基于Tesseract组件的OCR识别
基于Tesseract组件的OCR识别
背景以及介绍
欲研究C#端如何进行图像的基本OCR识别,找到一款开源的OCR识别组件。该组件当前已经已经升级到了4.0版本。和传统的版本(3.x)比,4.0时代最突出的变化就是基于LSTM神经网络。Tesseract本身是由C++进行编写,但为了同时适配不同的语言进行调用,开放调用API并产生了诸如Java、C#、Python等主流语言在内的封装版本。本次主要研究C#封装版。
项目结构
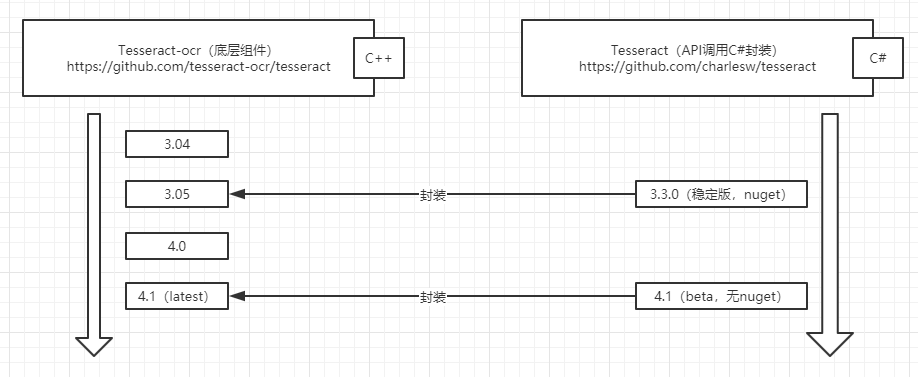
Tesseract本身由C++编写并开源在Github,在3.X版本中,Tesseract的识别模式为字符识别,该种识别方式识别能力较低,所以在后来的4.X版本中,引入了LSTM(Long short-term memory,长短期记忆神经网络),极大的提升了识别率。为了让不同的语言均能够使用Tesseract进行OCR识别,Tesseract也是开放了API并产生了诸如Java、C#、Python等主流语言在内的封装版本。而本次C#端的封装版也开源在了Github,目前已知的C#封装版已发布在nuget上,封装了对应Tesseract的版本为3.05.02。所以目前的项目结构如下:
Demo实验
环境准备
文本识别数据包准备
因为图像识别本身需要文本识别数据进行匹配,所以我们需要下载对应Tesseract官方的文本数据包:
https://tesseract-ocr.github.io/tessdoc/Data-Files
注意,针对不同版本的Tesseract-OCR(3.X和4.X底层的实现方式不同,所以文本识别数据包是不同的),我们需要找到对应的不同的文本训练数据包,官网为了更好的兼容性,4.X版本的文本数据包是兼容了3.X版本的。
the third set in tessdata is the only one that supports the legacy recognizer. The 4.00 files from November 2016 have both legacy and older LSTM models. The current set of files in tessdata have the legacy models and newer LSTM models (integer versions of 4.00.00 alpha models in tessdata_best).
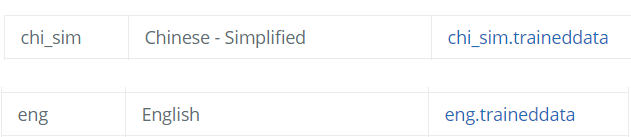
为了Demo,我下载了中文简体和英文的数据包作为实验对象
开发环境准备
为了实验并对比上面两个封装版本的识别效果,这里在同一解决方案中创建了两个项目:
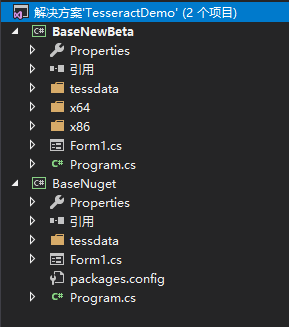
BaseNewBeta使用的是封装了4.1版本Tesseract的C#封装版Tesseract.4.1.0-beta1,因为该版本还还没有上传只Nuget,所以只能从github上下载,放到本地,然后把对应的C++的底层库(leptonica-1.78.0.dll,tesseract41.dll)放置到了x86和x64文件夹下面且需要输出。
BaseNuget是已经上传至Nuget的封装了底层库3.05.20版本的C#封装版3.3.0.0,因为使用nuget进行组件安装,所以x64和x86的Tesseract组件会在编译输出时候自动输出到对应的生成目录。
核心代码
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
//PictureBox控件显示图片
pictureBox1.Load(openFileDialog1.FileName);
//获取用户选择文件的后缀名
string extension = Path.GetExtension(openFileDialog1.FileName);
//声明允许的后缀名
string[] str = new string[] { ".jpg", ".png" };
if (!str.Contains(extension))
{
MessageBox.Show("仅能上传jpg,png格式的图片!");
}
else
{
//识别图片文字
Bitmap img = new Bitmap(openFileDialog1.FileName);
// 构建识别引擎
TesseractEngine orcEngine = new TesseractEngine("./tessdata", "eng");
// 识别并获取文本数据
Page page = orcEngine.Process(img);
richTextBox1.Text = page.GetText();
}
}
最终效果
英文识别效果
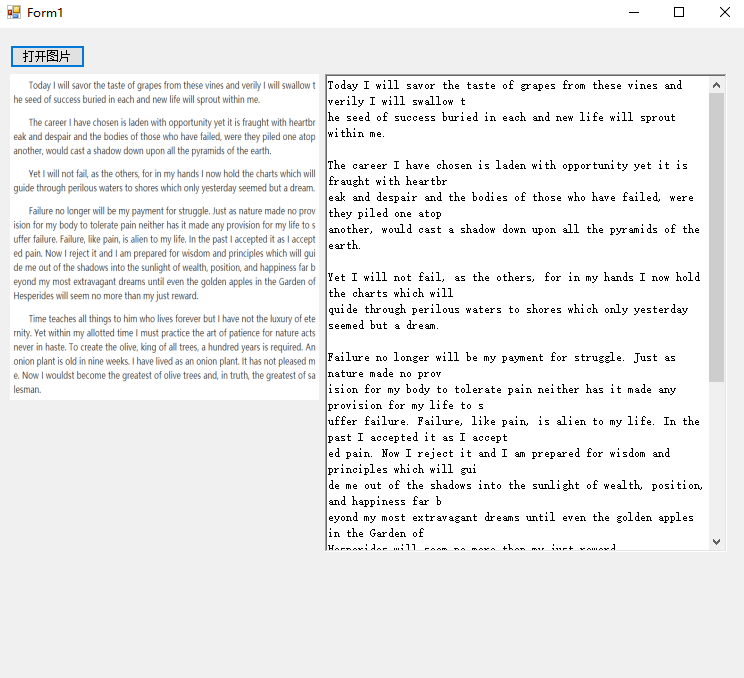
先是3.X版本识别:

可以看到文本中还有很多识别的错误的,特别是把英文字符C识别为了括号(。
而封装了新版本的识别结果比起之前更好:
中文识别效果
先是3.X版本识别:

然后是封装的版本:
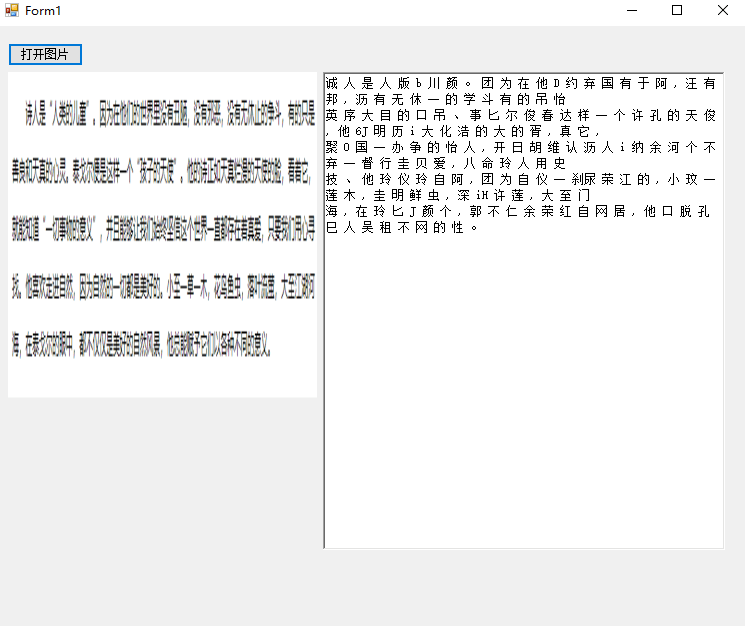
看的出来,官方的数据包对于中文的识别还是有很大问题的,不过庆幸的是,4.X版本的后的Tesseract支持我们使用的自己的数据进行识别训练。这样一来,虽然该组件还比不上市面上大多数的商业OCR识别,但是我们可以使用训练数据,来训练适用于我们特定业务的文字识别(比如XX码的提取之类)
基于Tesseract组件的OCR识别的更多相关文章
- 基于百度云的OCR识别(Python)
2019年7月3日早上,在百度AI开发者大会上,一个来自山西的青年,将一瓶矿泉水浇在了同样来自山西的李彦宏身上. 可以回顾一下 https://b23.tv/av57665929/p1 ,着实让人一惊 ...
- 基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[l ...
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- Android开发如何轻松实现基于Tesseract的Android OCR应用程序
介绍 此应用程序使用Tesseract 3的Tesseract OCR引擎,该引擎通过识别字符模式( https://github.com/tesseract-ocr/tesseract )来工作. ...
- 基于Tesseract的OCR识别小程序
一.背景 先说下开发背景,今年有次搬家找房子(2020了应该叫去年了),发现每天都要对着各种租房广告打很多电话.(当然网上也找了实地也找),每次基本都是对着墙面看电话号码然后拨打,次数一多就感觉非常麻 ...
- 基于Python实现对PDF文件的OCR识别
http://www.jb51.net/article/89955.htm https://pythontips.com/2016/02/25/ocr-on-pdf-files-using-pytho ...
- 【OCR技术系列之四】基于深度学习的文字识别(3755个汉字)
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
- Python&selenium&tesseract自动化测试随机码、验证码(Captcha)的OCR识别解决方案参考
在自动化测试或者安全渗透测试中,Captcha验证码的问题经常困扰我们,还好现在OCR和AI逐渐发展起来,在这块解决上越来越支撑到位. 我推荐的几种方式,一种是对于简单的验证码,用开源的一些OCR图片 ...
- 【OCR技术系列之四】基于深度学习的文字识别
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
随机推荐
- 如何在 Go 中嵌入 Python
如果你看一下 新的 Datadog Agent,你可能会注意到大部分代码库是用 Go 编写的,尽管我们用来收集指标的检查仍然是用 Python 编写的.这大概是因为 Datadog Agent 是一个 ...
- ArrayPool 源码解读之 byte[] 也能池化?
一:背景 1. 讲故事 最近在分析一个 dump 的过程中发现其在 gen2 和 LOH 上有不少size较大的free,仔细看了下,这些free生前大多都是模板引擎生成的html片段的byte[]数 ...
- 搭建本地yum源出现:mount: 在 /dev/sr0 上找不到媒体
2021-07-27 在练习环境搭建时,因为是离线环境,故先搭建本地yum源,但是出现了一个往常没有的问题:mount: 在 /dev/sr0 上找不到媒体,参考其他博主的文章得到解决方法. 排查问题 ...
- Linux系统的日志管理、时间同步、延迟命令at
方便查看和管理 /var/log/messages ?系统服务及日志,包括服务的信息,报错等等 /var/log/secure ? ? ? ? 系统认证信息日志 /var/log/maillog ? ...
- 未能找到源类型“DbSet<T>”的查询模式的实现。未找到“Select”
使用EF6.0的模型优先模式进行开发,遇到了报错,如下图 后来发现是没引用using System.Linq; 引用后就不报错了
- Python习题集(十五)
每天一习题,提升Python不是问题!!有更简洁的写法请评论告知我! https://www.cnblogs.com/poloyy/category/1676599.html 题目 请写一个函数,该函 ...
- AI异构通信:重压下的突围,华为P50系列的卓越体验
撰文 |懂懂 编辑 | 秦言 来源:懂懂笔记 "华为不会让消费者失望."华为消费者业务CEO余承东在P50系列发布会上如是说. 今年4月美国对华为第四轮制裁以来,华为终端产品无缘5 ...
- Windows下安装程序时提示未安装Microsoft Net FrameWork 2.0
问题描述 安装程序时碰到如下: 现在基本都是用win7.win10系统,缺少环境大多数都是因为系统没有启用. 解决方法 控制面板 - 程序 - 启用或关闭Windows功能 - 把第一项'NET Fr ...
- Typeora 图床设置
Typeora 文章中的图片 使用 Github 作为图床. 使用 PicGo 上传图片到 Github 并获取图片链接. 设置 Typeora 的上传服务. 一.Github 作为图床 创建 Rep ...
- 【转】.net core开发windows服务
.net core开发windows服务 文建Blog