第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
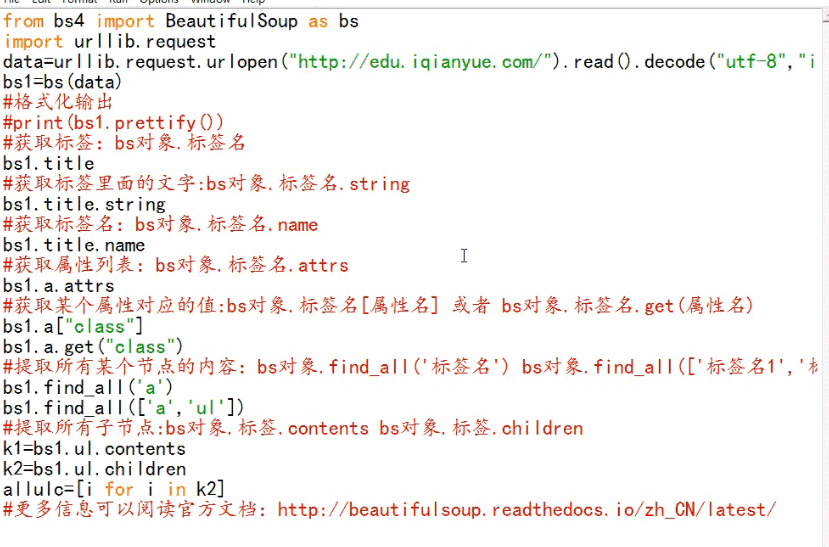
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础的更多相关文章
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- Java中使用Oracle的客户端 load data和sqlldr命令执行数据导入到数据库中
Windows环境下测试代码: import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundExcep ...
- linux命令(53):用户和用户组
Linux 用户和用户组详细解说 本文主要讲述在Linux 系统中用户(user)和用户组(group)管理相应的概念: 用户(user)和用户组(group)相关命令的列举: 其中也对单用户多任务, ...
- ZooKeeper学习之文件系统的布局和格式
本文来谈谈快照文件,事务日志文件在文件系统中是如何存放的. 写事务日志是事务处理的关键步骤,所以高度建议在一个独立的磁盘上存储.快照不需要在独立的磁盘存储,因为它们是由一个后台线程以懒汉式的(lazi ...
- 【delphi】delphi操作sqlite3
SQLite SQLite是一个老牌的轻量级别的本地文件数据库,完全免费且开源,不需要安装,无须任何配置,当然,这样管理功能就不是很强大了,但是它的主要应用也是在本地数据库,可以说是最简单好用的嵌入式 ...
- 远程mysql导入本地文件
远程mysql导入本地文件 登陆数据库 mysql --local-infile -h<IP> -u<USR> -p 选择数据库 USE xxx 导入文件 LOAD DATA ...
- golang标准库分析之net/rpc
net/rpc是golang提供的一个实现rpc的标准库.
- Spring Boot(三):RestTemplate提交表单数据的三种方法
http://blog.csdn.net/yiifaa/article/details/77939282 ********************************************** ...
- 利用 fdisk进行分区
):fdisk命令参数 p:打印分区表. n:新建一个新分区. d:删除一个新分区. q:退出不保存. w:退出且保存. 例子: 先看下磁盘: root@archiso ~ # lsblk 在这里对磁 ...
- python获取软件安装列表2222
softer_installed_list ===================== 使用python编写的,获取本机软件安装列表,输出为html表格. * win7 32位环境下运行 * 使用的是 ...
- 获取linux内核的配置项(包含模块module)_转
转自:提取已有的内核配置文件 由于有时候所做的内核配置文件需要移植到其他的内核源码中,此时又忘了保存,这时以下方法就可以满足你了. 1.首先这两个配置的位于(init/Kconfig): 2. 如果要 ...