推荐算法-聚类-K-MEANS
对于大型的推荐系统,直接上协同过滤或者矩阵分解的话可能存在计算复杂度过高的问题,这个时候可以考虑用聚类做处理,其实聚类本身在机器学习中也常用,属于是非监督学习的应用,我们有的只是一组组数据,最终我们要把它们分组,但是前期没有任何的先验知识告诉我们那个点是属于那个组的。
当我们有足够的数据的时候可以考虑先用聚类做第一步处理,来缩减协同过滤的选择范围,从而降低复杂度。
对了还想起来机器学习里面也经常用聚类的方式进行降维。这个在机器学习笔记部分后期我会整理。
最终,每个聚类中的用户,都会收到为这个聚类计算出的推荐内容。聚类的话也有很多种方法时间,今天是整理最简单的那个姿势:K-MEANS
K-MEANS聚类算法是非常常用的聚类算法。它出现在很多介绍性的数据科学和机器学习课程中。在代码中很容易理解和实现!
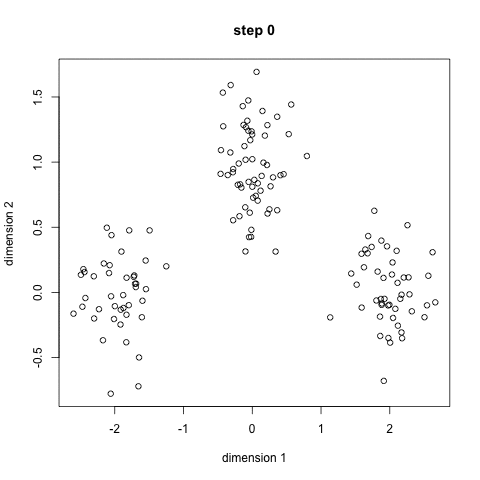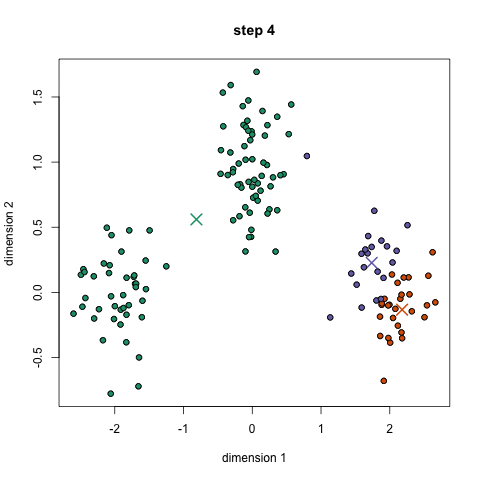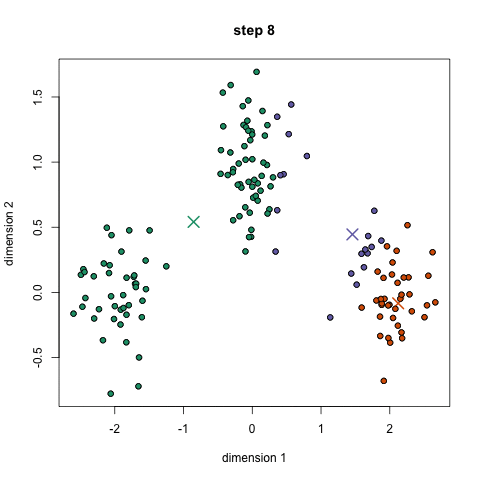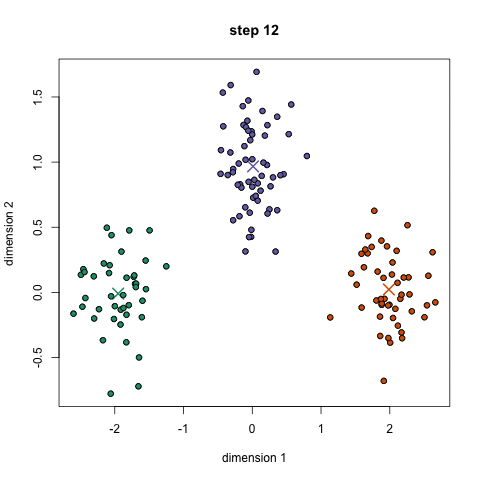
- 首先,选择一些类/组来使用并随机地初始化它们各自的中心点。要想知道要使用的类的数量,最好快速地查看一下数据,并尝试识别任何不同的分组。中心点是与每个数据点向量相同长度的向量,在上面的图形中是“X”。
- 每个数据点通过计算点可每个组中心之间的距离进行分类,然后将这个点分类为最接近它的组。
- 基于这些分类点,我们通过去组中所有向量的均值来重新计算中心。
- 对一组迭代重复这些步骤。你还可以选择随机初始化组中心几次,然后选择那些看起来对他提供好结果的来运行。
K-MEANS聚类算法的优势在于它的速度非常快,因为我们所有的只是计算点和集群中心之间的距离,它有一个线性复杂度O(n)[注意不是整体的时间复杂度]。
另一方面,K-MEANS也有几个缺点。首先,你必须选择有多少组/类。这并不是不重要的事,理想情况下,我们希望它能帮我门解决这些问题,因为他的关键在于从数据中国的一些启示,K-MEANS也从随机的聚类中心开始,因此在不同的算法运行中可能产生不同的聚类结果。因此,结果可能是不可重复的,并且缺乏一致性。其他聚类方法更加一致。
K-Medians是另一种与K-MEANS有关的聚类算法,除了使用均值的中间值来重新计算数组中心点以外,这种方法对于离散值的民高度较低(因为使用中值),但对于较大的数据集来说,它要慢得多,因为在计算中值向量时,每次迭代都需要进行排序。
推荐算法-聚类-K-MEANS的更多相关文章
- 推荐算法-聚类-DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,类似于均值转移聚类算法,但 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法 概述 无监督问题 手中无标签 聚类 将相似的东西分到一组 难点 如何 评估, 如何 调参 基本概念 要得到的簇的个数 - 需要指定 K 值 质心 - 均值, 即向量各维度取平均 距离的度量 ...
- apriori推荐算法
大数据时代开始流行推荐算法,所以作者写了一篇教程来介绍apriori推荐算法. 推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- 推荐算法相关总结表(包括DM)
推荐算法总结表 表1 推荐算法分类 个性化推荐算法分类 启发式算法 基于模型 基于内容 TF-IDF 聚类 最大熵 相似度度量 贝叶斯分类 决策树 神经网络 专家系统 知识推理 协同过滤 K近邻 聚类 ...
- 推荐算法之用矩阵分解做协调过滤——LFM模型
隐语义模型(Latent factor model,以下简称LFM),是推荐系统领域上广泛使用的算法.它将矩阵分解应用于推荐算法推到了新的高度,在推荐算法历史上留下了光辉灿烂的一笔.本文将对 LFM ...
随机推荐
- WooYun-2016-199433 -phpmyadmin-反序列化-getshell
文章参考 http://www.mottoin.com/detail/521.html https://www.cnblogs.com/xhds/p/12579425.html 虽然是很老的漏洞,但在 ...
- springAop:Aop(Xml)配置,Aop注解配置,spring_Aop综合案例,Aop底层原理分析
知识点梳理 课堂讲义 0)回顾Spring体系结构 Spring的两个核心:IoC和AOP 1)AOP简介 1.1)OOP开发思路 OOP规定程序开发以类为模型,一切围绕对象进行,OOP中完成某个任务 ...
- WPF 基础 - DataTemplate 和 ControlTemplate 的关系和应用
1. 关系 凡是 Template,最后都得作用到 控件 上,这个控件就是 Template 的目标控件(也称模板化控件): DataTemplate 一般是落实在一个 ContentPresente ...
- slickgrid ( nsunleo-slickgrid ) 4 解决区域选择和列选择冲突
slickgrid ( nsunleo-slickgrid ) 3 解决区域选择和列选择冲突 之前启用区域选择的时候,又启用了列选择(CheckboxSelectColumn),此时发现选择状态与区域 ...
- win8 下删除服务
1.右键 我的电脑-管理-服务和应用程序-服务,找到想要删除的服务,双击后复制服务名称. 2.管理员身份运行cmd 在命令框中输入 sc delete "secbizsrv" 就删 ...
- sort函数用于vector向量的排序
参考资料: 关于C++中vector和set使用sort方法进行排序 作者注:这篇文章写得相当全面,包括对vector和set中不同数据类型(包括结构体)的排序,还有一些还没看懂--特作此摘录,供当前 ...
- GCD and LCM HDU - 4497
题目链接:https://vjudge.net/problem/HDU-4497 题意:求有多少组(x,y,z)满足gcd(x,y,z)=a,lcm(x,y,z)=b. 思路:对于x,y,z都可以写成 ...
- 2019看雪CTF 晋级赛Q2第四题wp
上次参加2019看雪CTF 晋级赛Q2卡在了这道题上,虽然逆出算法,但是方程不会解,哈哈哈哈,果然数学知识很重要呀,现在记录一下. 首先根据关键信息,根据错误提示字符串定位到这里: 1 int __t ...
- 系统编程-信号-总体概述和signal基本使用
信号章节 -- 信号章节总体概要 信号基本概念 信号是异步事件,发送信号的线程可以继续向下执行而不阻塞. 信号无优先级. 1到31号信号是非实时信号,发送的信号可能会丢失,不支持信号排队. 31号信号 ...
- MySQL常用配置参数说明
1.sync_binlog sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来 ...