HBase —— 单机环境搭建
一、安装前置条件说明
1.1 JDK版本说明
HBase 需要依赖JDK环境,同时HBase 2.0+ 以上版本不再支持JDK 1.7 ,需要安装JDK 1.8+ 。JDK 安装方式见本仓库:
1.2 Standalone模式和伪集群模式的区别
- 在
Standalone模式下,所有守护进程都运行在一个jvm进程/实例中; - 在伪分布模式下,HBase仍然在单个主机上运行,但是每个守护进程(HMaster,HRegionServer 和 ZooKeeper)则分别作为一个单独的进程运行。
说明:两种模式任选其一进行部署即可,对于开发测试来说区别不大。
二、Standalone 模式
2.1 下载并解压
从官方网站下载所需要版本的二进制安装包,并进行解压:
# tar -zxvf hbase-2.1.4-bin.tar.gz
2.2 配置环境变量
# vim /etc/profile
添加环境变量:
export HBASE_HOME=/usr/app/hbase-2.1.4
export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量生效:
# source /etc/profile
2.3 进行HBase相关配置
修改安装目录下的conf/hbase-env.sh,指定JDK的安装路径:
# The java implementation to use. Java 1.8+ required.
export JAVA_HOME=/usr/java/jdk1.8.0_201
修改安装目录下的conf/hbase-site.xml,增加如下配置:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/hbase/rootdir</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zookeeper/dataDir</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
hbase.rootdir: 配置hbase数据的存储路径;
hbase.zookeeper.property.dataDir: 配置zookeeper数据的存储路径;
hbase.unsafe.stream.capability.enforce: 使用本地文件系统存储,不使用HDFS的情况下需要禁用此配置,设置为false。
2.4 启动HBase
由于已经将HBase的bin目录配置到环境变量,直接使用以下命令启动:
# start-hbase.sh
2.5 验证启动是否成功
验证方式一 :使用jps命令查看HMaster进程是否启动。
[root@hadoop001 hbase-2.1.4]# jps
16336 Jps
15500 HMaster
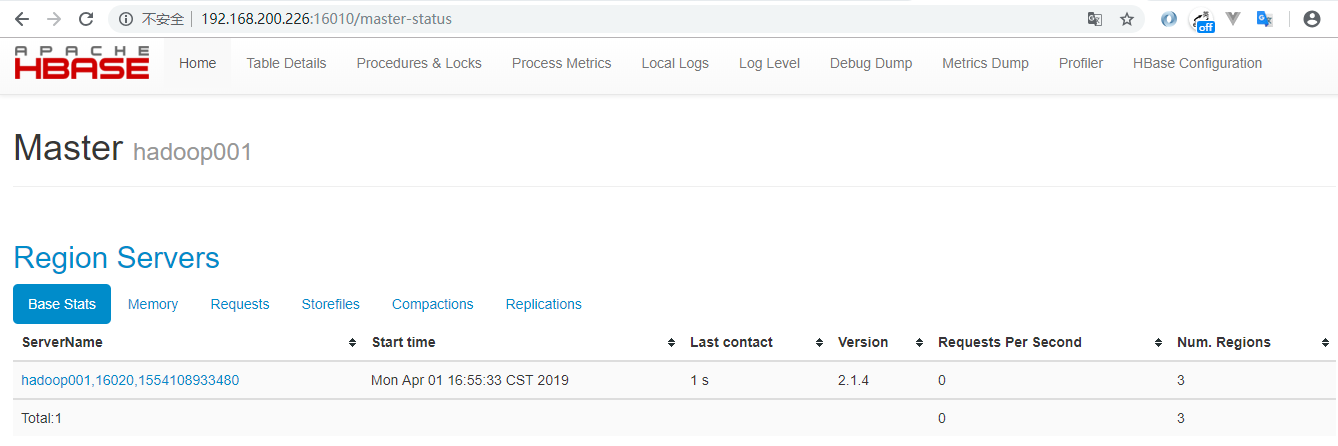
验证方式二 :访问HBaseWeb UI 页面,默认端口为16010 。
三、伪集群模式安装(Pseudo-Distributed)
3.1 Hadoop单机伪集群安装
这里我们采用HDFS作为HBase的存储方案,需要预先安装Hadoop。Hadoop的安装方式单独整理至:
3.2 Hbase版本选择
HBase的版本必须要与Hadoop的版本兼容,不然会出现各种Jar包冲突。这里我Hadoop安装的版本为hadoop-2.6.0-cdh5.15.2,为保持版本一致,选择的HBase版本为hbase-1.2.0-cdh5.15.2 。所有软件版本如下:
- Hadoop 版本: hadoop-2.6.0-cdh5.15.2
- HBase 版本: hbase-1.2.0-cdh5.15.2
- JDK 版本:JDK 1.8
3.3 软件下载解压
下载后进行解压,下载地址:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zxvf hbase-1.2.0-cdh5.15.2.tar.gz
3.4 配置环境变量
# vim /etc/profile
添加环境变量:
export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2
export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量生效:
# source /etc/profile
3.5 进行HBase相关配置
1.修改安装目录下的conf/hbase-env.sh,指定JDK的安装路径:
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/java/jdk1.8.0_201
2.修改安装目录下的conf/hbase-site.xml,增加如下配置(hadoop001为主机名):
<configuration>
<!--指定 HBase 以分布式模式运行-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定 HBase 数据存储路径为HDFS上的hbase目录,hbase目录不需要预先创建,程序会自动创建-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop001:8020/hbase</value>
</property>
<!--指定 zookeeper 数据的存储位置-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zookeeper/dataDir</value>
</property>
</configuration>
3.修改安装目录下的conf/regionservers,指定region servers的地址,修改后其内容如下:
hadoop001
3.6 启动
# bin/start-hbase.sh
3.7 验证启动是否成功
验证方式一 :使用jps命令查看进程。其中HMaster,HRegionServer是HBase的进程,HQuorumPeer是HBase内置的Zookeeper的进程,其余的为HDFS和YARN的进程。
[root@hadoop001 conf]# jps
28688 NodeManager
25824 GradleDaemon
10177 Jps
22083 HRegionServer
20534 DataNode
20807 SecondaryNameNode
18744 Main
20411 NameNode
21851 HQuorumPeer
28573 ResourceManager
21933 HMaster
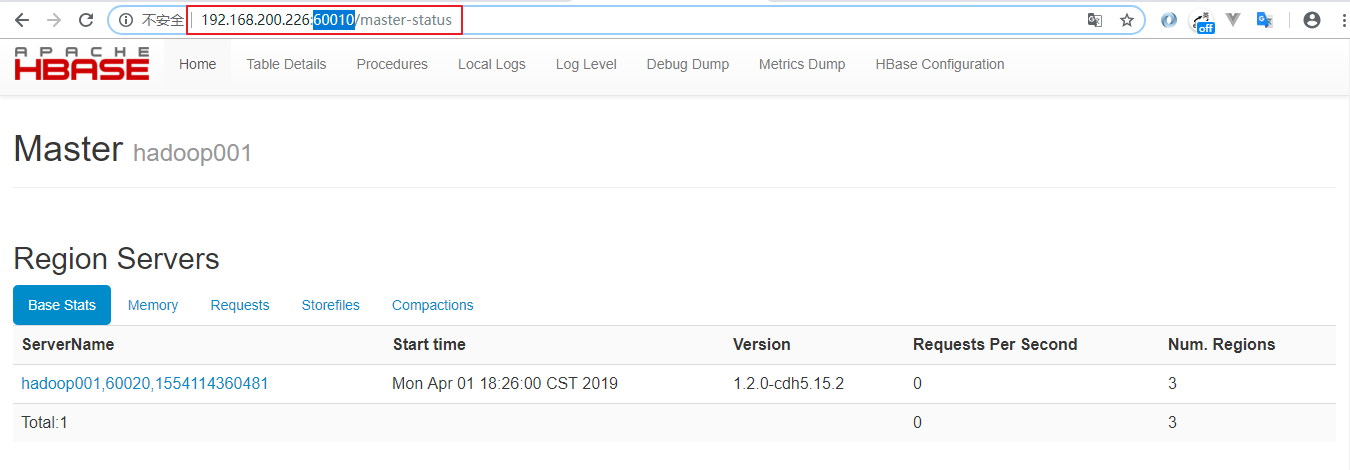
验证方式二 :访问HBase Web UI 界面,需要注意的是1.2 版本的HBase的访问端口为60010
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
HBase —— 单机环境搭建的更多相关文章
- HBase单机环境搭建
在搭建HBase单机环境之前,首先你要保证你已经搭建好Java环境: $ java -version java version "1.8.0_51" Java(TM) SE Run ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- Kafka 0.7.2 单机环境搭建
Kafka 0.7.2 单机环境搭建当下载完Kafka后,进行解压,其目录结构如下: bin config contrib core DISCLAIMER examples lib lib_manag ...
- kafka单机环境搭建及其基本使用
最近在搞kettle整合kafka producer插件,于是自己搭建了一套单机的kafka环境,以便用于测试.现整理如下的笔记,发上来和大家分享.后续还会有kafka的研究笔记,依然会与大家分享! ...
- hadoop2.6.2+hbase+zookeeper环境搭建
1.hadoop环境搭建,版本:2.6.2,参考:http://www.cnblogs.com/bookwed/p/5251393.html 启动服务:在master机器上,进入hadoop安装目录, ...
- Hadoop —— 单机环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- win10+pyspark+pycharm+anaconda单机环境搭建
一.工具准备 1. jdk1.8 2. scala 3. anaconda3 4. spark-2.3.1-bin-hadoop2.7 5. hadoop-2.8.3 6. winutils 7. p ...
随机推荐
- 自定义WPF 窗口样式
原文:自定义WPF 窗口样式 Normal 0 false 7.8 pt 0 2 false false false EN-US ZH-CN X-NONE 自定义 Window 在客户端程序中,经常需 ...
- 新建py文件时取名千万要小心 不要和已有模块重名
这是因为我新建了一个email.py的文件 后来我将文件名rename成了myemail.py没有看改名提示,结果导致所有的对email的import和调用全部改成了对myemail的import和调 ...
- readline库的使用
接口十分简单,readline和addhistory: #include <stdlib.h> #include <stdio.h> #include <unistd.h ...
- matlab 矢量化编程(一)—— 计算 AUC
AUC = sum( (Y(2:end)+Y(1:end-1))/2 .* (X(2:end) - X(1:end-1)) X 和 Y 均是向量: Y(2:end) - Y(1:end-1),是 Y( ...
- matlab 二元函数的画法
plot:画线(curve,二维空间以及三维空间) surf:画面(surface,一般在三维空间) 1. surf 绘图函数 surf 是 surface 的缩写,表示表面(显然至少三维图像才会有表 ...
- PL/SQL 异常处理程序
异常处理程序 一个好的程序应该能够妥善处理各种错误情况,并尽可能从错误中恢复.ORACLE 提供异常(EXCEPTION)和异常处理(EXCEPTION HANDLER)错误处理 ①有三种类型的 ...
- 算法 Tricks(六)—— 判断一个数是否为完全平方数
int(sqrt(n)) * int(sqrt(n)) == n ? 1:0; matlab 下判断一个数是否能开方的判断是: floor(sqrt(m))^2 == m
- TemplatePart用法说明
原文:TemplatePart用法说明 TemplatePart(Name="PART_Decrease", Type=typeof(RepeatButton)) 一直没明白这是干 ...
- IOS开发之把 Array 和 Dictionaries 序列化成 JSON 对象
1 前言通过 NSJSONSerialization 这个类的 dataWithJSONObject:options:error:方法来实现,Array 和 dictionary 序列化成 JSON ...
- Visual C++ 编译器自动假定带 .C 扩展名的文件是 C 文件而不是 C++ 文件,并且拒绝 C++ 语法和关键字(c语言只能在大括号最前面申明变量)
今天在编译OpenGL红宝书附带源码中的light.c文件时遇到一个诡异的问题: 如图light .c,在不做任何修改的情况编译OK.然而只要在某些地方写了可执行代码,则会无法通过编译器编译! (这几 ...