Tesseract-OCR-v5.0中文识别,训练自定义字库,提高图片的识别效果
1,下载安装Tesseract-OCR 安装,链接地址https://digi.bib.uni-mannheim.de/tesseract/

2,安装成功 tesseract -v
注意:安装后,要添加系统环境变量
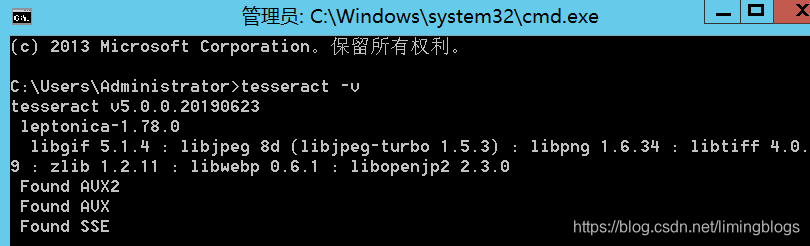
3,cmd指定目录到 cd C:\Work\BlogsTest\TestPic,要识别图片的文件夹 识别:tesseract test.png result -l chi_sim
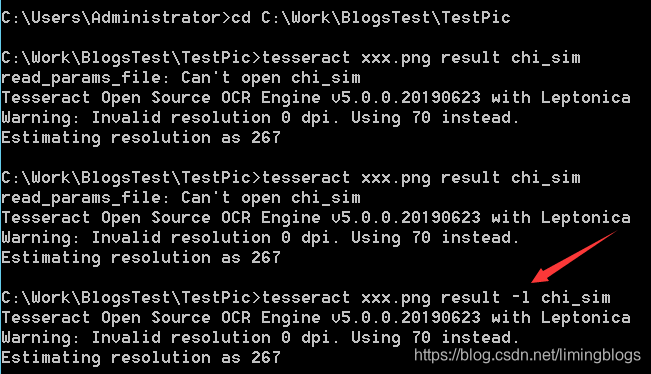
识别成功的效果,result.txt文件会自动生成
要注意:Tesseract-OCR的安装目录要包含识别中文的字符集chi_sim.traineddata,可以在GitHub下载https://github.com/tesseract-ocr/tessdata
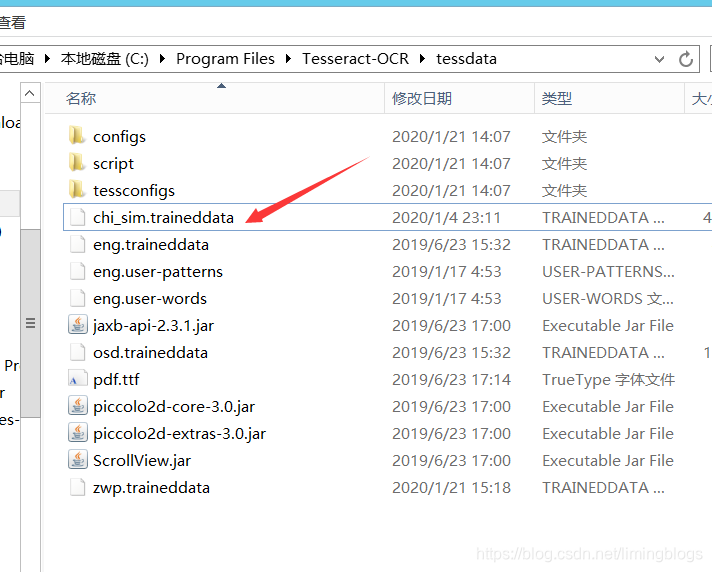
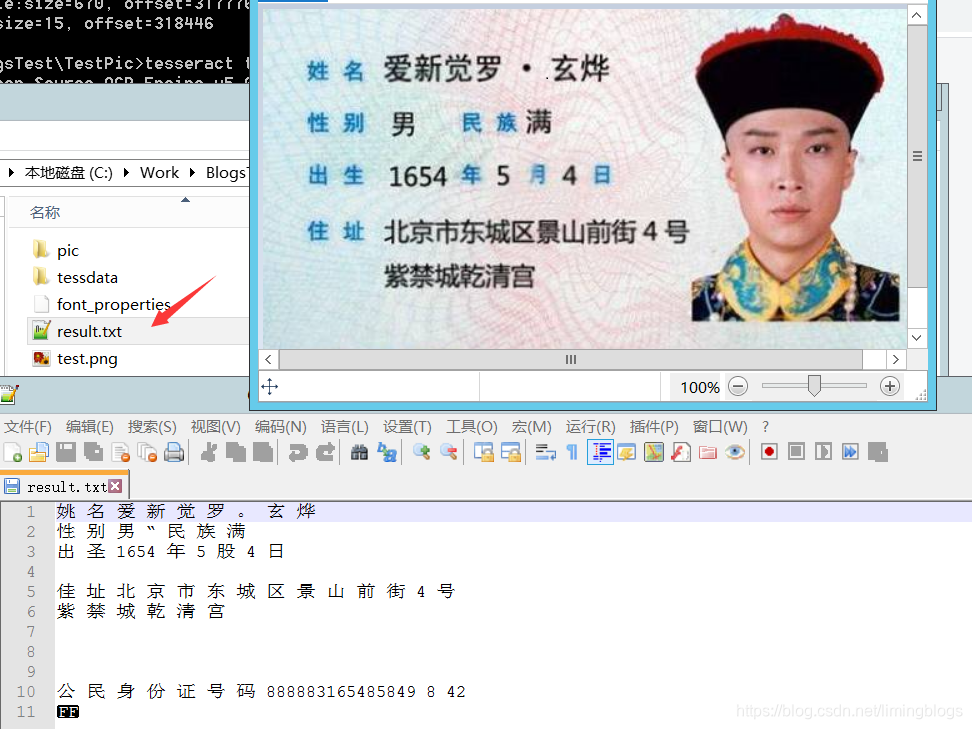
4,可见第3步的识别效果不是很好,想到通过训练自定义字库,提高图片的识别效果
(0)下载安装jTessBoxEditor,https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
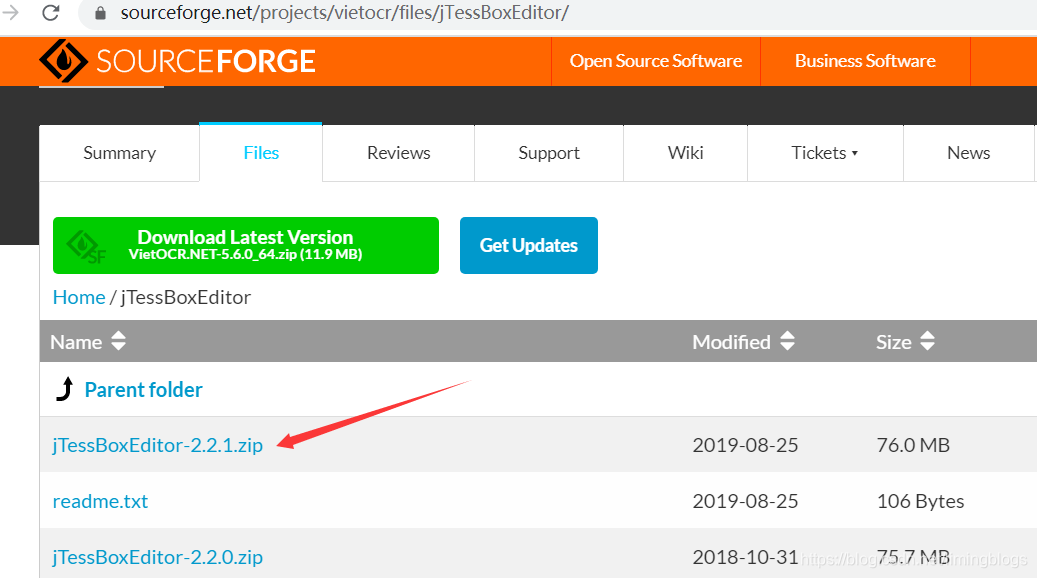
注意要安装JavaRuntime
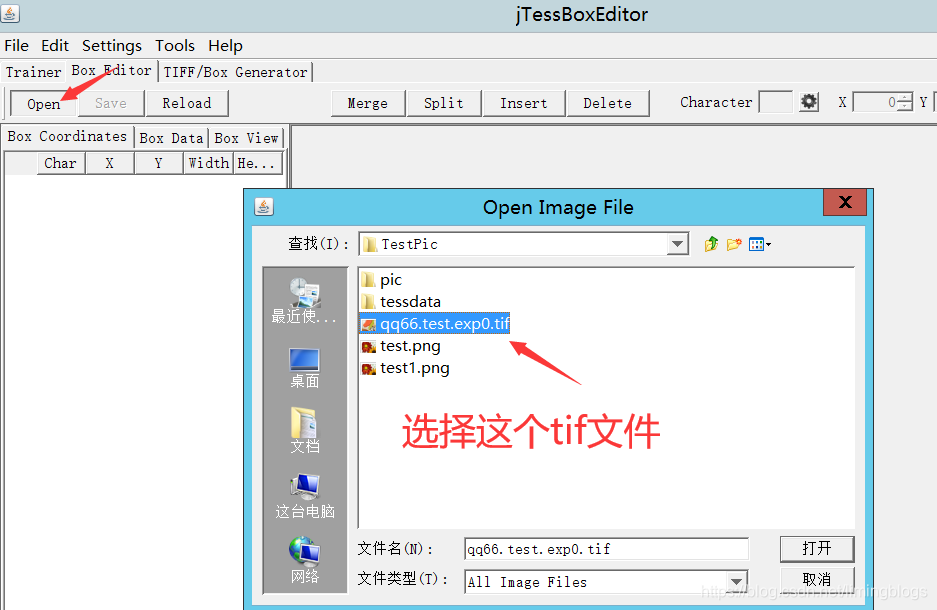
(1)打开jTessBoxEditor,选择Tools->Merge TIFF,进入训练样本所在文件夹,选中要参与训练的样本图片:
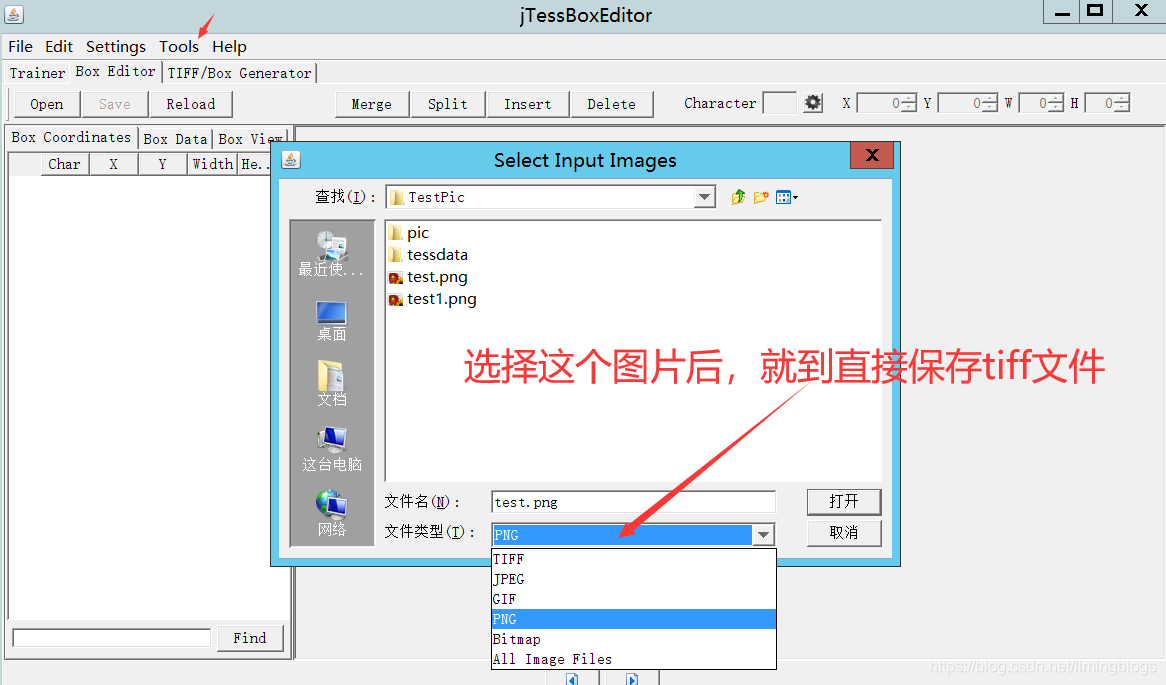
(2)点击 “打开” 后弹出保存对话框,选择保存在当前路径下,文件命名为 “qq66.test.exp0.tif” ,格式只有一种 “TIFF” 可选。
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言,fontname是字体,num为自定义数字。
比如我们要训练自定义字库 qq66,字体名test,那么我们把图片文件命名为 qq66.test.exp0.tif
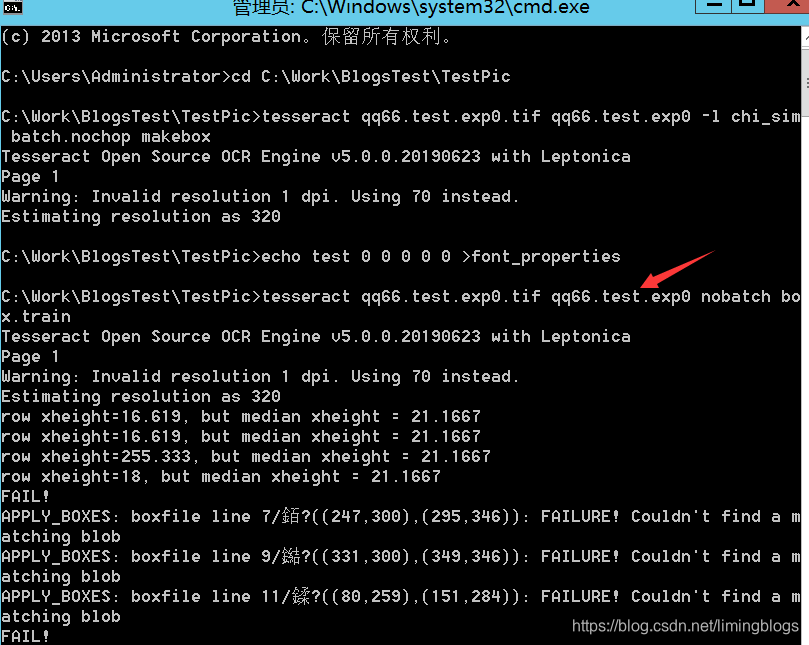
(3)使用tesseract生成.box文件
tesseract qq66.test.exp0.tif qq66.test.exp0 -l chi_sim --psm 6 batch.nochop makebox
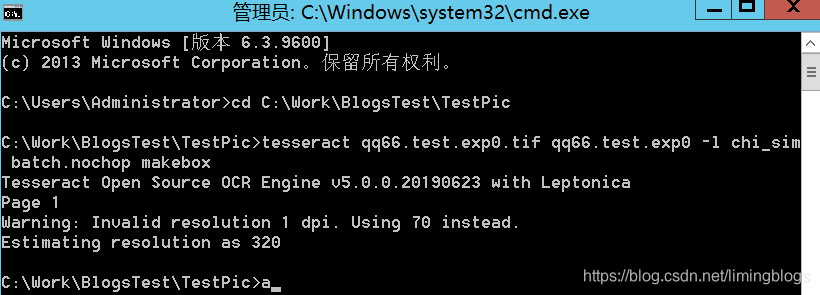
注意:--psm的语法,数字对应不同的 页面分割模式。
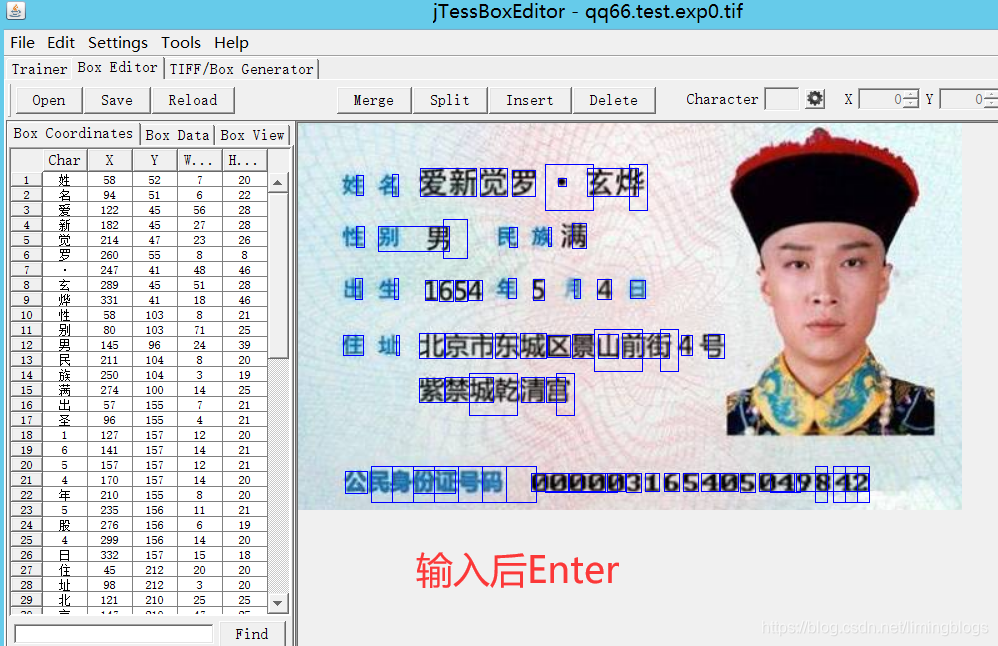
(4)使用jTessBoxEditor矫正.box文件的错误
打开后矫正后,点击 save
(5)生成font_properties文件:(该文件没有后缀名)
执行命令,执行完之后,会在当前目录生成font_properties文件
echo test 0 0 0 0 0 >font_properties
也可以手工新建一个名为font_properties的文本文件,输入内容 “test 0 0 0 0 0” 表示字体test的粗体、倾斜等共计5个属性。这里的“test”必须与“qq66.test.exp0.box”中的“test”名称一致。
(6)使用tesseract生成.tr训练文件
执行下面命令,执行完之后,会在当前目录生成qq66.test.exp0.tr文件。
tesseract qq66.test.exp0.tif qq66.test.exp0 nobatch box.train
(7)生成字符集文件:
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
unicharset_extractor qq66.test.exp0.box
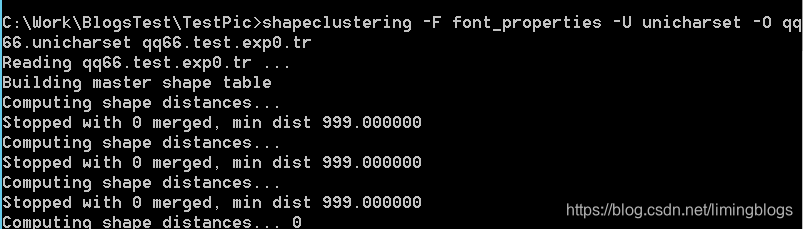
(8)生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和 zwp.unicharset 两个文件。
shapeclustering -F font_properties -U unicharset -O qq66.unicharset qq66.test.exp0.tr
(8)生成聚字符特征文件
执行下面命令,会生成 inttemp、pffmtable、shapetable和zwp.unicharset四个文件。
mftraining -F font_properties -U unicharset -O qq66.unicharset qq66.test.exp0.tr
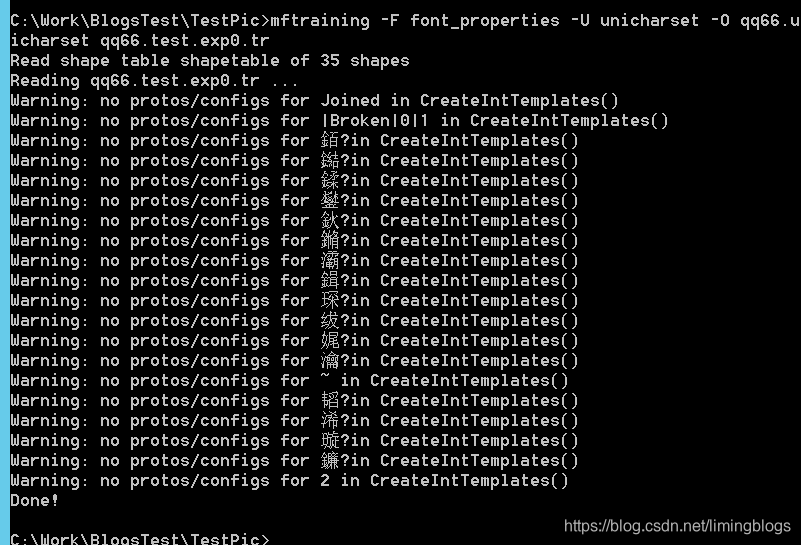
(9)生成字符正常化特征文件
执行下面命令,会生成 normproto 文件。
cntraining qq66.test.exp0.tr

(10)文件重命名
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为qq66.inttemp、qq66.pffmtable、qq66.shapetable和qq66.normproto
(11)合并训练文件
执行下面命令,会生成qq66.traineddata文件。
combine_tessdata qq66.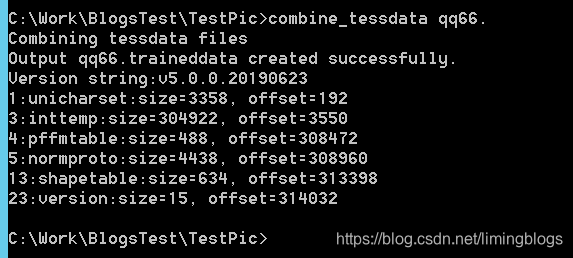
最后文件目录
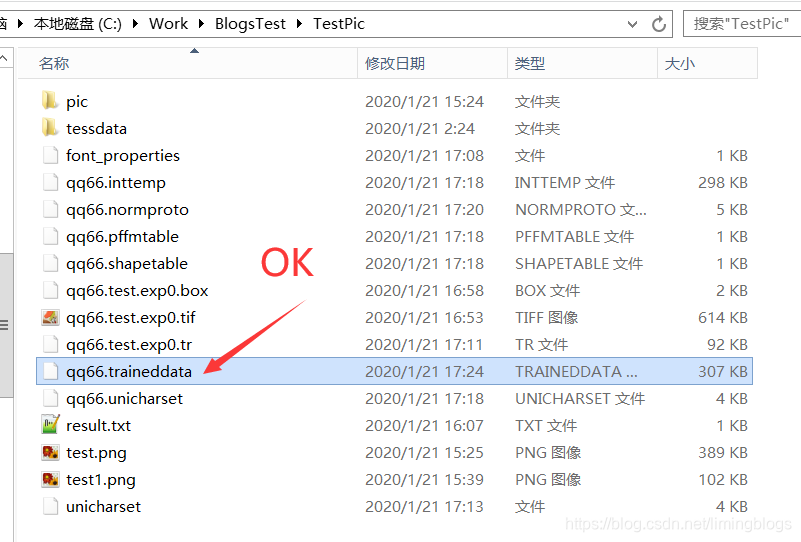
5,用新生成的qq66.traineddata字符集,重新识别身份证
6,可以同时选择多个不同的样本生成box文件

7,在原有训练数据的基础上,加入新的字符训练信息
经研究找到实用合并方法(红色部分为示例,实际应为你自己生成的文件名):
在新的训练数据生成.box 和.tr文件后,
生成字符集 unicharset_extractor add.font.exp0.box new.font.exp0.box
合并训练数据(.tr)
mftraining -F font_properties -U unicharset -O added.unicharset add.font.exp0.tr new.font.exp0.tr
聚合所有的tr文件:
cntraining add.font.exp0.tr new.font.exp0.tr
8,设置图片分割模式
Page segmentation modes:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
例如:
tesseract test.png result -l chi_sim -psm 7 nobatch

Tesseract-OCR-v5.0中文识别,训练自定义字库,提高图片的识别效果的更多相关文章
- 【Python项目】使用Face++的人脸识别detect API进行本地图片情绪识别并存入excel
准备工作 首先,需要在Face++的主页注册一个账号,在控制台去获取API Key和API Secret. 然后在本地文件夹准备好要进行情绪识别的图片/相片. 代码 介绍下所使用的第三方库 ——url ...
- Yii2.0中文开发向导——自定义日志文件写日志
头部引入log类use yii\log\FileTarget; $time = microtime(true);$log = new FileTarget();$log->logFile = Y ...
- 第二十三节:scrapy爬虫识别验证码(二)图片验证码识别
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码. 例如:知网的注册就有图片验证码 首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码ur ...
- pytesseract在识别只有一个数字的图片时识别不出来
大家好,近期在做自动化测试时,遇到了一个问题需要通过识别图片来实现,遂用到了pytesseract模块和tesseract-ocr这个工具.在使用过程中发现,识别带有数字的图片时,如果这个图片上仅有一 ...
- Tesseract-OCR4.0识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- Tesseract-OCR识别中文与训练字库
转自:https://www.cnblogs.com/lcawen/articles/7040005.html 关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试 ...
- Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
随机推荐
- linux 处理器特定的寄存器
如果你需要测量非常短时间间隔, 或者你需要非常高精度, 你可以借助平台依赖的资源, 一个要精度不要移植性的选择. 在现代处理器中, 对于经验性能数字的迫切需求被大部分 CPU 设计中内在的指令定时不 ...
- 【HTML/CSS】BFC
块格式化上下文(Block formatting contexts) BFC是什么? 是Web页面中盒模型布局的CSS渲染模式.它的定位体系属于常规文档流. 至少满足条件之一: float 的值不为 ...
- ZR并查集专题
ZR并查集专题 并查集,作为一个基础算法,对于初学者来说,下面的代码是维护连通性的利器 return fa[x] == x ? x : fa[x] = getf(fa[x]); 所以,但是这对并查集的 ...
- [数论] hdu 5974 A Simple Math Problem (数论gcd)
传送门 •题意 一直整数$a,b$,有 $\left\{\begin{matrix}x+y=a\\ LCM(x*y)=b \end{matrix}\right.$ 求$x,y$ •思路 解题重点:若$ ...
- dotnet core 隐藏控制台
如果写一个控制台程序,需要隐藏这个控制台程序,可以使用本文的方法 如果是在 Windows 下运行, 可以使用一些系统提供的方法隐藏控制台.如果是 Linux 下,都是控制台,就不用隐藏了 复制下面的 ...
- How to use code to exit the application in UWP
I will tell you how to exit the application in UWP by the code. We can call some static method to he ...
- 【Linux】centos查看防火墙是否关闭
查看防火墙的状态的命令为: sudo systemctl status firewalld 打开防火墙的方式有两种,一种是打开后重启会恢复回原来的状态,命令为: sudo systemctl star ...
- HRegion 分配与寻址
1.Region 分配 HMaster负责为Region 分配Region Server,一个Region 只能分配给一个Region server. HMaster中 记录: 哪些Regio ...
- DEVOPS技术实践_11:Jenkins集成Sonar
前言 前面已经有介绍sonar的安装,简单应用,下面在简答的研究一下sonar和jenkins集成的简单使用,对于sonar的安装不做介绍 一 sonar的简单介绍 持续检查避免了低质量的代码,比如S ...
- C# async await 死锁问题总结
可能发生死锁的程序类型 1.WPF/WinForm程序 2.asp.net (不包括asp.net mvc)程序 死锁的产生原理 对异步方法返回的Task调用Wait()或访问Result属性时,可能 ...