kNN分类算法实例1:用kNN改进约会网站的配对效果
@
实战内容
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
不喜欢的人
魅力一般的人
极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
每年获得的飞行常客里程数
玩视频游戏所消耗时间百分比
每周消费的冰淇淋公升数
任务:试建立一个分类器,使得在下次输入数据后,程序可以帮助海伦预测海伦对此人的印象。
原著中,所有归一化、kNN算法,分类器都是作者自己写的。代码可以用于理解算法原理,用于使用就没有必要,而且代码基于的版本是2.7,难以直接使用。
源代码及其详解可以参考以下链接:
机器学习实战—k近邻算法(kNN)02-改进约会网站的配对效果
既然有了优秀的sklearn库可以为我们提供现成的kNN函数,为什么不直接调用它呢?这正是python较其他语言强大的所在呀!
用sklearn自带库实现kNN算法分类
大致流程:
- 导入数据,打印数据的相关信息,初步了解数据
- 绘制图像更直观的分析数据
- 切分数据成测试集和训练集,可以用sklearn自带库随机切割,也可以将数据前半部分和后半部分切割,后者更有利于代入测试集人工检验
- 数据预处理,之后的代码仅有归一化
- 用sklearn自带库训练算法,然后打分正确率
- 完善分类器功能,允许后期输入参数真正实现分类
可以参考以下链接,更详细的了解sklearn自带的kNN算法做分类的流程:
用sklearn实现knn算法的实现流程
以下是代码(更多细节请参考附在最后的参考资料):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#转化文件格式 第一次执行后,在文件夹下会生成.csv文件,之后就不需要重复执行这段代码了
'''
txt = np.loadtxt('datingTestSet2.txt')
txtDf = pd.DataFrame(txt)
txtDf.to_csv('datingTestSet2.csv', index=False) #no index
'''
#load csv, learn more about it.
dataset = pd.read_csv('datingTestSet2.csv')
dataset.columns = ['miles', 'galons', 'percentage', 'label']
print(dataset.head())
print(dataset.dtypes)
print(np.unique(dataset['label']))
print(len(dataset))
#analyze our set through seaborn
# 绘制散点图 第一次执行后,三个特征对结果的影响就会有个印象,后面也可以不再执行
'''
sns.lmplot(x='galons', y='percentage', data=dataset, hue='label',fit_reg=False)
sns.lmplot(x='miles', y='percentage', data=dataset, hue='label',fit_reg=False)
sns.lmplot(x='miles', y='galons', data=dataset, hue='label',fit_reg=False)
plt.show()
'''
#cut dataset randomly
'''
dataset_data = dataset[['miles', 'galons', 'percentage']]
dataset_label = dataset['label']
print(dataset_data.head())
data_train, data_test, label_train, label_test = train_test_split(dataset_data, dataset_label, test_size=0.2, random_state=0)
'''
#cut dataset
dataset_data = dataset[['miles', 'galons', 'percentage']]
dataset_label = dataset['label']
data_train = dataset.loc[:800,['miles', 'galons', 'percentage']] #我让训练集取前800个
print(data_train.head())
label_train = np.ravel(dataset.loc[:800,['label']])
data_test = dataset.loc[800:,['miles', 'galons', 'percentage']]
label_test = np.ravel(dataset.loc[800:,['label']])
#preprocessing, minmaxscaler
min_max_scaler = preprocessing.MinMaxScaler()
data_train_minmax = min_max_scaler.fit_transform(data_train)
data_test_minmax = min_max_scaler.fit_transform(data_test)
print(data_train_minmax)
#training and scoring
knn = KNeighborsClassifier(n_neighbors=15)
knn.fit(data_train_minmax,label_train)
score = knn.score(X=data_test_minmax,y=label_test,sample_weight=None)
print(score)
#completion
def classifyperson(): #此为手动输入参数预测结果需要的函数
percentage = float(input('percentage of time spent playing video games?'))
ffMiles = float(input('frequent flier miles earned per year?'))
iceCream = float(input('liters of ice-cream consumed per year?'))
inArr = np.array([[percentage, ffMiles, iceCream]])
inArr_minmax = min_max_scaler.fit_transform(inArr)
return inArr_minmax
#inArr_minmax = classifyperson()
label_predict = knn.predict(data_test_minmax) #此代码与之前人工切分数据集结合,用于人工校对正确率
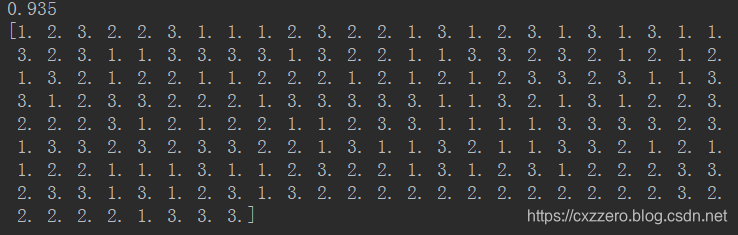
print(label_predict)
当k取15的时候,正确率试过来是最高的,能达到0.935
以下是测试集代入分类器后得到的结果,可以将其与文本文件里最后200个标签一一对照一下,可以发现正确率确实还是蛮高的。
将内含非数值型的txt文件转化为csv文件
原作中,作者已经将obj型标签帮我们转化成数值型了,因此在上面的代码中,我们可以直接将转化好的文件拿来用。但是如果要我们自己转化数据类型,该怎么转化?
其实只需要将原作中的第一个函数略加改造即可。代码如下:
# 将文本记录转换为NumPy的解析程序
def file2matrix(filename):
fr = open(filename)
#得到文件行数
arrayOfLines = fr.readlines()
numberOfLines = len(arrayOfLines)
#创建返回的Numpy矩阵
returnMat = np.zeros((numberOfLines,3))
classLabelVector = []
#解析文件数据到列表
index = 0
for line in arrayOfLines:
line = line.strip() #注释1
listFromLine = line.split('\t') #注释2
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(listFromLine[-1])
index += 1
return returnMat,classLabelVector
#调用函数,读取数据
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
#拼接标签和特征
datingDataMat_df = pd.DataFrame(datingDataMat)
datingLabels_df = pd.DataFrame(datingLabels)
txtDf = pd.concat([datingDataMat_df,datingLabels_df],axis=1) #横向拼接
txtDf.to_csv('datingTestSet.csv', index=False) #这里,datingTestSet.csv中的标签是[largedoses, smalldoses, didn't like]
#读取datingTestSet.csv
dataset = pd.read_csv('datingTestSet.csv')
dataset.columns = ['miles', 'galons', 'percentage', 'label']
print(dataset.head())
得到的新DataFrame如下:
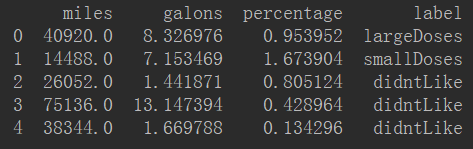
用sns.lmplot绘图反映几个特征之间的关系
以下列出了三个特征两两之间的关系(没有列全),通过它们大致能感觉出三个特征值对结果的影响。
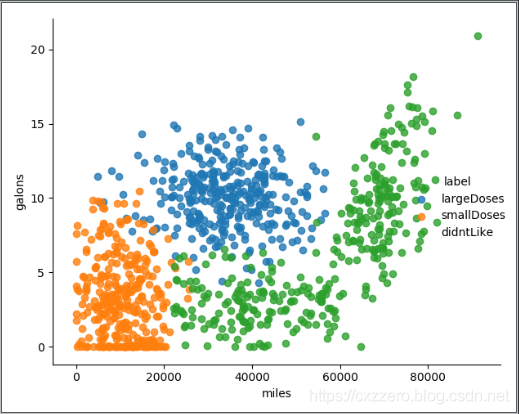
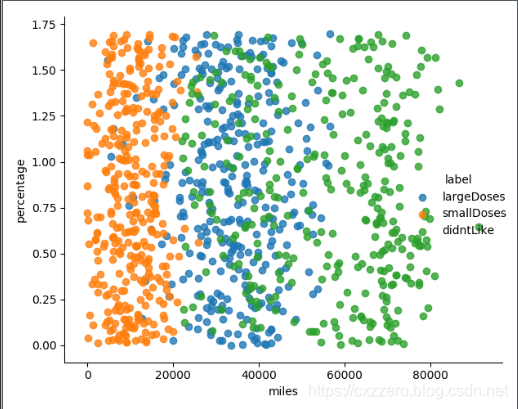
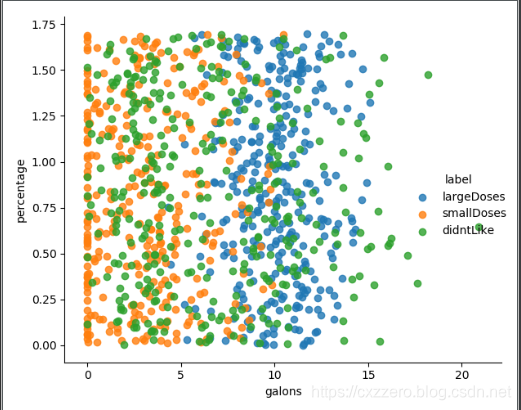
参考资料
如何把txt文件转化为csv格式? (此办法只适用于只有数值型的文件,或者说标签已经被转化为数值型了,如何将含object型的txt文件导入见后)
如何对DataFrame的列名重新命名?
pycharm如何用run执行不用console执行?
如何绘制散点图?
如何改变DataFrame某一列的数据类型?
如何使用seaborn中的jointplot?
查看某一列有那些值?
jointplot没有hue参数,有什么其他函数可以代替吗?
如何绘制子图?
如何获取Dataframe的行数和列数?
如何选取DataFrame列?官网
如何切分数据集?官网
如何用sklearn的train_test_split随机切分数据集?
如何用sklearn自带库归一化?官网
归一化、标准化、正则化介绍及实例
如何使用sklearn中的knn算法?
用sklearn实现knn算法的实现流程
洗牌函数shuffle()和permutation()的区别是什么?
如何使用with open()as filename?
如何用Python提取TXT数据转化为DataFrame?
pandas dataframe的合并(append, merge, concat)
kNN分类算法实例1:用kNN改进约会网站的配对效果的更多相关文章
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:<机器学习实战>,用python编写的(需要matplotlib和numpy库) 海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的 ...
- 《机器学习实战》之k-近邻算法(改进约会网站的配对效果)
示例背景: 我的朋友海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现曾交往过三种类型的人: (1)不喜欢的人: (2)魅力一般 ...
- 机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一.背景 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可以进行如下分类 不喜欢的人 魅力一般的人 极具魅 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 机器学习——kNN(2)示例:改进约会网站的配对效果
=================================版权声明================================= 版权声明:原创文章 禁止转载 请通过右侧公告中的“联系邮 ...
- 使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数 import numpy as np """ 函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Par ...
随机推荐
- iphone使用linux命令apt-get也没有问题
那么教程开始: 首先安装cydia这个越了yu就有自带的哦 然后添加源,比如apt.91.我忘了,大家可以在http://frank-dev-blog.club/?post=45找一个 查找termi ...
- oracle 用户系统权限
conn sys as sysdba; create user test identified by test; grant create session to test; grant create ...
- node(2)
//app.js var express = require("express"); //以后的时后处理POST DELETE PATCH CHECKOUT 这些请求都可以用for ...
- CSS 小结笔记之选择器
Css选择器主要分为以下几类 类选择器 ID选择器 通配符选择器 标签选择器 伪类选择器 复合选择器 1.类选择器:通过.classname 来选择 例如 .color2 { color: rebec ...
- 聊一聊数组的map、reduce、foreach等方法
聊聊数组遍历方法 JS 数组的遍历方法有好几个: every some filter foreach map reduce 接下来我们来一个个地交流下. every() arr.every(callb ...
- Entity Framework对同一张表配置一对多关系
在实际的项目开发中,可能会遇到同一张表同时保存自身和上级(或下级)的信息(一般是通过设置一个上级主键[ParentId]的列与主键[Id]关系) 例如:城市库,有国家.省.市...,省的ParentI ...
- 配置consul为windows服务
安装consul并配置为系统服务下载地址https://www.consul.io/downloads.html 配置系统服务1.拷贝consul.exe的目录 如:E:\Consul\consule ...
- AC自动机, 字符串匹配算法
package utils import java.util.HashMapimport java.util.LinkedListimport util.control.Breaks._import ...
- (1)Set集合 (2)Map集合 (3)异常机制
1.Set集合(重点)1.1 基本概念 java.util.Set接口是Collection接口的子接口,与List接口平级. 该接口中的元素没有先后放入次序,并且不允许重复. 该接口的主要实现类:H ...
- Element对象 常用属性与常用方法
常用属性 .children 子元素列表 .childElementCount 子元素数量 .firstElementChild 第一个子元素 .lastElementChild 最后一个子元素 .c ...