第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
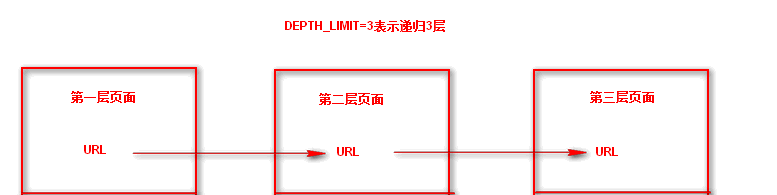
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 记录url可以是缓存,或者数据库,如果保存数据库按照以下方式: id URL加密 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第一百二十六节,JavaScript,XPath操作xml节点
第一百二十六节,JavaScript,XPath操作xml节点 学习要点: 1.IE中的XPath 2.W3C中的XPath 3.XPath跨浏览器兼容 XPath是一种节点查找手段,对比之前使用标准 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
随机推荐
- 菜鸟学Java(十五)——Java反射机制(二)
上一篇博文<菜鸟学编程(九)——Java反射机制(一)>里面,向大家介绍了什么是Java的反射机制,以及Java的反射机制有什么用.上一篇比较偏重理论,理论的东西给人讲出来总感觉虚无缥缈, ...
- 关于casperjs的wait方法的执行顺序
var casper = require('casper').create({ viewportSize:{ width:1920, height:1080 } }); var url1 = 'htt ...
- Spring Boot中扩展XML请求和响应的支持
在Spring Boot中,我们大多时候都只提到和用到了针对HTML和JSON格式的请求与响应处理.那么对于XML格式的请求要如何快速的在Controller中包装成对象,以及如何以XML的格式返回一 ...
- H3C交换机SNMP配置
1.启动/关闭SNMP Agent服务 在系统视图模式下: 启用:snmp-agent 关闭:undo snmp-agent 注:缺省情况下snmp agent是关闭的 2. 使能或禁止SNMP相应版 ...
- ParseUrl
#!/usr/bin/python # coding:utf-8 import re import urlparse # 解析url def ParseUrl(url): if not re.sear ...
- Oracle 报错:PLS-00201: 必须声明标识符
原因:调用其他用户的包或存储过程. 解决方法:在被调用的包或存储过程的用户下授权执行权限给调用用户: grant execute on 包名 to 用户名;
- 李炎恢的课程中心(JQUERY视频)
http://edu.51cto.com/lecturer/user_id-3987533-page-2.html
- python学习笔记十四:wxPython Demo
一.简介 wxPython是Python语言的一套优秀的GUI图形库,允许Python程序员很方便的创建完整的.功能键全的GUI用户界面. wxPython是作为优秀的跨平台GUI库wxWidgets ...
- Unity Shader学习资料
文本教程 http://www.cnblogs.com/polobymulberry/p/4314147.html 视频教程 http://www.sikiedu.com/my/course/37 冯 ...
- SHT30 Linux标准 i2c-dev 读取程序
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/sta ...