sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串
1简述问题
使用countVectorizer()将文本向量化时发现,文本中长度唯一的字符串会被自动过滤掉,这对于我在做的情感分析来讲,一些表较重要的表达情感倾向的词汇被过滤掉,比如文本'没用的东西,可把我可把我坑的不轻,越用越觉得这个手机真的废'。
用结巴分词的精确模式分词,然后我用空格连接这些分词得到的句子是:
'没用 的 东西 , 可 把 我 可 把 我 坑 的 不轻 , 越用 越 觉得 这个 手机 真的 废'
代码如下:
def cut_word(sent):
line=re.sub(r'[a-zA-Z0-9]*','',sent)
wordList=jieba.lcut(line)
#print(wordList)
return ' '.join(wordList) vec= CountVectorizer(min_df=1)
c='没用的东西,可把我可把我坑的不轻,越用越觉得这个手机真的废'
cut=cut_word(c)
然后用countVectorizer()对这个分好词的句子进行向量化发现,一个字的词都被过滤掉了:
['不轻', '东西', '手机', '没用', '真的','越用']
代码如下:
vec.fit_transform([cut])
vec.get_feature_names()
他把最能表达情感倾向的词“坑”,‘废’给过滤掉了,这对于向量化后的句子特征就损失了很多的信息。我认为因为这个库的函数原本就是为了英文分词的,而英文长度为1 的词是26个字母,并不会表示什么重要含义,所以在编写这个函数时自动就给这些长度低于2的单词给去掉了。但是中文可不一样,一个字的意义可以有非常重要的含义。对于我们分类不重要的词,比如一些代词“你”,‘我’,‘他’等其他经常出现的词,可以用停用词表给过滤掉,这个countVectorizer()就自带了一个组停用词的参数,stop_words,这个停用词是个列表包含了要去掉的停用词,我们可以针对自己需要自定义一个停用词表。当stop_words=‘english’时,函数会自动为英文文本分词去除停用词。中文都是自己自定义。
2解决方法
我是找了源代码,这个函数在sklearn包的feature_exceration文件夹中text.py。
找到了打开文件,找到了CountVectorizer()的代码,定位到fit_transform(raw_documents)中关于词汇表对于原始文本进行处理的地方

看见vocabulary这是包含所有分词的字典,再定位到_cout_vocab()函数位置,

看见raw_vocabulary了,796行是对特征(分词)进行计数的放到字典feature_counter中。doc是原始文本的每行文本,这利用analyze()处理,再往回找
analyze = self.build_analyzer(),可再往上找self.build_analyzer()函数,
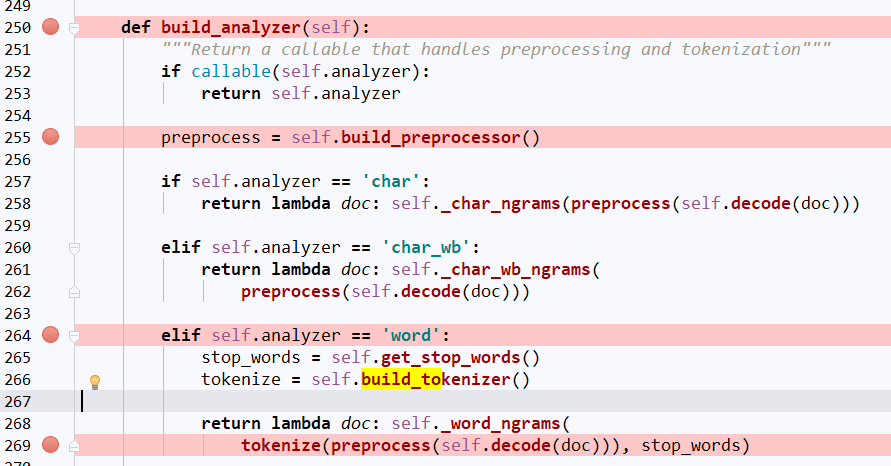
我们主要找的是对文本进行处理的函数,所以找的就是出现文本,且对文本进行操作的函数。定位到264行,根据countVectorizer()的初始定义self.analyzer的默认值是‘word’,所以
self.build_analyzer()函数默认情况下是跳到这里对文本dco进行操作。再看看preprocess()和tokenize()

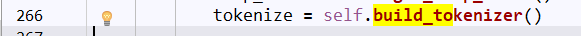
找到self.build_preprocessor()看一下知道是对文本的编码格式以及大小写的操作,对文本预处理的函数。
重点到self.bulid_tokenizer(),看名字就是知道是分词函数了。

这是我该过的,#原句是 return lambda doc: token_pattern.findall(doc),是根据正则表达式token_patten来从文本doc中找到符合正则表达式的所有分词,可见问题出在这里,再回到原文本countVectorizer()定义的正则表达式。

#原句token_patten=u'(?u)\b\w\w+\b',水平太菜不太看懂这个表达式,反正试了一下,这个表达式真的会过滤掉字符长度为1的字符串,我就改了一下正则表达式。因为待分的文本都是分词好且用空格连起来的字符串,所以用郑子表达式空格作为切分文本的标记。
所以总的来说就是改了两个点
(1)CountVectorizer中将默认的正则表达式u'(?u)\b\w\w+\b'改为r"\s+:即token_pattern=r"\s+"
(2)self.build_tokenizer()中fiandall()替换成split(),即return lambda doc: token_pattern.split(doc)
3.测试
结合自己定义的停词表,去掉没用的词,再试一下分词效果:
原来分词效果:
['不轻', '东西', '手机', '没用', '真的','越用']
更改过后效果:
['不轻', '东西', '坑', '废', '手机', '没用', '真的', '越', '越用']
可见,长度为1的重要情感词,'坑', '废',得到了保留。
sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串的更多相关文章
- 转载 --- SKLearn中预测准确率函数介绍
混淆矩阵 confusion_matrix 下面将一一给出'tp','fp','fn'的具体含义: 准确率: 所有识别为"1"的数据中,正确的比率是多少. 如识别出来100个结果是 ...
- sklearn中的cross_val_score()函数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verb ...
- sklearn中LinearRegression使用及源码解读
sklearn中的LinearRegression 函数原型:class sklearn.linear_model.LinearRegression(fit_intercept=True,normal ...
- sklearn中调用PCA算法
sklearn中调用PCA算法 PCA算法是一种数据降维的方法,它可以对于数据进行维度降低,实现提高数据计算和训练的效率,而不丢失数据的重要信息,其sklearn中调用PCA算法的具体操作和代码如下所 ...
- PYTHON练习题 二. 使用random中的randint函数随机生成一个1~100之间的预设整数让用户键盘输入所猜的数。
Python 练习 标签: Python Python练习题 Python知识点 二. 使用random中的randint函数随机生成一个1~100之间的预设整数让用户键盘输入所猜的数,如果大于预设的 ...
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作.在介绍向量化之前,我们先来了解下词袋模型. 1.词袋模型(Bag of words,简称 BoW ) 词袋模型假设我们不考虑文本中词与词 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑
在SKLearn中,StratifiedShuffleSplit 类实现了对数据集进行洗牌.分割的功能.但在今晚的实际使用中,发现该类及其方法split()仅能够对二分类样本有效. 一个简单的例子如下 ...
- Jquery中的队列函数quene()、dequene()、clearQuene()
jQuery中的queue和dequeue是一组很有用的方法,他们对于一系列需要按次序运行的函数特别有用.特别animate动画,ajax,以及timeout等需要一定时间的函数.Queue()和de ...
随机推荐
- maven错误
maven-enforcer-plugin (goal "enforce") is ignored by m2e. Plugin execution not covered by ...
- 前端-javascript-ECMAScript5.0
-前端常用开发工具:sublime.visual Studio Code.HBuilder.Webstorm. 使用的PCharm跟WebStorm是JetBrains公司推出的编辑工具,开发阶段建议 ...
- vue - iview UI组件的col标签报错 x-invalid-end-tag
https://blog.csdn.net/xiao199306/article/details/80430087
- redis数据迁移
redis的备份和还原,借助了第三方的工具---redis-dump, redis中使用redis-dump导出.导入.还原数据实例 1.安装redis-dump # yum install rub ...
- Redis need tcl 8.5 or newer
hadoop@stormspark:~/workspace/redis2.6.13/src$ make testYou need tcl 8.5 or newer in order to run th ...
- JPEG和Variant的转换
unit Unit1; interface uses Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, ...
- Mysql生成索引的方式
1.选择索引的数据类型 MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响.通常来说,可以遵循以下一些指导原则: (1)越小的数据类型通常更好:越小的数据类型通常在磁盘.内存和C ...
- RNN LSTM 介绍
[RNN以及LSTM的介绍和公式梳理]http://blog.csdn.net/Dark_Scope/article/details/47056361 [知乎 对比 rnn lstm 简单代码] ...
- php获取微信用户信息(没测试过)
<?php /** * 通过$appid.$appsecret获得基础支持的接口唯一凭证access_token,返回值为array类型 */ function get_access_token ...
- python没有switch,可以用字典来替代
python没有switch,是因为可以用字典来替代,具体方法如下: def add(x,y): print(x+y)def subtraction(x,y): print(x-y)def multi ...