【sklearn】网格搜索 from sklearn.model_selection import GridSearchCV
GridSearchCV用于系统地遍历模型的多种参数组合,通过交叉验证确定最佳参数。
1.GridSearchCV参数
# 不常用的参数
- pre_dispatch
没看懂
- refit
- 默认为True
- 在参数搜索参数后,用最佳参数的结果fit一遍全部数据集
- iid
- 默认为True
- 各个样本fold概率分布一致,误差估计为所有样本之和
# 常用的参数
- cv
- 默认为3
- 指定fold个数,即默认三折交叉验证
- verbose
- 默认为0
- 值为0时,不输出训练过程;值为1时,偶尔输出训练过程;值>1时,对每个子模型都输出训练过程
- n_jobs
- cpu个数
- 值为-1时,使用全部CPU;值为1时,使用1个CPU;值为2时,使用2个CPU
- estimator
- 分类器
- param_grid
- 参数范围,值为列表/字典
- scoring
- 准确度评价标准,socring参数选择链接
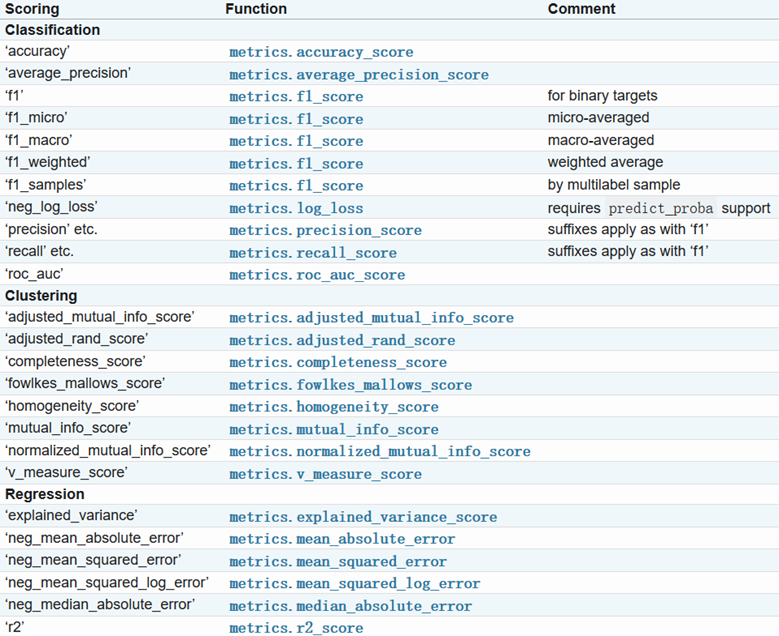
2.常用属性
- best_score_
- 最佳模型下的分数
- best_params_
- 最佳模型参数
- grid_scores_
- 模型不同参数下交叉验证的平均分
- cv_results_ 具体用法
- 模型不同参数下交叉验证的结果
- best_estimator_
- 最佳分类器
注:grid_scores_在sklearn0.20版本中将被删除。使用cv_results_替代
3.常用函数
- score(x_test,y_test)
- 最佳模型在测试集下的分数
4.例子
1 # -*- coding: utf-8 -*-
2 """
3 # 数据:20类新闻文本
4 # 模型:svc
5 # 调参:gridsearch
6 """
7 ### 加载模块
8 import numpy as np
9 import pandas as pd
10
11 ### 载入数据
12 from sklearn.datasets import fetch_20newsgroups # 20类新闻数据
13 news = fetch_20newsgroups(subset='all') # 生成20类新闻数据
14
15 ### 数据分割
16 from sklearn.cross_validation import train_test_split
17 X_train, X_test, y_train, y_test = train_test_split(news.data[:300],
18 news.target[:300],
19 test_size=0.25, # 测试集占比25%
20 random_state=33) # 随机数
21 ### pipe-line
22 from sklearn.feature_extraction.text import TfidfVectorizer # 特征提取
23 from sklearn.svm import SVC # 载入模型
24 from sklearn.pipeline import Pipeline # pipe_line模式
25 clf = Pipeline([('vect', TfidfVectorizer(stop_words='english', analyzer='word')),
26 ('svc', SVC())])
27
28 ### 网格搜索
29 from sklearn.model_selection import GridSearchCV
30 parameters = {'svc__gamma': np.logspace(-1, 1)} # 参数范围(字典类型)
31
32 gs = GridSearchCV(clf, # 模型
33 parameters, # 参数字典
34 n_jobs=1, # 使用1个cpu
35 verbose=0, # 不打印中间过程
36 cv=5) # 5折交叉验证
37
38 gs.fit(X_train, y_train) # 在训练集上进行网格搜索
39
40 ### 最佳参数在测试集上模型分数
41 print("best:%f using %s" % (gs.best_score_,gs.best_params_))
42
43 ### 测试集下的分数
44 print("test datasets score" % gs.score(X_test, y_test))
45
46 ### 模型不同参数下的分数
47 # 方式一(0.20版本将删除)
48 print(gs.grid_scores_)
49
50 # 方式二(0.20推荐的方式)
51 means = gs.cv_results_['mean_test_score']
52 params = gs.cv_results_['params']
53
54 for mean, param in zip(means,params):
55 print("%f with: %r" % (mean,param))
【sklearn】网格搜索 from sklearn.model_selection import GridSearchCV的更多相关文章
- 机器学习笔记——模型调参利器 GridSearchCV(网格搜索)参数的说明
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数.但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果.这个时候就是需要动脑筋了.数据量比较大 ...
- GridSearchCV网格搜索得到最佳超参数, 在K近邻算法中的应用
最近在学习机器学习中的K近邻算法, KNeighborsClassifier 看似简单实则里面有很多的参数配置, 这些参数直接影响到预测的准确率. 很自然的问题就是如何找到最优参数配置? 这就需要用到 ...
- 使用GridSearchCV进行网格搜索微调模型
import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- 机器学习:使用scikit-learn库中的网格搜索调参
一.scikit-learn库中的网格搜索调参 1)网格搜索的目的: 找到最佳分类器及其参数: 2)网格搜索的步骤: 得到原始数据 切分原始数据 创建/调用机器学习算法对象 调用并实例化scikit- ...
- Python机器学习笔记 Grid SearchCV(网格搜索)
在机器学习模型中,需要人工选择的参数称为超参数.比如随机森林中决策树的个数,人工神经网络模型中隐藏层层数和每层的节点个数,正则项中常数大小等等,他们都需要事先指定.超参数选择不恰当,就会出现欠拟合或者 ...
- 网格搜索与K近邻中更多的超参数
目录 网格搜索与K近邻中更多的超参数 一.knn网格搜索超参寻优 二.更多距离的定义 1.向量空间余弦相似度 2.调整余弦相似度 3.皮尔森相关系数 4.杰卡德相似系数 网格搜索与K近邻中更多的超参数 ...
- 机器学习算法中的网格搜索GridSearch实现(以k-近邻算法参数寻最优为例)
机器学习算法参数的网格搜索实现: //2019.08.031.scikitlearn库中调用网格搜索的方法为:Grid search,它的搜索方式比较统一简单,其对于算法批判的标准比较复杂,是一种复合 ...
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
随机推荐
- Mybatis <if>标签使用注意事项
在<if>标签的test中,不能写成“name !='aa'” , 会报错### Error querying database. Cause: java.lang.NumberForma ...
- SaltStack日常维护-第七篇
练习内容 远程执行其他模块 官方模块有很多超过300+ 1.cmd.run 2.network 3.service 4.state 5.其它日常维护 演示 cmd.run模块 可以执行系统命令,超级模 ...
- websocket 重连解决方案
1.websocket 重连的脚本:https://github.com/joewalnes/reconnecting-websocket reconnecting-w ...
- 爬虫之xpath
什么是XML XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 的标签需要 ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- hiho#1080 更为复杂的买卖房屋姿势 线段树+区间更新
#1080 : 更为复杂的买卖房屋姿势 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和小Ho都是游戏迷,“模拟都市”是他们非常喜欢的一个游戏,在这个游戏里面他们 ...
- RabbitMQ 之消息确认机制(事务+Confirm)
概述 在 Rabbitmq 中我们可以通过持久化来解决因为服务器异常而导致丢失的问题,除此之外我们还会遇到一个问题:生产者将消息发送出去之后,消息到底有没有正确到达 Rabbit 服务器呢?如果不错得 ...
- openstack dpdk
# ovs-vsctl showeef7cd95-0677-486c-b119-5d6ac8531c56 Manager "ptcp:6640:127.0.0.1" is_conn ...
- 三、nginx 编译参数
命令 --prefix=/usr/share/nginx # nginx 帮助目录 --sbin-path=/usr/sbin/nginx # nginx 执行命令 --modules-path=/u ...
- head first python选读(5)
python web 开发 犯了低级错误,这本书看了一半了才知道书名应为<head first python>,不是hand first.. 现在开始一个web应用. 总算是熟悉的内容了. ...