openpyxl 库
1. 简介与安装
2.具体示例
1. 简介与安装
openpyxl 简介
openpyxl 是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入、打印设置等内容。使用openpyxl可以读写xltm、xltx、xlsm、xlsx等类型的文件,且可以处理数据量较大的Excel文件,跨平台处理大量数据是其它模块没法相比的。因此,openpyxl成为处理Excel复杂问题的首选库函数。
openpyxl 与 xlrd/xlwt 的比较
两者都是对于excel文件操作的模块,其主要区别在于:
- 写操作:
- xlwt:针对Ecxec2007之前的版本(.xls),无法生成xlsx文件。
- openpyxl:主要针对Excel2007之后的版本(.xlsx)。
- 读写速度:
- xlrd/xlwt在读写方面的速度都要优于openpyxl。
- 文件大小:
- xlrd/xlwt:对单个sheet不超过65535行。
- openpyxl:对文件大小没有限制。
所以想要尽量提高效率又不影响结果时,可以考虑用 xlrd 读取,用 openpyxl 写入。
2.具体示例
具体的使用流程如下:
- 导入openpyxl模块;
- 调用 openpyxl.load_workbook() 函数或 openpyxl.Workbook(),取得Workbook对象;
- 调用 get_active_sheet() 或 get_sheet_by_name() 工作簿方法,取得Worksheet对象;
- 使用索引或工作表的 cell() 方法,带上row和column关键字参数,取得Cell对象,读取或编辑Cell对象的value属性。
2.1 获取workbook与sheet对象
创建新文件
1 from openpyxl import Workbook
2
3 # 创建工作簿对象
4 wb = Workbook()
5
6 # 激活sheet;拿到当前文件对象中默认操作的一个sheet,如上次关闭文件时所打开的sheet
7 ws = wb.active
8 # 表格在被创建的时候会自动的有一个名字。它们被命名在一个队列中(sheet, ...),可以使用title属性在任何时候来改变它们的名字。
9 ws.title = "tmp"
10
11 # 删除sheet
12 wb.remove(ws)
13
14 # 创建sheet
15 ws1 = wb.create_sheet("tmp1") # 默认在最后插入新sheet
16 ws2 = wb.create_sheet("tmp2", 0) # 在索引为0的位置插入
17
18 # 保存文件(覆盖同名文件的全部内容)
19 wb.save("文件名称.xlsx")
打开已有文件
1 # 打开已有文件
2 from openpyxl import load_workbook
3
4 # 打开指定文件
5 wb = load_workbook("e:\\test.xlsx")
6
7 # 查看所有sheet名
8 print(wb.sheetnames) # 返回列表
9 # 遍历所有sheet名
10 for sheet in wb.sheetnames:
11 print(sheet.title())
12
13 # 选择sheet
14 ws3 = wb["tmp3"] # 方法1:名称可以作为key进行查找
15 ws4 = wb.get_sheet_by_name("tmp4") # 方法2
16 print(ws3 is ws4) # True
17
18 # 在原有内容上进行修改并保存
19 wb.save("e:\\test.xlsx")
2.2 访问单元格及其值
注意:当一个工作表在内存中被创建时,它里面默认是没有表格对象的,它们只有在第一次被访问的时候才会被创建,从而减少内存占用。因为这个特性,我们要循环表格而不是直接访问它们,这样会将所有的表格对象在内存中创建,就算你没有访问它们中的任何一个值。
openpyxl 读写单元格时,单元格的坐标位置起始值是(1,1),即下标最小值为1。
访问单个单元格
1 # 获取最大行列(返回数值)
2 print(ws3.max_row)
3 print(ws3.max_column)
4
5 # 方法1:指定行列
6 print(ws3["A2"].value)
7
8 # 方法2:指定行列
9 print(ws3.cell(row=2, column=2).value) # 行号和列号从1开始
10
11 # 方法3:只要访问就会创建对应单元格对象
12 for i in range(1, 10):
13 for j in range(1, 10):
14 print(ws4.cell(i, j).value)
行列序号转换
1 from openpyxl.utils import get_column_letter, column_index_from_string
2
3 # 根据列的数字返回字母
4 print(get_column_letter(2)) # B
5 # 根据字母返回列的数字
6 print(column_index_from_string('D')) # 4
访问多个单元格
1 # 访问指定行数据
2
3 print(ws3[1]) # 方法1:索引从1开始
4 print(ws3[1:3]) # 切片方式,返回二维元组
5 print(tuple(ws3.rows)[1]) # 方法2:索引从0开始,sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹
6 # 遍历获取每个单元格的值
7 for cell in ws3[1]:
8 print(cell.value)
9
10
11 # 访问指定列数据
12
13 print(ws3["A"])
14 print(tuple(ws3.columns)[1]) # 访问第2列单元格
15 print(ws3["A:C"]) # 返回二维元组
16
17
18 # 指定范围
19
20 # 方法1
21 print(ws3["A1:B4"])
22 # 方法2:最多访问两行两列的单元格
23 for row in ws3.iter_rows(min_row=1, max_row=2, max_col=2): # 行号和列号从1开始
24 for cell in row:
25 print(cell)
26 '''执行结果:
27 <Cell 'tmp3'.A1>
28 <Cell 'tmp3'.B1>
29 <Cell 'tmp3'.A2>
30 <Cell 'tmp3'.B2>
31 '''
32
33 for row in ws3.iter_cols(min_row=1, max_row=2, max_col=2): # 行号和列号从1开始
34 for cell in row:
35 print(cell)
36 '''注意与上述iter_rows的获取顺序不同
37 <Cell 'tmp3'.A1>
38 <Cell 'tmp3'.A2>
39 <Cell 'tmp3'.B1>
40 <Cell 'tmp3'.B2>
41 '''
矩阵置换
1 rows = [
2 ['Number', 'data1', 'data2'],
3 [2, 40, 30],
4 [3, 40, 25],
5 [4, 50, 30],
6 [5, 30, 10],
7 [6, 25, 5],
8 [7, 50, 10]]
9 print(list(zip(*rows))) # 传入二维序列时需要解包
10 '''执行结果:
11 [('Number', 2, 3, 4, 5, 6, 7), ('data1', 40, 40, 50, 30, 25, 50), ('data2', 30, 25, 30, 10, 5, 10)]
12 '''
13
14 # 注意:该方法会舍弃缺少数据的列(行)
15 a1 = [1, 2]
16 a2 = [4, 5, 6]
17 print(list(zip(a1, a2)))
18 '''执行结果:
19 [(1, 4), (2, 5)]
20 '''
2.3 写数据
写入单元格值
1 # 写入常规值
2
3 # 方法1
4 ws3["A1"] = 1
5 # 方法2:行号和列号从1开始
6 ws3.cell(row=2, column=2, value="A2")
7 # 方法3:追加一行数据(即最下方空白处的最左第一个单元格开始)
8 ws3.append([1, 2, 3])
9
10
11 # 写时间
12 import time
13
14 # 方法1
15 now_time_1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
16 ws3.cell(row=1, column=1, value=now_time_1)
17
18 # 方法2
19 import locale
20 locale.setlocale(locale.LC_ALL, 'en')
21 locale.setlocale(locale.LC_CTYPE, 'chinese')
22 now_time_2 = time.strftime("%Y年%m月%d日 %H:%M:%S") # 自动传入当前时间
23 ws3.cell(row=1, column=2, value=now_time_2)
合并单元格
合并单元格以合并区域的左上角的那个单元格为基准,覆盖其他单元格,使之称为一个大的单元格。
相反,拆分单元格后将这个大单元格的值返回到原来的左上角位置。
1 ws3.merge_cells('A1:B1') # 合并一行中的几个单元格
2 ws3.merge_cells('B2:C11') # 合并一个矩形区域中的单元格
合并后只可以往左上角写入数据,也就是区间中最左上角的坐标。
如果这些要合并的单元格都有数据,只会保留左上角的数据,其他则丢弃。换句话说若合并前不是在左上角写入数据,那么合并后的单元格则不会有数据。
拆分单元格
1 ws3.unmerge_cells('A1:B1') # 拆分后,值回写到A1位置
2 ws3.unmerge_cells('B2:C11') # 拆分后,值回写到B2位置
2.4 设置样式
sheet标签颜色
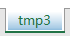
1 ws3.sheet_properties.tabColor = "1072BA"
效果:
行高与列宽
1 # 第2行行高
2 ws3.row_dimensions[2].height = 40
3 # C列列宽
4 ws3.column_dimensions['C'].width = 30
单元格样式
1 '''字体'''
2 # 等线24号,加粗斜体,字体颜色红色
3 bold_italic_24_font = Font(name='等线', size=24, italic=True, color=colors.RED, bold=True)
4 # 直接使用cell的font属性,将Font对象赋值给它
5 ws3['A1'].font = bold_italic_24_font
6
7 '''对齐方式'''
8 # 设置B1中的数据垂直居中和水平居中(除了center,还可以使用right、left等参数)
9 ws3['B1'].alignment = Alignment(horizontal='center', vertical='center')
openpyxl 库的更多相关文章
- pyinstaller打包程序包含openpyxl库问题解决
带有openpyxl库时,直接打包,总会失败: 原因:看本地文件...Anaconda3\Lib\site-packages\PyInstaller\hooks\hook-openpyxl.py 发现 ...
- openpyxl库实现对excel文档进行编辑(追加写入)
首先,这个库只支持xlsx格式的excel文件 预期,对”excel_test.xlsx“的A1单元格写入”hello word“ 1.安装”openpyxl“库,pip install openpy ...
- 20201207-2 openpyxl 库与模块导入
1-1 import openpyxl # 通过文件路径,打开工作簿 wb1 = openpyxl.load_workbook('./demo_excel.xlsx') # 用 Workbook() ...
- 爬虫入门【9】Python链接Excel操作详解-openpyxl库
Openpyx是一个用于读写Excel2010各种xlsx/xlsm/xltx/xltm文件的python库. 现在大多数用的都是office2010了,如果之前之前版本的可以使用xlrd读,xlwt ...
- python3 使用openpyxl库读写excel(续)
官网:https://openpyxl.readthedocs.io/en/stable/
- python关于openpyxl库的常用使用介绍
from openpyxl import load_workbook #只能加载已存在的表格 wb=load_workbook("D:\zhijing_work\测试数据\测试文件\yeta ...
- 女朋友汇总表格弄了大半天,我实在看不下去了,用40行代码解决问题 | Python使用openpyxl库读写表格Excel(xlsx)
1.openpyxl基本操作 python程序从excel文件中读数据基本遵循以下步骤: 1.import openpyxl 2.调用openpyxl模块下的load_workbook('你的文件名. ...
- 用python库openpyxl操作excel,从源excel表中提取信息复制到目标excel表中
现代生活中,我们很难不与excel表打交道,excel表有着易学易用的优点,只是当表中数据量很大,我们又需要从其他表册中复制粘贴一些数据(比如身份证号)的时候,我们会越来越倦怠,毕竟我们不是机器,没法 ...
- python 操作exls学习之路1-openpyxl库学习
这篇要讲到的就是如何利用Python与openpyxl结合来处理xlsx表格数据.Python处理表格的库有很多,这里的openpyxl就是其中之一,但是它是处理excel2007/2010的格式,也 ...
随机推荐
- java基础学习——Swing图形化用户界面编程
原文链接:https://blog.csdn.net/yiziweiyang/article/details/52317240 链接有详细解释,也有例子,以下是个人参照例子实验的代码. package ...
- MySQL like查询使用索引
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来.这个时候查询的效率就 ...
- python类的内部方法
目录 一.绑定方法与非绑定方法 1.绑定方法 2.非绑定方法 二.property 1.什么是property? 2.为什么要用property? 3.如何使用property? 三.isinstan ...
- 《C++ Primer》笔记 第13章 拷贝控制
拷贝和移动构造函数定义了当用同类型的另一个对象初始化本对象时做什么.拷贝和移动赋值运算符定义了将一个对象赋予同类型的另一个对象时做什么.析构函数定义了当此类型对象销毁时做什么.我们称这些操作为拷贝控制 ...
- 微信小程序弹出层
1.消息提示 wx.showToast wx.showToast({ title: '成功', icon: 'success', duration: 2000 })2.模态弹窗 wx.show ...
- 洛谷P3285 [SCOI2014]方伯伯的OJ 动态开点平衡树
洛谷P3285 [SCOI2014]方伯伯的OJ 动态开点平衡树 题目描述 方伯伯正在做他的 \(Oj\) .现在他在处理 \(Oj\) 上的用户排名问题. \(Oj\) 上注册了 \(n\) 个用户 ...
- SQL驱动限制,导致插入失败
insert into TB_IF_ORDERS (DC_CD,JOB_DT,SEQ_NO,ORDER_KEY,ORDER_ID,ORDER_LINE_NUM,COMPANY_CD,CUST_CD,S ...
- css盒布局-省份选择盘的实现
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- 快速了解C# 8.0中“可空引用类型(Nullable reference type)”语言特性
Visual C# 8.0中引入了可空引用类型(Nullable reference type),通过编译器提供的强大功能,帮助开发人员尽可能地规避由空引用带来的代码问题.这里我大致介绍一下可空引用类 ...
- 【Django笔记2】-创建应用(app)与模型(models)
1,创建应用(app) 一个完善的网站需要许多功能提供不同的服务.如果所有的功能都在一个文件中,不利于项目多人共同开发,以及后续的维护.此时可以针对一个要实现的功能,创建一个app,将多个app结 ...