吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes
from sklearn.model_selection import train_test_split # 加载 scikit-learn 自带的 digits 数据集
def load_data():
'''
加载用于分类问题的数据集。这里使用 scikit-learn 自带的 digits 数据集
'''
digits=datasets.load_digits()
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #伯努利贝叶斯BernoulliNB模型
def test_BernoulliNB(*data):
X_train,X_test,y_train,y_test=data
cls=naive_bayes.BernoulliNB()
cls.fit(X_train,y_train)
print('Training Score: %.2f' % cls.score(X_train,y_train))
print('Testing Score: %.2f' % cls.score(X_test, y_test)) # 产生用于分类问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_BernoulliNB
test_BernoulliNB(X_train,X_test,y_train,y_test)

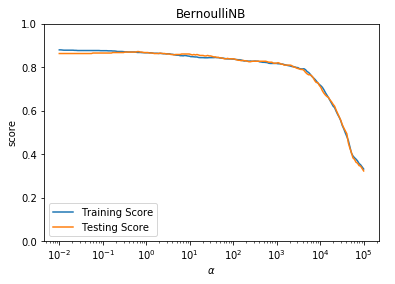
def test_BernoulliNB_alpha(*data):
'''
测试 BernoulliNB 的预测性能随 alpha 参数的影响
'''
X_train,X_test,y_train,y_test=data
alphas=np.logspace(-2,5,num=200)
train_scores=[]
test_scores=[]
for alpha in alphas:
cls=naive_bayes.BernoulliNB(alpha=alpha)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test)) ## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(alphas,train_scores,label="Training Score")
ax.plot(alphas,test_scores,label="Testing Score")
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel("score")
ax.set_ylim(0,1.0)
ax.set_title("BernoulliNB")
ax.set_xscale("log")
ax.legend(loc="best")
plt.show() # 调用 test_BernoulliNB_alpha
test_BernoulliNB_alpha(X_train,X_test,y_train,y_test)
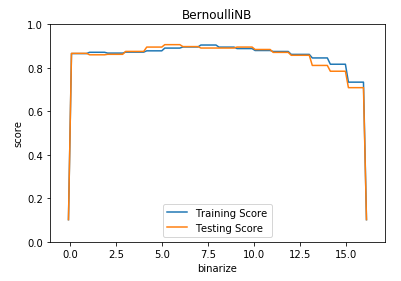
def test_BernoulliNB_binarize(*data):
'''
测试 BernoulliNB 的预测性能随 binarize 参数的影响
'''
X_train,X_test,y_train,y_test=data
min_x=min(np.min(X_train.ravel()),np.min(X_test.ravel()))-0.1
max_x=max(np.max(X_train.ravel()),np.max(X_test.ravel()))+0.1
binarizes=np.linspace(min_x,max_x,endpoint=True,num=100)
train_scores=[]
test_scores=[]
for binarize in binarizes:
cls=naive_bayes.BernoulliNB(binarize=binarize)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test)) ## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(binarizes,train_scores,label="Training Score")
ax.plot(binarizes,test_scores,label="Testing Score")
ax.set_xlabel("binarize")
ax.set_ylabel("score")
ax.set_ylim(0,1.0)
ax.set_xlim(min_x-1,max_x+1)
ax.set_title("BernoulliNB")
ax.legend(loc="best")
plt.show() # 调用 test_BernoulliNB_binarize
test_BernoulliNB_binarize(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型的更多相关文章
- 【sklearn朴素贝叶斯算法】高斯分布/多项式/伯努利贝叶斯算法以及代码实例
朴素贝叶斯 朴素贝叶斯方法是一组基于贝叶斯定理的监督学习算法,其"朴素"假设是:给定类别变量的每一对特征之间条件独立.贝叶斯定理描述了如下关系: 给定类别变量\(y\)以及属性值向 ...
- 概率图模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-多项式贝叶斯
之前忘记强调了一个重要差别:条件概率链式法则和贝叶斯网络链式法则的差别 条件概率链式法则 贝叶斯网络链式法则,如图1 图1 乍一看非常easy认为贝叶斯网络链式法则不就是大家曾经学的链式法则么,事实上 ...
- 概率图形模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-贝叶斯多项式
之前忘记强调重要的差异:链式法则的条件概率和贝叶斯网络的链式法则之间的差异 条件概率链式法则 P\left({D,I,G,S,L} \right) = P\left( D \right)P\left( ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- 吴裕雄 python 机器学习——高斯贝叶斯分类器GaussianNB
import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from sklearn.model_selectio ...
随机推荐
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- 18家大厂Java面试题整理了350道(分布式+微服务+高并发)
一.性能调优系列 1.Tomcat性能调优 JVM参数调优: -Xms 表示JVM初始化堆的大小, -Xmx表示JVM堆的最大值.这两个值的大小一般根据需要进行设置. 当应用程序需要的内存超出堆的最大 ...
- C++ 获取当前正在执行的函数的相关信息(转)
该功能用在日志打印中 原文地址:C++ 获取当前正在执行的函数的相关信息
- SpringBoot学习- 1、SpringSuit创建项目
SpringBoot学习足迹 前言:最近一次开发java后台应用还是三年前的2017年,主要使用SSH开发小型外包项目和公司的一个产品,感觉再不回顾下可能就要彻底忘记了,准备做一个后台管理项目练练手, ...
- python 数组格式转换
格式转换 arr1 = [ {'name': 'jack', 'hobby': '西瓜'}, {'name': 'jack', 'hobby': '冬瓜'}, {'name': 'rose', 'ho ...
- 初步自学Java小结
本周学习Java使我印象最深刻的Java开发环境的安装与设置,通过下载Eclipse IDE for Java Developers初步搭建好了Java开发环境,之后利用视频了解了Java程序的类型及 ...
- 【翻译】浅析为何使用融合CDN是大趋势
使用传统CDN的用户遇到的新问题 随着云计算时代的快速发展,尤其是流媒体大视频时代的到来,用户在是使用过往CDN节点资源调配将面临很多问题: 问题1: 流媒体时代不局限于静态内容分发,直播点播等视频服 ...
- 继 “多闪”后“飞聊”再被diss?其实社交还能这么玩
近日头条低调上线了新的社交APP——飞聊,目前在AppStore社交排行榜第7位.但很多人使用了之后都觉得新产品的各个功能都让人想起其他的产品.兴趣小组让人想到豆瓣的兴趣小组,生活动态让人想到微博动态 ...
- 运筹学学报-运行问题之新版TeX系统支持修改
<运筹学学报>的LaTeX模板基本上是CCT的典型而且是停留在LaTeX2.09 的时代,故而很多用户下载其模板无法在新TeX系统里使用,这里提供以下解决方案.源文件中的前几行:\docu ...
- 在已部署好的docker环境下配置nginx项目路径
第一步:申请一个docker连接账号,可以借用putty工具,如果使用sublime,可以下载sftp插件,上传.下载来同步你线上线下的文件: 第二步:修改nginx区域配置文件,在conf文件夹里放 ...