
/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}
[01-01] 示例:用Java爬取新闻的更多相关文章
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
随机推荐
- Python 利用字典实现类似 java switch case 功能
def add(): print('add') def sub(): print('sub') def exit(): print('exit') choice = { '1' : add, '2' ...
- Linux 系统性能分析工具 sar
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以 从多方面对系统的活动进行报告,包括:文件的读写情况.系统调用的使用 ...
- JSONArray.toJSONString json乱码
前提:配置文件已经配置了: <mvc:annotation-driven> <!-- 处理请求返回json字符串的中文乱码问题 --> <mvc:message-conv ...
- 安卓开发_计时器(Chronometer)的简单使用
计时器控件(Chronometer)是一个可以显示从某个起始时间开始一共过去多长时间的本文. 继承自TextView,以文本的形式显示时间内容 该组件有五个方法 1.setBase(): \\用于设置 ...
- Login case
第一步:画UI,代码如下: <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" ...
- springcloud 入门 10 (eureka高可用)
eureka高可用: 说白了,就是加一个实例作为原实例的备份,然后一起对外提供服务.这样可以保证在一台机器宕机的时候,整个系统不会死掉.保证其继续对外服务. eureka的集群化: 服务注册中心Eur ...
- [20171115]ZEROCONF ROUTE.txt
[20171115]ZEROCONF ROUTE.txt --//如果你检查linux服务器的网络配置,就可以发现如下一条路由: # route -n | egrep "169.254|D ...
- C#语言————第四章 常用Convert类的类型转换方法
方法 说明Convert.ToInt32() 转换为整型(int 型)Convert.ToStringle() 转换为单精度浮点型(float 型)Convert.ToDouble() 转换为双精度 ...
- Business talking in English
Talking one: A: Microsoft, this is Steve. B: Hi Steve, this is Richard from Third Hand Testing. I am ...
- pyenv离线安装python各版本
1.问题描述: 可能是国内的网络原因,在线用pyenv安装python老是定住没反应 [root@zabbix ~]# pyenv install Downloading Python-.tar.xz ...