吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习随机森林RandomForestClassifier分类模型
def test_RandomForestClassifier(*data):
X_train,X_test,y_train,y_test=data
clf=ensemble.RandomForestClassifier()
clf.fit(X_train,y_train)
print("Traing Score:%f"%clf.score(X_train,y_train))
print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_RandomForestClassifier
test_RandomForestClassifier(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_num(*data):
'''
测试 RandomForestClassifier 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,100,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
clf=ensemble.RandomForestClassifier(n_estimators=num)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_num
test_RandomForestClassifier_num(X_train,X_test,y_train,y_test)

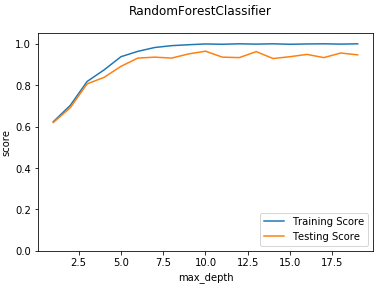
def test_RandomForestClassifier_max_depth(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=range(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_depth in maxdepths:
clf=ensemble.RandomForestClassifier(max_depth=max_depth)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_depth
test_RandomForestClassifier_max_depth(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_max_features(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
max_features=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_feature in max_features:
clf=ensemble.RandomForestClassifier(max_features=max_feature)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Testing Score")
ax.set_xlabel("max_feature")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_features
test_RandomForestClassifier_max_features(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- sqli-labs1-10基础掌握
00x01基于错误的GET单引号字符型注入 首先and 1=2判断是否为数值型sql注入,页面正常,不是 然后’测试,发现页面报sql语句错误,存在字符型sql注入 猜测参数为单引号闭合,用注释语句 ...
- 假期学习【四】RDD编程实验一
1.今天把Spark编程第三个实验的Scala独立程序编程写完了.使用 sbt 打包 Scala 程序,然后提交到Spark运行. 2.完成了实验四的第一项 (1)该系总共有多少学生: map(t ...
- 微信小程序判断input是否为空
微信小程序中用到input值时候,判断其内容是否为空,可以用if-else判断内容的length,也可以给input加点击事件,判断其内容:以下是我解决问题的过程wxml代码 <view cla ...
- 开放系统互联(OSI)模型
开放系统互联(OSI)模型 是由国际标准化组织(ISO)于1984年提出的一种标准参考模型,是一种关于由不同供应商提供的不同设备和应用软件之间的网络通信的概念性框架结构.它被公认为是计算机通信和 in ...
- jQuery---版本问题
jQuery的版本 官网下载地址:http://jquery.com/download/ jQuery版本有很多,分为1.x 2.x 3.x 大版本分类: 1.x版本:能够兼容IE678浏览器 2.x ...
- Java中new一个子类对象的同时并不会自动创建一个父类对象
首先重申一个概念:子类会继承父类所有非私有成员变量和方法,包括父类的构造方法 当创建一个子类对象时,首先开辟内存,然后调用类的构造函数,这里的构造函数由两部分组成,一部分是从父类继承而来的父类的构造方 ...
- B - 青蛙的约会
两只青蛙在网上相识了,它们聊得很开心,于是觉得很有必要见一面. 它们很高兴地发现它们住在同一条纬度线上,于是它们约定各自朝西跳,直到碰面为止. 可是它们出发之前忘记了一件很重要的事情,既没有问清楚对方 ...
- Tp5整理
一.命名规则 目录级和文件命名 目录采用小写字母+下划线命名: 类文件名采用驼峰法命名(比如:ArticleDetail.php),其它文件与目录命名规则同: 类名与类文件名须保持一致,采用驼峰法: ...
- ubuntu19.04 配置远程连接ssh
安装ssh-server sudo apt install openssh-server 参照:https://baijiahao.baidu.com/s?id=1631505486531979316 ...
- Python之旅第二天(第一天补充部分、数据类型、运算逻辑、部分方法的引入、pycharm)
今天其实是有点小忙的,但是干自己不喜欢事情的结果就是,要睡觉了都不知道自己在忙鸡毛,所以还是不继续想了,脑仁疼.回忆一下今天的学习内容,着实有点少,本大侠还没怎么过瘾呢.废话不多说. while补充两 ...