初始kafka
kafka
简介
Kafka是Linkedin于2010年12月份开源的消息系统
一种分布式的、基于发布/订阅的消息系统 ,另外提供数据分布式缓存功能
特点
消息持久化:通过O(1)的磁盘数据结构提供数据的持久化
高吞吐量:每秒百万级的消息读写
分布式:扩展能力强
多客户端支持:java、php、python、c++ ……
实时性:生产者生产的message立即被消费者可见
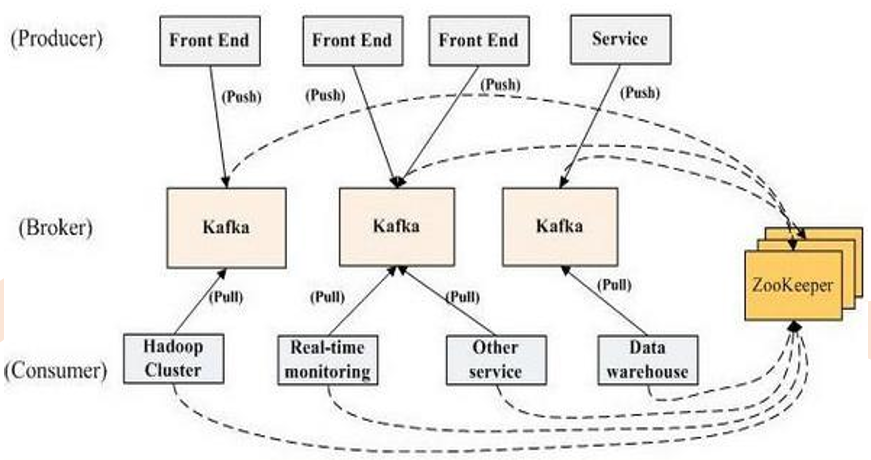
基本组件
Broker:每一台机器叫一个Broker
Producer:日志消息生产者,用来写数据
Consumer:消息的消费者,用来读数据
Topic:是一个虚拟概念,不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写
Partition:是一个实际的概念,以文件夹的形式存在,在Topic基础上做了进一步区分分层
Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
负载均衡:将Topic分成多个分区(Partition),每个Broker存储一个或多个Partition
多个Producer和Consumer同时生产和消费消息
Topic
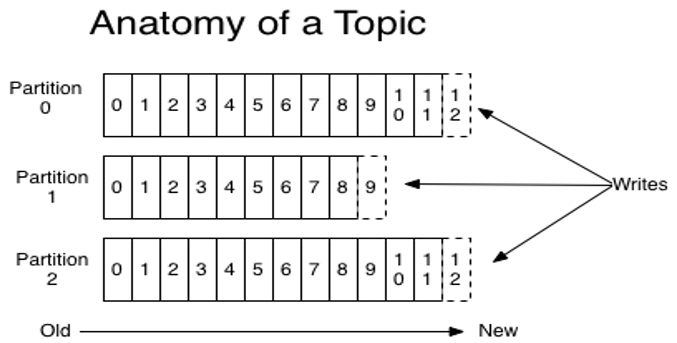
一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志, 每个分区都是有顺序且不变的消息序列
commit的log可以不断追加。消息在每个分区中都分配了一个叫offset的id序列 来唯一识别分区中的消息
一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志, 每个分区都是有顺序且不变的消息序列
commit的log可以不断追加。消息在每个分区中都分配了一个叫offset的id序列 来唯一识别分区中的消息。
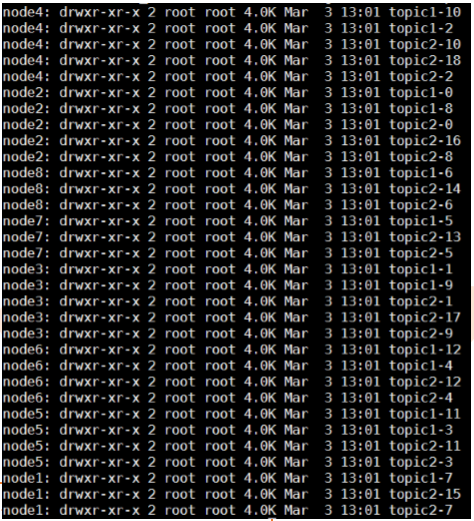
举例:若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集 群上会相应会生成共32个文件夹
无论发布的消息是否被消费,kafka都会持久化一定时间(可配置)
在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。 比如复位到老的offset来重新处理
每个分区代表一个并行单元
Partition
partition由两部分组成:
index log:定位存储索引信息
message log:真实数据
Message
message(消息)是通信的基本单位,每个producer可以向一个topic(主题) 发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给 这些consumer
message format:
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
Producer
生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到 哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分区)
生产者直接把消息发送给对应分区的broker,而不需要任何路由层
批处理发送,当message积累到一定数量或等待一定时间后进行发送
Producer分为同步模式和异步模式
producer.type指定
sync:同步模式(实时)
async:异步模式(达到设定发送条件:时间、数据量)
Consumer
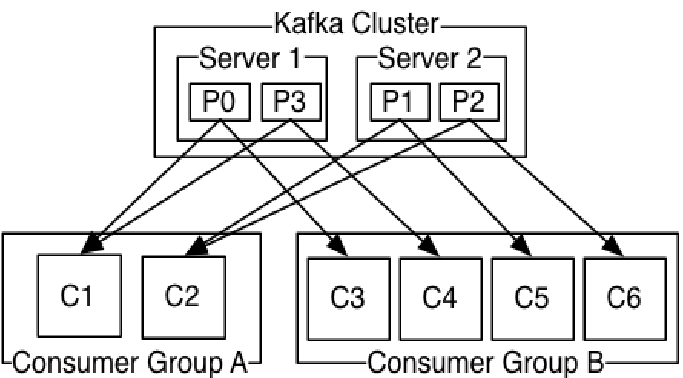
一种更抽象的消费方式:消费组(consumer group)
该方式包含了传统的queue和发布订阅方式
首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式
如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式
消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)
相对于传统的消息系统,kafka拥有更强壮的顺序保证
由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡
kafka core
持久性
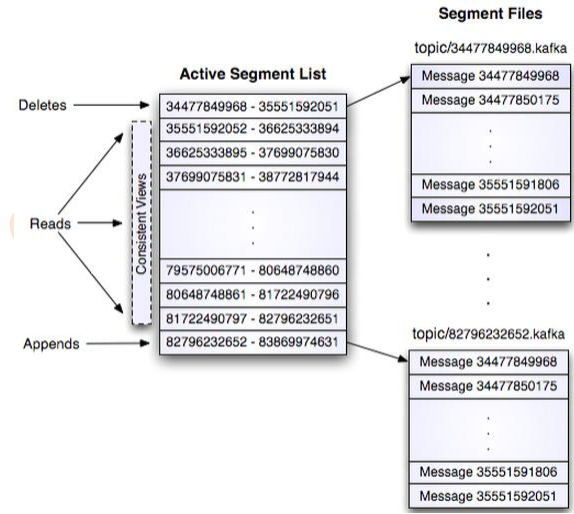
Kafka存储布局简单:Topic的每个Partition对应一个逻辑日志
每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件中
与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息Id
消息通过日志中的逻辑偏移量来公开
传输效率
生产者提交一批消息作为一个请求。消费者虽然利用api遍历消息是一个一个的 ,但背后也是一次请求获取一批数据,从而减少网络请求数量
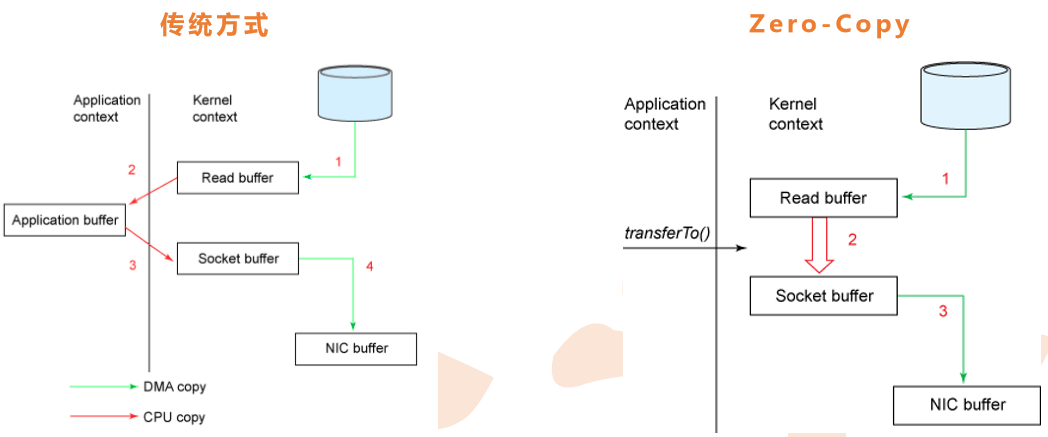
Kafka层采用无缓存设计,而是依赖于底层的文件系统页缓存。这有助于避免双 重缓存,及即消息只缓存了一份在页缓存中。同时这在kafka重启后保持缓存 warm也有额外的优势。因kafka根本不缓存消息在进程中,故gc开销也就很小
zero-copy:kafka为了减少字节拷贝(减少kernel和user模式上下文的切换,直接把disk上data传输给socket,而不是通过应用程序传输),采用了大多数系统都会提供的sendfile系统调用
无状态的Broker
Kafka代理是无状态的:意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,代理完全不管。这种设计非常微妙,它本身包含了创新
从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新 性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超 过一定时间后,将会被自动删除
这种创新设计有很大的好处,消费者可以故意倒回到老的偏移量再次消费数据。这违反了队 列的常见约定,但被证明是许多消费者的基本特征
交付保证
Kafka默认采用at least once的消息投递策略。即在消费者端的处理顺序是获得 消息->处理消息->保存位置。这可能导致一旦客户端挂掉,新的客户端接管时处理前面客户端已处理过的消息
Kafka使用基于时间的SLA的保留策略,消息超过一定时间后,会被自动删除
三种保证策略:
At most once 消息可能会丢,但绝不会重复传输
At least one 消息绝不会丢,但可能会重复传输
Exactly once 每条消息肯定会被传输一次且仅传输一次(最理想),但kafka不支持,目前只能靠客户端维护
Offset是由谁来维护的?(zookeeper维护,变由topic维护,建议客户端来维护)
副本管理
kafka将日志复制到指定多个服务器上
复本的单元是partition 。在正常情况下,每个分区有一个leader和0到多个follower
leader处理对应分区上所有的读写请求。分区可以多于broker数,leader也是分 布式的
follower的日志和leader的日志是相同的, follower被动的复制leader。如果 leader挂了,其中一个follower会自动变成新的leader

和其他分布式系统一样,节点“活着” 定义在于我们能否处理一些失败情况。 kafka需要两个条件保证是“活着”
节点在zookeeper注册的session还在且可维护(基于zookeeper心跳机制)
如果是slave则能够紧随leader的更新不至于落得太远
kafka采用in sync来代替“活着”
如果follower挂掉或卡住或落得很远,则leader会移除同步列表中的in sync。至于落了多远 才叫远由replica.lag.max.messages配置,而表示复本“卡住”由replica.lag.time.max.ms 配置
所谓一条消息是“提交”的,意味着所有in sync的复本也持久化到了他们的log 中。这意味着消费者无需担心leader挂掉导致数据丢失。另一方面,生产者可以选择是否等待消息“提交”
kafka动态的维护了一组in-sync(ISR)的复本,表示已追上了leader,只有处于该状态的成员组才是能被选择为leader。这些ISR组会在发生变化时被持久化到 zookeeper中。通过ISR模型和f+1复本,可以让kafka的topic支持最多f个节点 挂掉而不会导致提交的数据丢失。
分布式协调
由于kafka中一个topic中的不同分区只能被消费组中的一个消费者消费,就避免 了多个消费者消费相同的分区时会导致额外的开销(如要协调哪个消费者消费哪 个消息,还有锁及状态的开销)。kafka中消费进程只需要在代理和同组消费者 有变化时时进行一次协调(这种协调不是经常性的,故可以忽略开销)
kafka使用zookeeper做以下事情:
探测broker和consumer的添加或移除
当1发生时触发每个消费者进程的重新负载
维护消费关系和追踪消费者在分区消费的消息的offset
Zookeeper的使用
Broker Node Registry
/brokers/ids/[0...N] --> host:port (ephemeral node)
broker启动时在/brokers/ids下创建一个znode,把broker id写进去
因为broker把自己注册到zookeeper中实用的是瞬时节点,所以这个注册是动态的,如果 broker宕机或者没有响应该节点就会被删除
Broker Topic Registry
/brokers/topics/[topic]/[0...N] --> nPartions (ephemeral node)
每个broker把自己存储和维护的partion信息注册到该路径下
Consumers and Consumer Groups
consumers也把它们自己注册到zookeeper上,用以保持消费负载平衡和offset记录。
group id相同的多个consumer构成一个消费租,共同消费一个topic,同一个组的 consumer会尽量均匀的消费,其中的一个consumer只会消费一个partion的数据。
Consumer Id Registry
/consumers/[group_id]/ids/[consumer_id] --> {"topic1": #streams, ..., "topicN": #streams} (ephemeral node)
每个consumer在/consumers/[group_id]/ids下创建一个瞬时的唯一的consumer_id,用来 描述当前该group下有哪些consumer是alive的,如果消费进程挂掉对应的consumer_id就 会从该节点删除
Consumer Offset Tracking
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value ((persistent node)
consumer把每个partition的消费offset记录保存在该节点下
Partition Owner registry
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] --> consumer_node_id (ephemeral node)
该节点维护着partion与consumer之间的对应关系。
初始kafka的更多相关文章
- 初始 Kafka Consumer 消费者
温馨提示:整个 Kafka 专栏基于 kafka-2.2.1 版本. 1.KafkaConsumer 概述 根据 KafkaConsumer 类上的注释上来看 KafkaConsumer 具有如下特征 ...
- 精选干货 在java中创建kafka
这个详细的教程将帮助你创建一个简单的Kafka生产者,该生产者可将记录发布到Kafka集群. 通过优锐课的java学习架构分享中,在本教程中,我们将创建一个简单的Java示例,该示例创建一个Kafka ...
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html 目录: 5.1文件目录布局 5.2消息压缩 5.3日志索引 5.4日志文件及索引文件分 ...
- 【Kafka专栏】-Kafka从初始到搭建到应用
一.前述 Kafka是一个分布式的消息队列系统(Message Queue). kafka集群有多个Broker服务器组成,每个类型的消息被定义为topic. 同一topic内部的消息按照一定的key ...
- Kafka副本管理—— 为何去掉replica.lag.max.messages参数
今天查看Kafka 0.10.0的官方文档,发现了这样一句话:Configuration parameter replica.lag.max.messages was removed. Partiti ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
随机推荐
- 性能(js)
1.避免全局查找: <script type="text/javascript"> function updateUI(){ var imgs=document.get ...
- Maven的conf目录下settings.xml的简单配置
省略一些其他配置 <?xml version="1.0" encoding="UTF-8"?> <settings xmlns="h ...
- MAC/Xcode简单操作命令
快捷键: command(windows) + c: 复制 command + V : 粘贴 command + x: 剪切(只在当前应用程序内有效) 在mac系统下表示剪切功能: 先command ...
- BZOJ 1969 航线规划 - LCT 维护边双联通分量
Solution 实际上就是查询 $u$ 到 $v$ 路径上 边双的个数 $ -1$. 并且题目仅有删边, 那么就离线倒序添边. 维护 边双 略有不同: 首先需要一个并查集, 记录 边双内的点. 在 ...
- spring.boot mybaits集成
https://www.cnblogs.com/pejsidney/p/9272562.html (insertBatch批量插入) 第一篇博客循环部分有错误,参照下面的例子去更改 List<S ...
- 解决ubuntu常见问题
cd /usr/local/hadoop 1. bash: cd: ~:Permission denied 报错:bash: cd: /usr/local/hadoop:Permission deni ...
- 2017/2/13:springMVC拦截器的使用
一.定义Interceptor实现类(主要是实现Handlerceptor接口) SpringMVC 中的Interceptor 拦截请求是通过HandlerInterceptor 来实现的.在Spr ...
- day05作业---字典
# 字典找位置 用键, 列表.元组找位置 用索引'''1.有如下变量(tu是个元祖),请实现要求的功能tu = ("alex", [11, 22, {"k1": ...
- 2019.01.21 洛谷P3919 【模板】可持久化数组(主席树)
传送门 题意简述:支持在某个历史版本上修改某一个位置上的值,访问某个历史版本上的某一位置的值. 思路: 用主席树直接维护历史版本即可. 代码: #include<bits/stdc++.h> ...
- centos7 配置ip
1. 切换到root用户下: su root 2.进入network-scripts目录: cd /etc/sysconfig/network-scripts/ 3.该目录下一般第一个文件是主文件,我 ...