利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题
案例代码:
# __author : "J"
# date : 2018-03-06 # 导入需要用到的库文件
import urllib.request
import re
import pymysql # 创建一个类用于获取学校官网的十条标题
class GetNewsTitle: # 构造函数 初始化
def __init__(self):
self.request = urllib.request.Request("http://www.sict.edu.cn/") # 需要爬取的网址
# 利用正则表达式筛选数据
self.my_re = re.compile(
r'学校要闻.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'院部简讯') # 创建一个方法
def get_html(self):
try:
response = urllib.request.urlopen(self.request)
# 获取目标网页源码
my_html = response.read().decode('GB2312').replace("\r\n", "")
return my_html
except urllib.request.HTTPError as e:
print(e.code)
print(e.reason)
return # 创建一个函数,利用正则获取指定标题
def get_titles(self, my_html):
news_titles = re.findall(self.my_re, my_html)
return news_titles # 创建一个方法,把获取到的标题存入mysql数据库
def into_mysql(self, titles):
for num in range(10):
connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', db='school',
charset='utf8')
cursor = connection.cursor()
sql = "INSERT INTO `newsTitles` (`title`) VALUES ('" + titles[0][num] + "')"
cursor.execute(sql)
connection.commit()
cursor.close()
connection.close() # 执行函数的入口
def start(self):
self.into_mysql(self.get_titles(self.get_html()))
print("存储成功!") # 实例化类
s = GetNewsTitle()
# 调用方法开始执行
s.start()
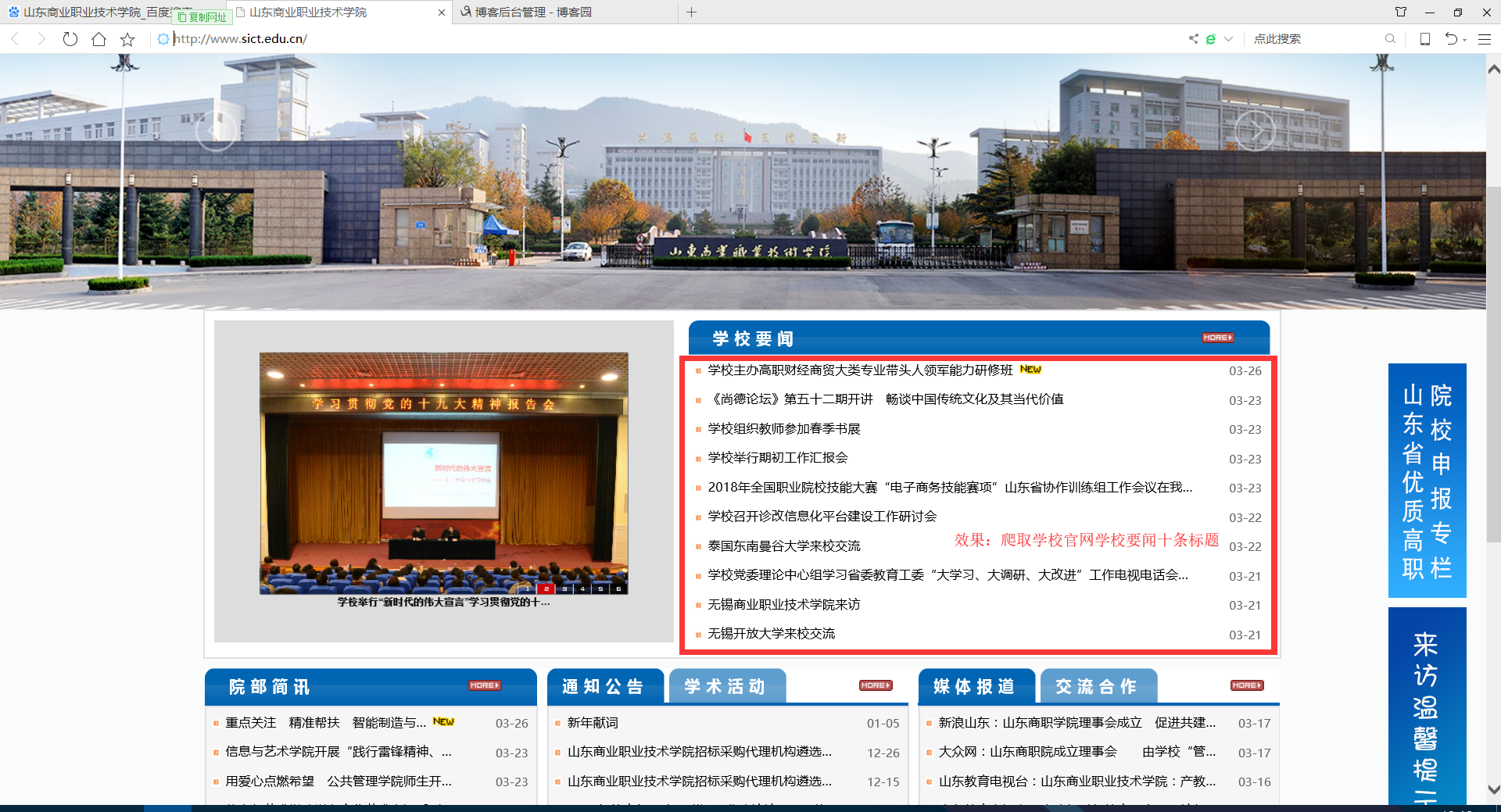
效果:

利用Python网络爬虫爬取学校官网十条标题的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
随机推荐
- HDU 3903 Trigonometric Function(数学定理)
Trigonometric Function Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 125536/65536 K (Java/Oth ...
- MySQL在windows下的noinstall安装
1.解压mysql zip软件包 2.配置环境变量 3.修改配置文件my_default.ini添加如下: [mysqld] basedir=D:\MySQL\MySQL Server 5.6(mys ...
- go语言编程入门
查看文档 首先先分享一个可以在本地就能查看文档的骚操作(linux系统) 1.打开命令行终端,输入godoc -http=:8000,如果想后台运行在后面加个& 2.然后打开浏览器,输入网址: ...
- PL/SQL常用表达式及举例(一)
IF 判断条件 THEN 满足条件时执行语句 END IF; DECLARE v_countResult NUMBER; BEGIN SELECT COUNT(empno) INTO v_countR ...
- 2018/03/15 每日一个Linux命令 之 mv
Linux mv命令用来为文件或目录改名.或将文件或目录移入其它位置. mv [参数] [要移动/更名的文件] [移动路径/要更改名字] 平常用的很多了,这里就不多讲解了,只介绍两个重要参数就好了 - ...
- .NET基于分页控件实现真分页功能
下面利用分页控件实现分页功能.分页控件下载网址:http://www.webdiyer.com/ 从该网址下载AspNetPager.dll后,在VS2008中在工具箱中,右键 —> 选择项 — ...
- 004-spring cloud gateway-网关请求处理过程
一.网关请求处理过程 客户端向Spring Cloud Gateway发出请求.如果网关处理程序映射确定请求与路由匹配,则将其发送到网关Web处理程序.此处理程序运行通过特定于请求的过滤器链发送请求. ...
- Spark2.x学习笔记:Spark SQL程序设计
1.RDD的局限性 RDD仅表示数据集,RDD没有元数据,也就是说没有字段语义定义. RDD需要用户自己优化程序,对程序员要求较高. 从不同数据源读取数据相对困难. 合并多个数据源中的数据也较困难. ...
- Py之np.concatenate函数【转载】
转自:https://docs.scipy.org/doc/numpy/reference/generated/numpy.concatenate.html 1.nupmy.concatenate函数 ...
- Mybatis的多对多映射
一.Mybatis的多对多映射 本例讲述使用mybatis开发过程中常见的多对多映射查询案例.只抽取关键代码和mapper文件中的关键sql和配置,详细的工程搭建和Mybatis详细的流程代码可参见& ...