吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_regression():
'''
加载用于回归问题的数据集
'''
#使用 scikit-learn 自带的一个糖尿病病人的数据集
diabetes = datasets.load_diabetes()
# 拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #集成学习随机森林RandomForestRegressor回归模型
def test_RandomForestRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=ensemble.RandomForestRegressor()
regr.fit(X_train,y_train)
print("Traing Score:%f"%regr.score(X_train,y_train))
print("Testing Score:%f"%regr.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_regression()
# 调用 test_RandomForestRegressor
test_RandomForestRegressor(X_train,X_test,y_train,y_test)
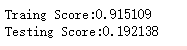
def test_RandomForestRegressor_num(*data):
'''
测试 RandomForestRegressor 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,100,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.RandomForestRegressor(n_estimators=num)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1)
plt.suptitle("RandomForestRegressor")
plt.show() # 调用 test_RandomForestRegressor_num
test_RandomForestRegressor_num(X_train,X_test,y_train,y_test)
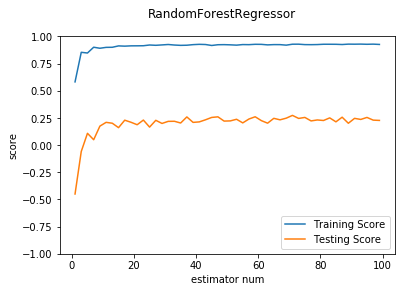
def test_RandomForestRegressor_max_depth(*data):
'''
测试 RandomForestRegressor 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=range(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_depth in maxdepths:
regr=ensemble.RandomForestRegressor(max_depth=max_depth)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestRegressor")
plt.show() # 调用 test_RandomForestRegressor_max_depth
test_RandomForestRegressor_max_depth(X_train,X_test,y_train,y_test)
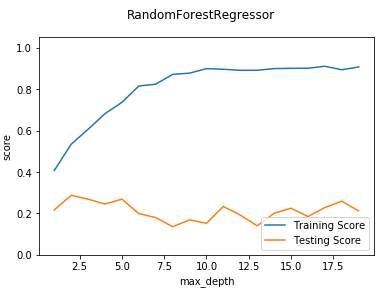
def test_RandomForestRegressor_max_features(*data):
'''
测试 RandomForestRegressor 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
max_features=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_feature in max_features:
regr=ensemble.RandomForestRegressor(max_features=max_feature)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Testing Score")
ax.set_xlabel("max_feature")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestRegressor")
plt.show() # 调用 test_RandomForestRegressor_max_features
test_RandomForestRegressor_max_features(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- linux 安装 setuptools
wget --no-check-certificate https://pypi.python.org/packages/source/s/setuptools/setuptools-19.6.tar ...
- [LGR-054]洛谷10月月赛II
浏览器 结论popcnt(x^y)和popcnt(x)+popcnt(y)的奇偶性相同. 然后就是popcnt为奇数的乘为偶数的.预处理一下\(2^{16}\)次方以内的popcnt,直接\(O(1) ...
- Eclipse的Errors in required projec(s)问题
在Eclipse中运行代码时出现Errors exist in required project(s)弹窗提示,但是当前类并无错误,点击Proceed当前类仍然可以运行 错误展示: Errors ex ...
- MySQL 8.0.18 在 Windows Server 2019 上的安装(ZIP)公开
AskScuti MySQL : Windows Server 2019 安装 MySQL 8.0 温馨提示:为了展现我最“魅力”的一面,请用谷歌浏览器撩我. 一切就绪,点我开撩
- 04-Java基础语法【IDEA、方法】
重要内容记录: 01.IDE介绍 IDE(Integarted Development Environment)是Java集成开发环境,是一种专门用来提高Java开发效率的软件. 免费的IDE:Ecl ...
- vscode与MinGW64调试c++报错
这个问题在刚配好环境测试的时候往往不会被发现,因为单纯的c++编译调试是没问题的.但一旦调试使用stl库的代码就会报错,而编译又没问题且可以正常运行,但在vscode的集成终端里运行不会显示任何本该显 ...
- SpringBoot 测试基类
每次写单元测试都要重复写一些方法.注解等,这里我写了一下测试的基类 (1) 记录测试方法运行的时间 (2)两个父类方法 print,可打印list和object对象 (3)一个属性 logger 记录 ...
- PHP 把秒数转为时分秒格式
PHP函数 1.gmdate $seconds = 174940;$hours = intval($seconds/); $time1 = $hours."小时".gmdate(' ...
- 动态规划 ---- 最长公共子序列(Longest Common Subsequence, LCS)
分析: 完整代码: // 最长公共子序列 #include <stdio.h> #include <algorithm> using namespace std; ; char ...
- shell内置命令和外部命令的区别
内部命令实际上是shell程序的一部分,其中包含的是一些比较简单的linux系统命令,这些命令由shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留 ...