Spark(一)介绍
随着对spark的业务更深入,对spark的了解也越多,然而目前还处于知道的越多,不知道的更多阶段,当然这也是成长最快的阶段。这篇文章用作总结最近收集及理解的spark相关概念及其关系。
名词
driver
driver物理层面是指输入提交spark命令的启动程序,逻辑层面是负责调度spark运行流程包括向master申请资源,拆解任务,代码层面就是sparkcontext。
worker
worker指可以运行的物理节点。
executor
executor指执行spark任务的处理程序,对java而言就是拥有一个jvm的进程。一个worker节点可以运行多个executor,只要有足够的资源。
job
job是指一次action,rdd(rdd在这里就不解释了)操作分成两大类型,一类是transform,一类是action,当涉及到action的时候,spark就会把上次action之后到本次action的所有rdd操作用一个job完成。
stage
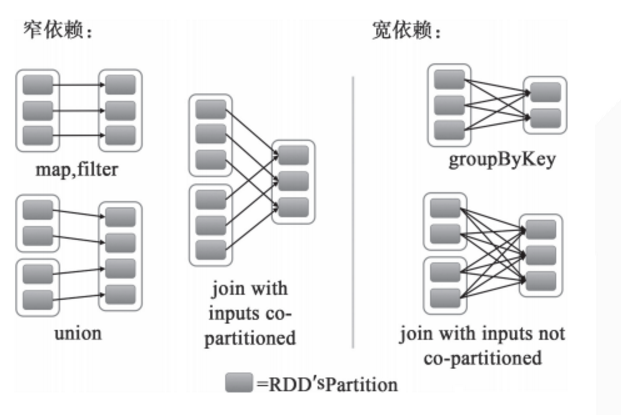
stage是指一次shuffle,rdd在操作的时候分为宽依赖(shuffle dependency)和窄依赖(narraw dependency),如下图所示。而宽依赖就是指shuffle。
应某人要求再解释一下什么是窄依赖,就是父rdd的每个分区都只作用在一个子rdd的分区中,原话是这么说的 each partition of the parent RDD is used by at most one partition of the child RDD。
task
task是spark的最小执行单位,一般而言执行一个partition的操作就是一个task,关于partition的概念,这里稍微解释一下。
spark的默认分区数是2,并且最小分区也是2,改变分区数的方式有很多,大概有三个阶段
1.启动阶段,通过 spark.default.parallelism 来初始化默认分区数
2.生成rdd阶段,可通过参数配置
3.rdd操作阶段,默认继承父rdd的partition数,最终结果受shuffle操作和非shuffle操作的影响,不同操作的结果partition数不同
名词关系
物理关系
官网给出的spark运行架构图

逻辑关系
下图是总结的逻辑关系图,如果有不对之处,还望提醒

参考资料
//spark apche的官网提供的参数配置清单
http://spark.apache.org/docs/latest/configuration.html
//spark apche的官网提供的spark运行总览
http://spark.apache.org/docs/latest/cluster-overview.html
//stackoverflow对于dataframe partition的解释
http://stackoverflow.com/questions/39368516/number-of-partitions-of-spark-dataframe
//关于spark最小分区数的解释
https://github.com/mesos/spark/pull/718
Spark(一)介绍的更多相关文章
- spark API 介绍链接
spark API介绍: http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html#aggregateByKey
- Spark角色介绍及spark-shell的基本使用
Spark角色介绍 1.Driver 它会运行客户端的main方法,构建了SparkContext对象,它是所有spark程序的入口 2.Application 它就是一个应用程序,包括了Driver ...
- Spark概念介绍
Spark概念介绍:spark应用程序在集群中以一系列独立的线程运行,通过驱动器程序(Driver Program)发起一系列的并行操作.SparkContext对象作为中间的连接对象,通过Spark ...
- Spark MLlib介绍
Spark MLlib介绍 Spark之所以在机器学习方面具有得天独厚的优势,有以下几点原因: (1)机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足 ...
- 2 Spark角色介绍及运行模式
第2章 Spark角色介绍及运行模式 2.1 集群角色 从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承 ...
- Spark Transformations介绍
背景 本文介绍是基于Spark 1.3源码 如何创建RDD? RDD可以从普通数组创建出来,也可以从文件系统或者HDFS中的文件创建出来. 举例:从普通数组创建RDD,里面包含了1到9这9个数字,它们 ...
- spark算子介绍
1.spark的算子分为转换算子和Action算子,Action算子将形成一个job,转换算子RDD转换成另一个RDD,或者将文件系统的数据转换成一个RDD 2.Spark的算子介绍地址:http:/ ...
- Spark—RDD介绍
Spark-RDD 1.概念介绍 RDD(Resilient Distributed Dataset):弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算 ...
- Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中
一.前言 近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面! 大数据技术也是有很多: Hadoop Spark Flink 小编也只知道这些了,由于Hadoop, ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
随机推荐
- 全量日志 requestId
常量参数和系统参数 API 的请求者不可见,由网关在请求后端服务时添加上. 常量参数.比如您的后端需要接收一个常量,但是这个常量您不希望被您的客户看见,那么就设置一个常量参数,可以在 Header 或 ...
- Linux上安装MySQL及其基础配置
本文主要介绍Linux下使用yum安装MySQL,以及启动.登录和远程访问MySQL数据库. 1.安装 查看有没有安装过: yum list installed mysql* rpm -qa | gr ...
- Service Receiver Activity 之间的通信
一.Activity与Service 1. 通过Intent,例子如下: Intent intent = new Intent(this, Myservice.class); // intent .p ...
- spring 启动过程
首先,对于一个web应用,其部署在web容器中,web容器提供其一个全局的上下文环境,这个上下文就是ServletContext,其为后面的spring IoC容器提供宿主环境: 其次,在web.xm ...
- 如何用meavn构建mahout项目
(1)下载meavn 解压到D盘
- Yii 2.x 和1.x区别以及yii2.0安装
知乎上有个类似的问题:http://www.zhihu.com/question/22924271/answer/23085751 大致思路不会变,开发流程变化也不是很大.有变化的是1.yii2带入的 ...
- 存储器系列,L1缓存,L2缓存,内存(RAM),EEPROM和闪存,CMOS与BIOS电池
因为各级存储硬件的参数和性能不同所以在计算机硬件当中分为以下几种: 由此可见顶级空间小但处理速度最快,下层容量大但处理速度时间较长. 存储器系统采用分层结构,顶层的存储器速度较高,容量较小,与底层的存 ...
- SqlServer中创建Oracle链接服务器
SqlServer中创建Oracle链接服务器 第一种:界面操作 (1)展开服务器对象-->链接服务器-->右击“新建链接服务器” (2)输入链接服务器的IP (3)链接成功后 第二种:语 ...
- (C++) Assertion failed: !"Bad error code", file VMem.c, line 715
(C++) Assertion failed: !"Bad error code", file VMem.c, line 715 Misc error. myInterface F ...
- Linux系统——本地yum仓库安装
一.yum仓库概述 yum是基于rpm包管理,能够从指定的服务器自动下载rpm包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无需繁琐地一次次下载.安装. 二.yum仓库安装的方式 ...